前戏:在python中把数据序列分为可变(mutable)和不可变(immutable)两种
不可变:string、int、float、tuple
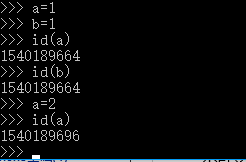
特点:相同对象只是占用一个内存地址,不管有多少个变量引用它,例如a=1,b=1
由于是不可变的,每次必须创建新的对象,之前不用的对象如果没有引用指向它,Python垃圾回收机制会自动清理掉
可变:list、dict
特点:相同对象,每次引用它都会在内存中开辟一块新地址来保存它,但是当我们对他的值进行操作时,内存地址是不会发生变化的
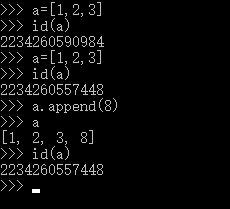
总结:python中不可变数据类型一旦对变量的值进行改变,相当于重新建立一个对象,所以内存地址也会发生改变;
可变数据类型变量的值是可以改变的不会引起内存地址的变化,但是如果值被多个变量引用的话,每个变量都会开辟一块地址
一、字符串(string)
1、str的切片
1 name="hello word,abcdefgWX!!!"
str[::]读取操作
2 print(name[0],name[1])
capitalize(self)方法,首字母大写
3 print(name.capitalize())#打印Hello word,wx开头首字母大写,其余小写
casefold(self)大写转小写
4 print(name.casefold())#把字符串大写转成小写
5 # casefold() 方法是Python3.3版本之后引入的,其效果和 lower() 方法非常相似,
6 # 都可以转换字符串中所有大写字符为小写。
7 # 两者的区别是:lower() 方法只对ASCII编码,也就是‘A-Z’有效
8 # 对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用 casefold() 方法。
center(width,"")
9 print(name.center(20,"*"))#把字符串居中,width=20字符串的总宽度 fillchar 填充字符
10 # name.center(self,width,fillchar)
count(sub,start,end)
11 print(name.count("l"))#统计字符串中字符出现的次数,也可以指定位置 默认从0到最后
12 print(name.count("d",0,15))#1count(sub,start,end)
13 print(name[0:15].count("d"))#2
encode("utf-8")字符串转成bytes
14 print(name.encode().decode()) #字符转成字节byte类型
endswith(sub,start,end)、startswith(sub,start,end)
15 print(name.endswith("!!!")) #判断是否以指定字符结尾 返回bool值,也可指定位置判断
16 print(name.endswith("rd",0,10))#end=10 不包括10 到第9位
17 print(name[:10],name[:10].endswith("rd"))
55 print(h.startswith("h")) #判断一指定字符开头
56 print(h.startswith("h",0,2))
expandtabs(tabzise)把字符串中的 tab 符号(' ')转为空格
19 # Python expandtabs() 方法把字符串中的 tab 符号(' ')转为空格,
20 # tab 符号(' ')默认的空格数是 8。
21 name2="abc qwer"
22 print(name2.expandtabs())#默认tabsize=8,从字符串0开始数到 位置补5个空格
23 print(name2.expandtabs(16))
find(self,sub,start,end)查找元素位置,返回索引值,不存在返回-1
25 print(name.find("l")) #查找字符串元素位置,返回索引值,查不到返回-1
26 print(name.find("l",3,5))#指定查找范围
index(sub,start,end)、rindex()
27 print(name.index("l")) #输出索引值
28 print(name.index("o",2,9))#指定范围
27 print(str1.rindex("D",2,11))#从最右边开始找某个字符,输出索引值
isalnum()、isnumeric()
29 a="1223wew"
30 print(a.isalnum()) #判断是否包含数字
41 print(name.isnumeric());#判断是否有纯数字组成
isalpha()
31 b="sadsd"
32 print(b.isalpha())#检查字符串是否为纯字母
isdecimal() 是否为十进制字符
33 c=u"132323"
34 print(c.isdecimal())#是否只是包含十进制字符
35 c2=u"asdd3232"
36 print(c2.isdecimal())
isidentifier()
37 print(name.isidentifier()) #判断字符串是否已字母开头
38 print(a.isdigit() #检查是否为纯数字
find()、rfind()查找元素,output索引值
39 c="adsdsd8989"
40 print(c.find("w"))
26 print(str1.rfind("D",2,11))#从最右边开始找某个字符,输出索引值
isprintable()
42 print(name.isprintable()) #判断是否可打印字符串
istitle()
43 print(name.istitle());#判断字符串是否为一个标题
isupper()、islower()
44 print(name.isupper())#判断字符串是否都是大写
print(name.islower())#判断字符串是否都为小写
isspace()
45 print(name.isspace())#字符串是否只由空格组成
join(),将字符串用指定字符生成新的字符串
1 a=("h","l","l")
2 b="k"
3 c="nihao"
4 print(b.join(c)) #将字符串用指定的字符链接成新的字符串
output"nkikhkako"
5 print(b.join(a))
output"hklkl"
just(width,"")对齐
6 print(c.ljust(20,"_"))#字符串左对齐,指定20宽度,后边以_填充
7 print(c.rjust(20,"-"))
maketrans(oldsub,newsub)、translate(sub)
8 c1=c.maketrans("n","@") #将字符串某个字符用指定元素代替 与translate结合使用
9 print(c.translate(c1)) #解密
output:"@ihao"
upper()转大写、lower()转小写
10 str1="ASADSASDsadsD1"
11 print(str1.lower()) #转成小写
12 print(str1.upper()) #转成大写
partition(sub)指定字符分割,返回一个元组类型
14 # partition() 方法用来根据指定的分隔符将字符串进行分割。
15 # 如果字符串包含指定的分隔符,则返回一个3元的元组,
16 # 第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。
17 print(str1.partition("D"))
output:("ASA","D","SASDsadsD1")
18 print(str1.rpartition("D")) #从右往左找字符串开始分割
output:('ASADSASDsads', 'D', '1')
replace()字符串替换
20 # replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串)
21 # 如果指定第三个参数max,则替换不超过 max 次。
22 # str.replace(old, new[, max])
23 #可以用来改字符串内容
24 print(str1.replace("A",2)) #指定替换成几个,默认全都替换,
tite()转换成标题
28 e="sd dsd 23 dsd "
29 print(e.title())#转换成标题
output:"Sd Dsd 23 Dsd "
split(sub,num)、rsplit()返回一个列表
31 # split(sub,num)通过指定分隔符对字符串进行切片,对指定分割符为空值代替
32 # 如果参数num 有指定值,则仅分隔 num 个子字符串
33 f="hellowordlll23"
34 print(f.split("l",2))#分割2个l
output:["he","","oword1ll23"]
35 print(f.rsplit("l",2))#从右找指定字符开始分割
output:["hellowordl","","l23"]
strip()移除字符串头尾指定的字符(默认为空格)。
37 # Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
38 # strip()方法语法:
39 # str.strip([chars]);
40 g=" sdsd32,dad sad $"
41 h="helloh"
42 print(g.strip())
43 print(g.strip("$").strip())
44 print(h.strip("h"))
45 h1="ohelloo"
46 print(h1.rstrip("o"))#去掉字符串最右边的字符
spliitlines(keepends)
48 #Python splitlines() 按照行('
', '
',
')分隔,
49 # 返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,
50 # 如果为 True,则保留换行符。最终返回一个列表
51 h2="sas
sad
sads"
52 print(h2.splitlines())
53 print(h2.splitlines(True)) #以换行符分割成一个列表
swapcase()
58 i="dsds212ASDSDS"
59 print(i.swapcase()) #大小写互换
zfill()
61 print(i.zfill(20)) #指定字符串长度,右对齐不够在字符串左边补0
2、格式化字符串
2.1%是格式化的操作符,有以下操作符
|
格式化符号 |
说明 |
|
%c |
转换成字符(ASCII 码值,或者长度为一的字符串) |
|
%r |
优先用repr()函数进行字符串转换 |
|
%s |
优先用str()函数进行字符串转换 |
|
%d / %i |
转成有符号十进制数 |
|
%u |
转成无符号十进制数 |
|
%o |
转成无符号八进制数 |
|
%x / %X |
转成无符号十六进制数(x / X 代表转换后的十六进制字符的大小写) |
|
%e / %E |
转成科学计数法(e / E控制输出e / E) |
|
%f / %F |
转成浮点数(小数部分自然截断) |
|
%g / %G |
%e和%f / %E和%F 的简写 |
|
%% |
输出% (格式化字符串里面包括百分号,那么必须使用%%) |
注意:
1、% s str()得到的字符串是面向用户的,具有较好的可读性
2、%r repr()得到的字符串是面向机器的 eval(repr(str))
2.2、格式化辅助操作符
通过"%"可以进行字符串格式化,但是"%"经常会结合下面的辅助符一起使用。
|
辅助符号 |
说明 |
|
* |
定义宽度或者小数点精度 |
|
- |
用做左对齐 |
|
+ |
在正数前面显示加号(+) |
|
# |
在八进制数前面显示零(0),在十六进制前面显示"0x"或者"0X"(取决于用的是"x"还是"X") |
|
0 |
显示的数字前面填充"0"而不是默认的空格 |
|
(var) |
映射变量(通常用来处理字段类型的参数) |
|
m.n |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
示例:
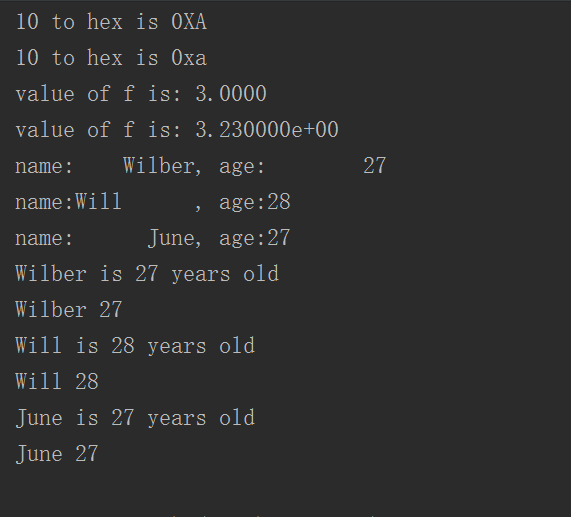
1 num = 10
2 print ("%d to hex is %x" %(num, num))#a
3 print ("%d to hex is %X" %(num, num))#A
4 print ("%d to hex is %#X" %(num, num))#0XA x/X十六进制的大小写
5 print ("%d to hex is %#x" %(num, num))#0xa
6 # 浮点数
7 f = 3
8 f2=3.23
9 print("value of f is: %.4f" %f) #保留4位小数
10 print("value of f is: %e" %f2)
11 # 指定宽度和对齐
12 students = [{"name":"Wilber", "age":27},
13 {"name":"Will", "age":28},
14 {"name":"June", "age":27}]
15 print("name:%10s, age:%10d"%(students[0]["name"], students[0]["age"]))
16 #%10s代表指定name的value宽度为10,不够在左边补空格,右对齐
17 print("name:%-10s, age:%-10d"%(students[1]["name"], students[1]["age"]))
18 #与上边相反,左对齐,
19 print("name:%*s, age:%*d"%(10,students[2]["name"], -10, students[2]["age"]))
20
21 # dict参数
22 for student in students:
23 print("%(name)s is %(age)d years old" %student)
24 print(student["name"],student["age"])
2.3、字符串的拼接
1 ''' 2 print("---请输入你的姓名和密码---") 3 username=input("username:") 4 password=input("password:") 5 print(username,password) 6 ''' 7 #python2里的raw_input和python3里一样 8 print("---请输入员工信息employee information---") 9 name=input("name:") 10 age=int(input("age:")) 11 job=input("job:") 12 salary=int(input("salary:")) 13 #字符串的拼接'''+....+''' 14 ''' 15 em_information=''' 16 em_name:'''+name+''' 17 em_age:'''+age+''' 18 em_job:'''+job+''' 19 em_salary:'''+salary+''' 20 ''' 21 print(em_information) 22 '''
