到底什么是Stream流?
什么是Stream?
(~~~~~~~~)我们先来看看Java里面是怎么定义Stream的:
A sequence of elements supporting sequential and parallel aggregate operations.
语翻译过来就是:支持数据处理操作的一个source(资源?) 中的元素序列
(~~~~~~~~)让我们解析一下上面的翻译:
List<Person> listPerson = new ArrayList<Person>() {
{
//元素序列-----翻译过来就是集合中的所有元素对象
add(new Person("Elsdon", "Jaycob", "Java programmer", "male", 2000, 18));
add(new Person("Tamsen", "Brittany", "Java programmer", "female", 2371, 55));
add(new Person("Floyd", "Donny", "Java programmer", "male", 3322, 25));
add(new Person("Sindy", "Jonie", "Java programmer", "female", 35020, 15));
add(new Person("Vere", "Hervey", "Java programmer", "male", 2272, 25));
add(new Person("Maude", "Jaimie", "Java programmer", "female", 2057, 87));
add(new Person("Shawn", "Randall", "Java programmer", "male", 3120, 99));
add(new Person("Jayden", "Corrina", "Java programmer", "female", 345, 25));
add(new Person("Palmer", "Dene", "Java programmer", "male", 3375, 14));
add(new Person("Addison", "Pam", "Java programmer", "female", 3426, 20));
}
};
//获取集合中年龄大于三十的人的名字,返回集合
listPerson.stream().filter(e->e.getAge()>30).map(e->e.getFirstName()).collect(Collectors.toList());
Sequence of elements(元素序列):简单来说,就是我们操作的集合中的所有元素source(数据源):Stream流的作用就是操作数据,那么source 就是为Stream提供可操作的源数据(一般,集合、数组或I/OI/O resources 都可以成为Stream的source )Data processing operations(数据处理操作):上面菜单程序代码中出现的filter、sorted、map、collect,以及我们后来会用到的reduce、find、match`等都属于Stream 的一些操作数据的方法接口。这些操作可以顺序进行,也可以并行执行。Pipelining(管道、流水线):Stream对数据的操作类似数据库查询,也像电子厂的生产流线一样,Stream的每一个中间操作(后面解释什么是中间操作)比如上面的filter、sorted、map,每一步都会返回一个新的流,这些操作全部连起来就是想是一个工厂得生产流水线, like this:
Internal iteration(内部迭代):Stream API 实现了对数据迭代的封装,不用你再像操作集合一样,手动写for循环显示迭代数据。

总结:Java8 中添加了一个新的接口类 Stream,相当于高级版的 Iterator,通过Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
为什么使用Stream?
(~~~~~~~~)知道什么是Stream流,紧跟而来的就是我们为什么要使用Stream,换句话来说就是使用Stream有什么好处?
(~~~~~~~~)在《java8 in action》书中,作者说目前我们在几乎所有开发中都会用到集合,但是目前集合在程序开发中的表现还不够完美,比如你利用集合处理大量数据时,你不得不面对性能问题,不得不考虑进行并行代码的编写,这些工作都是比较繁重的,于是作者便创造了Stream 流。相比较Collection集合来说,Stream在开发中就具有许多独特的优点,这些优点你可以先不用理解,知道就行,我们会在下面的案例代码中直观感受到:
- 以声明式的方式处理数据集合——更简洁,更易读
- 可复合——更灵活
- 可并行——无需写任何多线程代码,Stream API自动处理这些问题,性能更好
接下来我们来一个入门级的测试示例:
//Lists是Guava中的一个工具类
List<Integer> numberlist = Lists.newArrayList(1,null,3,4,null,6);
numberlist.stream().filter(num -> num != null).count();
根据我们的测试代码,我们通过Stream获取集合中不为null的元素个数,示例简单只有一个操作。
根据测试示例详细剖析Stream的通用语法:
@Test
public void test(){
//Lists是Guava中的一个工具类
List<Integer> numberlist = Lists.newArrayList(1,null,3,4,null,6);
numberlist.stream().filter(num -> num != null).count();
/**
* 1.通过.Stream()创建Stream实例----------创建Stream
* 2.通过.filter()中间操作,根据内部迭代对list集合中的每一个元素判断是否为null---------转换Stream
* 3.通过。count()方法统计数量------------聚合
*/
}
通过对代码的分析,总结,Stream最主要的三组成部分:
(~~~~~~~~) 1. 创建流,也就是Stream开始的地方,负责创建一个Stream实例
(~~~~~~~~) 2. 中间操作,主要是一些对数据的过滤筛选,添加删除等等操作,形成一个流程链。
(~~~~~~~~) 3. 收尾,也就是终端操作,我感觉更适合叫终结操作,终端操作会从流的流水线(中间操作)生成结果
Stream三大部分
(~~~~~~~~)通过对测试示例的解析,总结了stream的通用语法,总共包括三大部分,下面我们更加深入了解这三大部分:
(~~~~~~~~)还是文章开头的示例:
List<Person> listPerson = new ArrayList<Person>() {
{
//元素序列-----翻译过来就是集合中的所有元素对象
add(new Person("Elsdon", "Jaycob", "Java programmer", "male", 2000, 18));
add(new Person("Tamsen", "Brittany", "Java programmer", "female", 2371, 55));
