PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1245 | 1360 |
| · Analysis | · 需求分析 (包括学习新技术) | 2h * 60 | 3h * 60 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 10h * 60 | 10h * 60 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 6h * 60 | 8h * 60 |
| Reporting | 报告 | 70 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1315 | 1430 |
项目要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
编程思路
首先,统计字符是基本的文件操作,我选择每次读取一个字符,这也便于随后操作。单词数的主要问题是对单词的判断,因为题目还给出了各种条件,而单词的数量又相当多,所以代码要写的简介,尽量不要调用函数。行数可以通过读取的换行符数目来判断。统计词频的难点在于找到合适的结构存储,插入和查找要快,也要便于后续排序。词频的统计,涉及到两个词的关联,要选择合适的数据结构存储。一开始根据我在网上查找的资料,字典树似乎是对于词频统计应用的一个比较好的选择,所以我首先尝试自己实现了一个字典树的结构,并成功存储单词,但后续发现字典树在读取和排序方面并无优势,而又很难表示出词组的结构。那么另一种方法就是hash存储,可以有很快的存储读取速度,同时也方便表示词组。查阅资料,C++有unordered_map的标准模板库,内部是通过hsah函数存储的,考虑到自己写的话不一定能找到合适的hash,正确使用下,STL不比自己实现要慢,所以选择使用unordered_map。那么接下来的问题是Key和Value分别是什么。
定义如下结构
1 typedef struct 2 { 3 string value; 4 int appearNum = 0; 5 }wordInfo;//描述词的带后缀值和出现次数 6 7 typedef struct 8 { 9 string Aword; 10 string Bword; 11 int appearNum = 0; 12 }phraselink;//描述A词和B词的词组关系 13 14 15 typedef unordered_map<string, wordInfo> wMap;//字的字典 16 typedef unordered_map<string, phraselink> npMap;//词组字典
对于词,我使用无后缀的小写词作为Map的Key,对应一个包括带后缀有大小写的value以及出现次数的结构体。
对于词组,用两个单词连接成的string作为Key,对应词组单词和出现次数。
实现结构
一.总体结构
1.通过命令行读取参数,遍历文件夹中的文件
2.记录字符数,行数,单词数,判断单词,存储单词和词组
3.排序获得频率前十的单词,词组,输出文件
二.实现函数
| 函数 | 输入 | 返回值 | 功能 |
| GetAllFiles | string path, vector<string>& files, string format | void | 遍历path文件夹,将路径存在files中 |
| isWord | string word | bool | 根据任务规定,判断是否是单词 |
| addWord | string &word, string &word_pre, string &word_r, string &word_pre_r | bool | 输入map的key值,以及没有简化的原始字符串,存入map中 |
| sortWords | wMap wordsDic(全局) | bool | 获得map中频率最大的单词 |
| sortPhrases | npMap phraseDic(全局) | bool | 获得map中频率最大的词组 |
| mian | int argc, char** argv | int | d读取字符,执行基本处理,输出文件 |
三.具体代码
addWord是最主要也是占用时间最长的函数,代码如下
void addWord(string &word, string &word_pre, string &word_r, string &word_pre_r) { int wordlen = word.length() - 1; int pfixlen = 0; string postfix, phraseKey; wMap::iterator tempit; for (int i = wordlen;; i--) { if (word[i]<'0' || word[i]>'9') { pfixlen = wordlen - i; //获得数字后缀长度 break; } } postfix = word.substr(wordlen - pfixlen); word = word.substr(0, wordlen - pfixlen);//从小写的word得到wordKey wordsDic[word].appearNum++;//生成单词map if (wordsDic[word].value.empty() || wordsDic[word].value>word_r)//选择字典序最小的字符串记录 wordsDic[word].value = word_r;//记录真实值 if (!word.empty() && !word_pre.empty()) { phraseKey = word_pre; phraseKey.push_back('-'); phraseKey += word;//得到phraseKey phraseDic[phraseKey].appearNum++;//生成词组Map if (phraseDic[phraseKey].Aword.empty())//选择字典序最小的短语记录 { phraseDic[phraseKey].Aword = word_pre_r; phraseDic[phraseKey].Bword = word_r; } else if (phraseDic[phraseKey].Bword > word_r) phraseDic[phraseKey].Bword = word_r; else if (phraseDic[phraseKey].Aword > word_pre_r) phraseDic[phraseKey].Aword = word_pre_r; } }
样例输出结果
characters:173669785 words:16630571 lines:2278666 <THAT>:259186 <SAID>:208861 <CLASS>:192004 <HARRY>:184732 <WITH>:158745 <THIS>:152454 <THEY>:145945 <Span>:116118 <HAVE>:107383 <FROM>:105494 <Span-CLASS>:62861 <THAT-GOOD>:61427 <Span-Span>:41286 <CLASS-Reference>:31289 <INTERNAL-href>:26668 <Reference-INTERNAL>:26668 <SAID-HARRY>:24981 <CLASS-Span>:23146 <href-LEAP>:22569 <SAID-HERMIONE>:19193
输出结果除了字符数和单词数外,和助教结果一致。
测试优化
单元测试
这次实践中,我学习使用了Virtual Studio的性能探查器,并对代码进行了多方面的优化,前后改观十分明显。
测试环境:
VS2017,Release模式,CPU:i5-6200U