23 #第2种方法采用%s格式化输出 24 #eg:%s,表示格化式一个对象为字符 比如: "Hello, %s"%"world" => "Hello, world" 这个一般用在格式化输出上 25 #%f 表示格式化一个对象为浮点型 26 em_information1=''' 27 em_name1:%s 28 em_age1:%d 29 em_job1:%s 30 em_salary:%d 31 '''%(name,age,job,salary) 32 print(type(name,),type(age)) #打印输出变量类型 33 print("em_information1:",em_information1)
34 #第3种方法,采用format()关键字参数 35 em_information2=''' 36 em_name2={_name} 37 em_age2={_age} 38 em_job2={_job} 39 em_salary2={_salary} 40 '''.format(_name=name, 41 _age=age, 42 _job=job, 43 _salary=salary) 44 print(em_information2)
45 #第4种方法,format()位置参数 46 em_information3=''' 47 em_name3={0} 48 em_age3={1} 49 em_job3={2} 50 em_salary3={3} 51 '''.format(name,age,job,salary) 52 print("em_information3:",em_information3)
补充:
infor=["Wilber",28,"it",9000]
print("""name={0[0]}
age={0[1]}
it={0[2]}
salary={0[3]}""".format(li))
2.4字符串的迭代和一些风骚的操作
1 a="hello"
2 b="hello we"
3 c=""
4 for i in a:
5 c+=i
6 print(c)
7 print(a in b)
8 print(a[::-1])#翻转字符串
9 print(list(a))#转成列表
10 print(tuple(a))#转成元组
11 str1 = '12345'
12 str2 = 'abcdef'
13 str1 += str2[0:3]
14 str3=str2[0:3]
15 print(str1,str3)
二、列表List
1、切片、增删改查
List读取操作
1 info=[1,"beijing",12,"xian",-2,-100,"changsha","@#$"]
2 print(info[2])#读取指定索引的值
3 print(info[:])#读取全部值
4 print(info[::2])#跳位读取,间隔是2
5 print(info[::-1]) #从右往左开始读取排列 相当于翻转一下
6 print(info[-3:-5])#输出为空列表,默认开始位置必须小于结束位置
7 print(info[-3:-1])
List增删改查
1 info=[1,"beijing",12,"xian",-2,-100,"changsha","@#$"]
2 info_1=[1,23,4,5,5,]
append(x)追加
3 info.append(5) #追加、默认放到最后
4 info.append("qingdao")
5 print(info)
insert(i,x),指定位置插入元素
6 info.insert(2,90) #insert指定位置插入元素 insert(self,i,x)
7 print(info)
clear(),清空列表
8 info_1.clear() #清空一个列表
9 print(info_1)
list[i]=x,修改其中的值
10 info[0]="hunan" #指定索引值修改
11 print(info)
remove(x),删除指定元素
12 info.remove("@#$") #删除指定元素
13 print(info)
pop(i),移除下标为i的值,不写默认-1删除最后一个
14 info_2=[1,23,4,5,5,]
15 info_2.pop() #默认移出最后一个
16 info_2.pop(2)#移出指定位置元素
17 print(info_2)
Del方法、删除变量,也可以删除指定值
20 info_3=[1,2,232,"sad","@#$"]
21 del info_3[0:2]
22 print(info_3)
1 info=[1,"beijing",12,"xian",-2,-100,[1,2,3],"changsha","@#$",1]
count(x),统计列表某元素出现次数
2 info.count(1) #统计元素出现的次数
3 print(info.count(1))
copy()复制一份,也可以list1=list2[:],浅copy
4 info_1=info.copy()