add(new Person("Floyd", "Donny", "Java programmer", "male", 3322, 25));
add(new Person("Sindy", "Jonie", "Java programmer", "female", 35020, 15));
add(new Person("Vere", "Hervey", "Java programmer", "male", 2272, 25));
add(new Person("Maude", "Jaimie", "Java programmer", "female", 2057, 87));
add(new Person("Shawn", "Randall", "Java programmer", "male", 3120, 99));
add(new Person("Jayden", "Corrina", "Java programmer", "female", 345, 25));
add(new Person("Palmer", "Dene", "Java programmer", "male", 3375, 14));
add(new Person("Addison", "Pam", "Java programmer", "female", 3426, 20));
}
};
//获取集合中年龄大于三十的人的名字,返回集合
listPerson
.stream()//创建Stream实例
.filter(e->e.getAge()>30).map(e->e.getFirstName())//中间操作
.collect(Collectors.toList());//终端操作
创建Stream实例
通过集合、数组等都可以创建Stream流实例,博客上有做详细的讲解【Stream初步认识(一)】,这里就不详细说了。
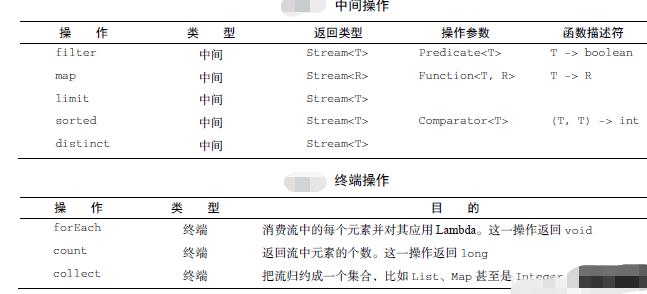
中间操作
可以连接起来的Stream流操作,诸如filter或sorted等可以返回一个Stream 流的操作,就叫中间操作。只有存在一个终端操作,且触发了终端操作,中间操作才会开始执行。
在上面的测试方法中,创建完实例之后我们,连续调用filter()以及map()方法,我们先看一下他们的源码:
//filter源码
Stream<T> filter(Predicate<? super T> predicate);
//map源码
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
调用filter()以及map()方法,都会返回stream流,这也是形成链式调用的主要原因。
(虽然filter和map是两个独立的中间操作,但它们合并到同一次遍历中执行,这就叫作循环合并。)
终端操作
可以启动中间操作和关闭中间流的操作称为终端操作,终端操作会从流的流水线(中间操作)生成结果。其结果是任何非Stream的值,比如可能是List、Integer,甚至void。
而在我们的测试示例中,我们返回的就是集合
//获取集合中年龄大于三十的人的名字,返回集合
List<String> reList = listPerson
.stream()//创建Stream实例
.filter(e -> e.getAge() > 30).map(e -> e.getFirstName())//中间操作
.collect(Collectors.toList());//终端操作
Stream流的生命周期
(~~~~~~~~)同一个流只能遍历一次,遍历完后,这个流就已经被消费掉了。你如果还需要在遍历,可以从原始数据源那里再获得一个新的流来重新遍历一遍。
比如:
List<Person> listPerson = new ArrayList<Person>() {
{
//元素序列-----翻译过来就是集合中的所有元素对象
add(new Person("Elsdon", "Jaycob", "Java programmer", "male", 2000, 18));
add(new Person("Tamsen", "Brittany", "Java programmer", "female", 2371, 55));
add(new Person("Floyd", "Donny", "Java programmer", "male", 3322, 25));
add(new Person("Sindy", "Jonie", "Java programmer", "female", 35020, 15));
add(new Person("Vere", "Hervey", "Java programmer", "male", 2272, 25));
add(new Person("Maude", "Jaimie", "Java programmer", "female", 2057, 87));
add(new Person("Shawn", "Randall", "Java programmer", "male", 3120, 99));
add(new Person("Jayden", "Corrina", "Java programmer", "female", 345, 25));
add(new Person("Palmer", "Dene", "Java programmer", "male", 3375, 14));
add(new Person("Addison", "Pam", "Java programmer", "female", 3426, 20));
}
};
//获取集合中年龄大于三十的人的名字,返回集合
List<String> reList = listPerson
.stream()//创建Stream实例
.filter(e -> e.getAge() > 30).map(e -> e.getFirstName())//中间操作
.collect(Collectors.toList());//终端操作
Stream<Person> stream1 = listPerson.stream();
stream1.forEach(System.out::print);
stream1.forEach(System.out::print);
打印结果:

同一个流 s 被两次用于forEach的终端操作,此时控制台报错,提示Stream流已被操作或者关闭。
但是当我们从原始数据源集合中那里再获得一个新的流在操作就可以:
//获取集合中年龄大于三十的人的名字,返回集合
List<String> reList = listPerson
.stream()//创建Stream实例
.filter(e -> e.getAge() > 30).map(e -> e.getFirstName())//中间操作
.collect(Collectors.toList());//终端操作
Stream<Person> stream1 = listPerson.stream();
stream1.forEach(System.out::print);
Stream<Person> stream2 = listPerson.stream();
stream2.forEach(System.out::print);
小结
1、流的使用一般包括三件事:
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
2、Stream API提供的一些常用操作接口: