wordcount作为Hadoop的示例程序,其思想很简洁,但也值得去理解
尤其是作为Hadoop菜鸟的我
wordcount程序如下:
package com.lcy.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/*
* 建立Mapper类TokenizerMapper继承自泛类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口,实现WritableComparable的类可以相互比较,
* 所有被用作key的类都应该实现此接口
* Reporter用于报告整个应用的运行进度,本例未使用
*/
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable>{
/*
* IntWritable,Text均为Hadoop中实现的用于封装java数据类型的类,这些类实现了WritableComparable
* 接口,都能够被串行化从而能够在分布式环境中进行数据交换,可以把它们分别当作是Int和String的
* 替代
*/
/*
* 声明常量one
* 声明单词存放单词
*/
private final static IntWritable one=new IntWritable(1);
private Text word=new Text();
/*
* Mapper中的map方法
* void map(K1 key,V1 value,Context context)
* 映射一个单个的k/v对到一个中间的k/v对
* 输出对不需要是和输入对相同的类型,输入对何以映射到0个或者多个输出对
* Context:收集Mapper输出的<k,v>对
* Context的write(k,v)方法:增加一个(k,v)对到context
* 程序主要是编写Map和Reduce函数,Map函数使用StringTokenizer函数对字符串进行分隔,通过set
* 方法把单词存入word中,write方法存入(单词,1)这样的二元组到context中
*/
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer itr=new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result=new IntWritable();
/*
* Reducer中的reduce方法:
* void reduce(Text key,Iterable<IntWritable> values,Context context)
* 中k/v来自map函数中的context,可能经过了进一步的处理(combiner)
* 同样通过context输出
*/
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum=0;
for(IntWritable val : values){
sum+=val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
/*
* Configuration:map/reduce的配置类,向hadoop框架描述map-reduce的工作
*/
Configuration conf=new Configuration();
String [] otherArgs=new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job=new Job(conf,"wordcount"); //设定一个用户定义的Job名称
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //为job设置输出路径
System.exit(job.waitForCompletion(true)?0:1); //运行job
}
}
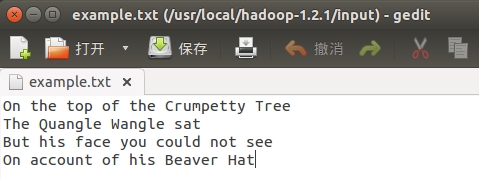
要提交至HDFS的输入文件example.txt内容如下:
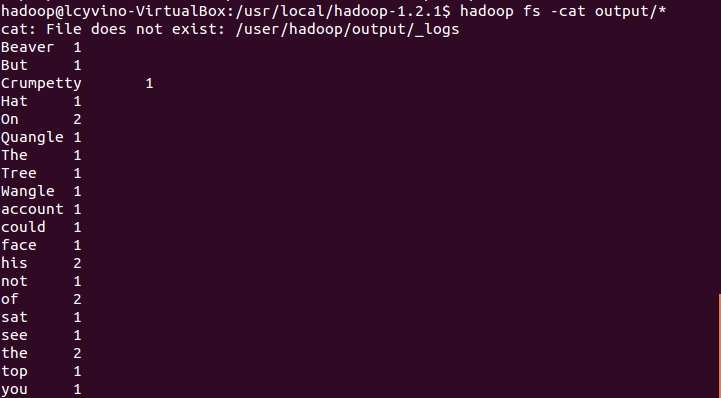
运行示例:

直接在HDFS查看输出结果: