类装载器就是寻找类的字节码文件,并构造出类在JVM内部表示的对象组件。在Java中,类装载器把一个类装入JVM中,要经过以下步骤:
(1) 装载:查找和导入Class文件;
(2) 链接:把类的二进制数据合并到JRE中;
(a)校验:检查载入Class文件数据的正确性;
(b)准备:给类的静态变量分配存储空间;
(c)解析:将符号引用转成直接引用;
(3) 初始化:对类的静态变量,静态代码块执行初始化操作
按照Java虚拟机规范的规定,JVM自动管理的内存将会包括以下几个运行时数据区域。

方法区
方法区(Method Area)是用于存储类结构信息的地方,包括常量池、静态变量、构造函数等类型信息,类型信息是由类加载器在类加载时从类文件中提取出来的。
方法区同样存在垃圾收集,因为用户通过自定义加载器加载的一些类同样会成为垃圾,JVM会回收一个未被引用类所占的空间,以使方法区的空间达到最小。
方法区中还存在着常量池,常量池包含着一些常量和符号引用(加载类的连接阶段中的解析过程会将符号引用转换为直接引用)。
方法区是线程共享的。
堆
堆(heap)是存储java实例或者对象的地方,是GC的主要区域,同样是线程共享的内存区域。
栈
栈中包含两个部分 虚拟机栈和本地方法栈
每个线程都拥有一个栈空间,在调用方法的时候产生一个栈帧(存放局部变量)
本地方法栈(Native Method Stack)和虚拟机栈的作用相似,不过虚拟机栈是为Java方法服务的,而本地方法栈是为Native方法服务的。
四种引用类型的概念
Java 中有四种引用:强引用、软引用、弱引用、虚引用; 其主要区别在于垃圾回收时是否进行回收:
强引用 StrongReference
如果一个对象具有强引用,那么垃圾回收器绝对不会回收它,当内存不足时宁愿抛出 OOM 错误,使得程序异常停止。
Object object = new Object(); 即是一个强引用。
软引用 SoftReference
如果一个对象只具有软引用,那么垃圾回收器在内存充足的时候不会回收它,而在内存不足时会回收这些对象。软引用对象被回收后,Java 虚拟机会把这个软引用加入到与之关联的引用队列中。
弱引用 WeakReference
如果一个对象只具有弱引用,那么垃圾回收器在扫描到该对象时,无论内存充足与否,都会回收该对象的内存。与软引用相同,弱引用对象被回收后,Java 虚拟机会把这个弱引用加入到与之关联的引用队列中。
虚引用 PhantomReference
虚引用并不决定对象生命周期,如果一个对象只具有虚引用,那么它和没有任何引用一样,任何时候都可能被回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动。与软引用和弱引用不同的是,虚引用必须关联一个引用队列。
当垃圾回收器准备回收一个对象之前,如果发现它还具有虚引用,就会在对象回收前把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否加入了虚引用,来了解被引用的对象是否将要被回收,那么就可以在其被回收之前采取必要的行动。
垃圾回收算法
如何确定是垃圾:
1.引用计数:有一个引用指向该对象就加一,什么时候值为0了,它就是垃圾。这种方法是不可行了,会有循环引用的问题
2.正向可达:从roots对象开始,计算追踪可以到达的对象,那么不可到达的对象就被视为垃圾。
1 标记-清除算法(Mark-Sweep)
最基础的垃圾回收算法,分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。如图:
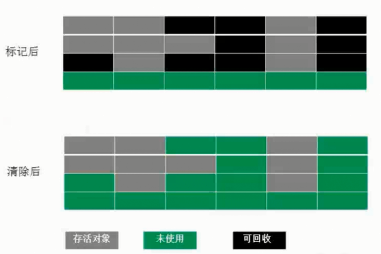
从图中我们就可以发现,该算法最大的问题是内存碎片化严重,后续可能发生大对象不能找到可利用空间的问题。
2 复制算法(Copying)
为了解决Mark-Sweep算法内存碎片化的缺陷而被提出的算法。按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉,如图:
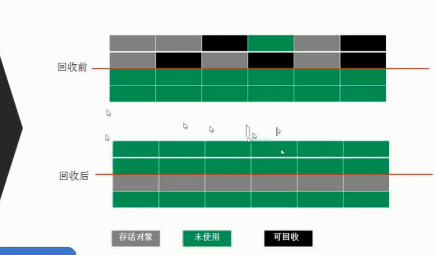
这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是可用内存被压缩到了原本的一半。且存活对象增多的话,Copying算法的效率会大大降低。内存浪费
3 标记-整理算法(Mark-Compact)
结合了以上两个算法,为了避免缺陷而提出。标记阶段和Mark-Sweep算法相同,标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。如图:
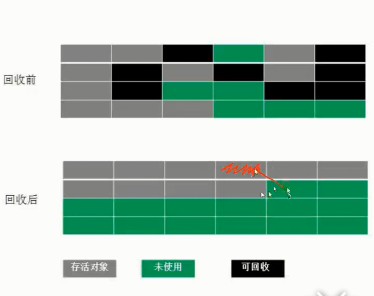
用在老年代中,效率相比coping有所下降
4. 分代收集算法(Generational Collection)
分代收集法是目前大部分JVM所采用的方法,其核心思想是根据对象存活的不同生命周期将内存划分为不同的域,一般情况下将GC堆划分为老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特点是每次垃圾回收时只有少量对象需要被回收,新生代的特点是每次垃圾回收时都有大量垃圾需要被回收,因此可以根据不同区域选择不同的算法。
一般情况 新生代 存活对象少 采用Copping算法
老年代 垃圾较少 采用标记-整理算法(Mark-Compact)
典型的垃圾收集器
垃圾收集算法是垃圾收集器的理论基础,而垃圾收集器就是其具体实现。下面介绍HotSpot虚拟机提供的几种垃圾收集器。
1. Serial/Serial Old
最古老的收集器,是一个单线程收集器,用它进行垃圾回收时,必须暂停所有用户线程。Serial是针对新生代的收集器,采用Copying算法;而Serial Old是针对老生代的收集器,采用Mark-Compact算法。优点是简单高效,缺点是需要暂停用户线程。
2. ParNew
Seral/Serial Old的多线程版本,使用多个线程进行垃圾收集。
3. Parallel Scavenge
新生代的并行收集器,回收期间不需要暂停其他线程,采用Copying算法。该收集器与前两个收集器不同,主要为了达到一个可控的吞吐量。
4. Parallel Old
Parallel Scavenge的老生代版本,采用Mark-Compact算法和多线程。
5. CMS
Current Mark Sweep收集器是一种以最小回收时间停顿为目标的并发回收器,因而采用Mark-Sweep算法。
6. G1
G1(Garbage First)收集器技术的前沿成果,是面向服务端的收集器,能充分利用CPU和多核环境。是一款并行与并发收集器,它能够建立可预测的停顿时间模型。
并发(concurrency)和并行(parallellism)是:
- 解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
- 解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
- 解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群
常见配置汇总
- 堆设置
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
- -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
- -XX:MaxPermSize=n:设置持久代大小
- 收集器设置
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
- 垃圾回收统计信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
- 并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
- -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
- 并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
- -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。