这是我完成规定内全部内容时尚未优化的运行时间。
以下是主要的优化操作
1.
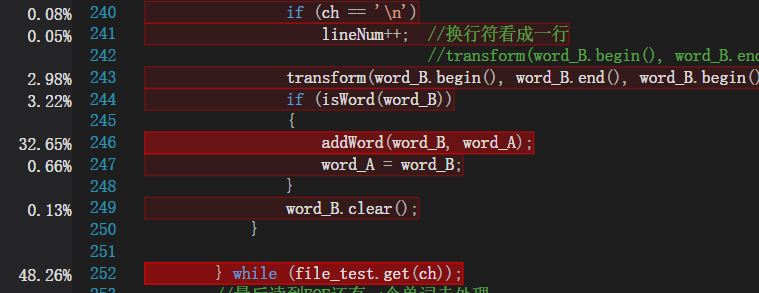
明显可以看出,使用get()读取字符的操作,花费了近一半的时间,甚至超过了主要的插入单词操作。查阅资料,最快的读取方式时使用底层的fread函数,
更换读取方式后,再次进行性能分析。

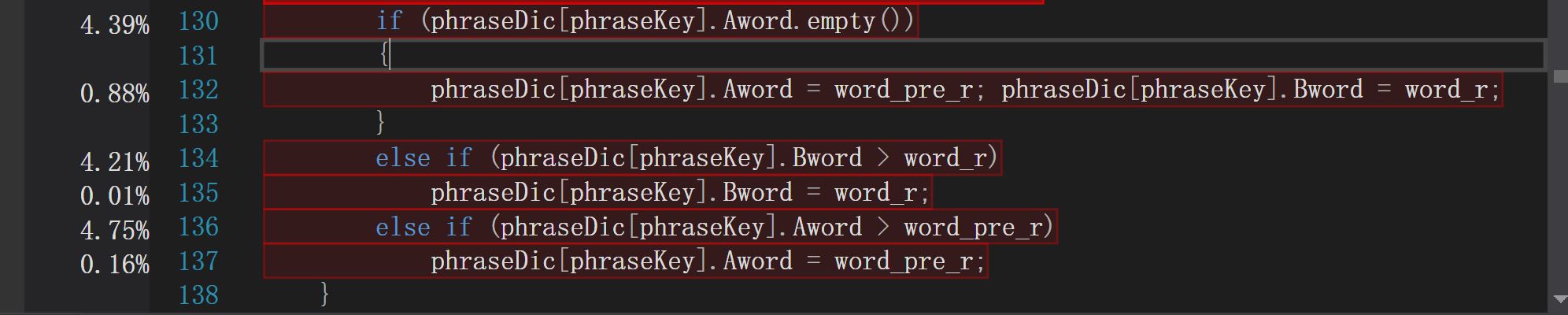
2.

上图可以看出,判断插入词组时是否空字符串以及判断字典序使用了两个if语句,花费了总时间的大约16%,这显然是不合适的。显然对于我们的应用场景,词组的重复频率相对于词组总数十分小,且两个单词一个为空,另一个必然也是空,所以我们可以更改判断的顺序提升运行效率。
3.
另外还有一些基本的优化,减少调用次数,使用基本类型等。比如程序中需要对单词执行转化小写的操作,一开始选择使用库函数transform,但是占用时间按过长,改为在读取字符判断ascii时,执行ascii的加操作,将转化小写合并到读取判断字符中。
优化之后的运行时间如下,效果比较明显

linux上的性能分析
为了将代码移植到linux,需要更换读取文件的方法,这里使用dirent.h头文件,实现移植Github代码
在linux上进行性能分析有很多工具,我选择使用比较常见,使用也十分简单的GPROF,具体内容主要参考https://www.thegeekstuff.com/2012/08/gprof-tutorial/
使用该工具可以得到一份性能报告,以下是一些节选

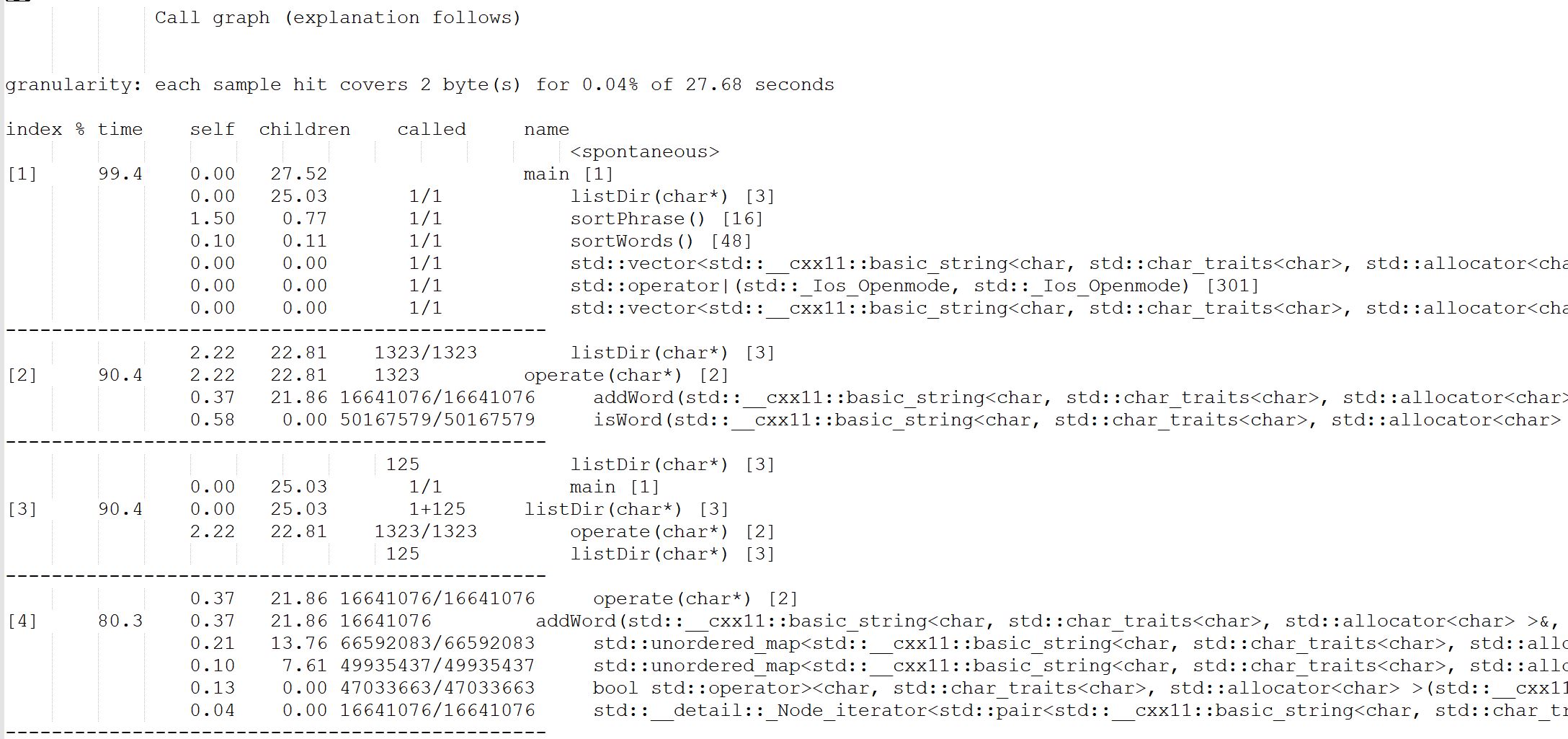
主要说明如下
% the percentage of the total running time of the time program used by this function. cumulative a running sum of the number of seconds accounted seconds for by this function and those listed above it. self the number of seconds accounted for by this seconds function alone. This is the major sort for this listing. calls the number of times this function was invoked, if this function is profiled, else blank. self the average number of milliseconds spent in this ms/call function per call, if this function is profiled, else blank. total the average number of milliseconds spent in this ms/call function and its descendents per call, if this function is profiled, else blank. name the name of the function. This is the minor sort for this listing. The index shows the location of the function in the gprof listing. If the index is in parenthesis it shows where it would appear in the gprof listing if it were to be printed.
这和我们在Windows下使用VS的结果基本一致。
具体文件可以在Github找到。