5 info[6]=[2,3,4]
6 print(info_1,info)
extend(list),向一个列表追加另一个列表序列
7 a=["xuzhou","xian"]
8 b=list(range(4))
9 a.extend(b) #用于列表扩展,向指定列表最后追加另外一个列表
10 b.extend(a)
11 print(a,b)
index(x.start,end),输出元素索引值,默认start、end为NONE,也可指定范围查找
12 a.index("xian") #输出指定元素下标值,index(x,i,j)i,j参数默认为空 可以指定范围
13 print(a.index("xian",1,5))
reverse()反转,等价于list[::-1]
14 a.reverse() #列表反转
15 print(a)
sort([func])排序,可以接受一个函数
16 c=[1,99,34,-100]
17 c.sort()#排序
18 print(c)#[-100,1,34,99]
2、关于列表的排序问题sort、sorted()
1 list1 = [(100,'huangxi',2),(99,'changsha',17),(-10,'aunan',90)]
2 list1.sort()#sort方法会覆盖原来的列表,ID不变
3 print(list1)# [(-10, 'hunan', 90), (99, 'changsha', 17), (100, 'huangxi', 23)]
4 # 使用匿名表达式重写key所代表的函数
5 list1.sort(key=lambda x:x[2] )
6 print(list1)#[(100, 'huangxi', 2), (99, 'changsha', 17), (-10, 'aunan', 90)]
7 # 使用匿名表达式重写key所代表的函数,按照元组的第三个元素进行排序
8 list1.sort(key=lambda x:(x[2],x[0]))
9 print(list1)
10 #对于下标2处元素相同的,则按下标为0处的元素进行排序
11 list2 = [(100,'huangxi',2),(99,'changsha',100),(-10,'aunan',90)]
12 list2.sort(key=lambda x:(x[2],x[0]),reverse=True) #降序
13 print(list2)#[(99, 'changsha', 100), (-10, 'aunan', 90), (100, 'huangxi', 2)]
引用operation模块
1 from operator import attrgetter,itemgetter
2 list1 = [(100,'huangxi',2),(99,'changsha',17),(-10,'dunan',90)]
3 # 使用operator模块中的itemgetter函数进行重写key所代表的函数,按照下标为1处的元素进行排序
4 list1.sort(key=itemgetter(1))#按照列表中元组下标为1的进行排序
5 print(list1)#[(-10, 'aunan', 90), (99, 'changsha', 17), (100, 'huangxi', 2)]
6 #使用operator模块中的itemgetter函数进行重写key所代表的函数,
7
8 list1.sort(key=itemgetter(2))# 按照下标为2处的元素进行排序
9 print(list1)#[(100, 'huangxi', 2), (99, 'changsha', 17), (-10, 'dunan', 90)]
10 list1.sort(key=itemgetter(2,0))#先按下标为2的排,相同的再按下标为0 的进行排序
11 print(list1)
sorted()方法

总结:
sort是容器的函数:sort(cmp=None, key=None, reverse=False)
sort()是可变对象(字典、列表)的方法,无参数,无返回值,sort()会改变可变对象,因此无需返回值。sort()方法是可变对象独有的方法或者属性,而作为不可变对象如元组、字符串是不具有这些方法的,如果调用将会返回一个异常。
sorted是python的内建函数:sorted(iterable, key=None, reverse=False)
sorted()是python的内置函数,并不是可变对象(列表、字典)的特有方法,sorted()函数需要一个参数(参数可以是列表、字典、元组、字符串),无论传递什么参数,都将返回一个以列表为容器的返回值,如果是字典将返回键的列表。
三、字典dict
1、字典的基本操作
1 d1={"name":"xx","job":"it","age":22,"salary":8000,"city":"beijing","sex":"m"}
dict的读取dict[key]和修改dict[key]=value
2 print(d1["name"],d1["age"]) #字典读
3 d1["name"]="ww"#修改key的value
4 d1["爱好"]="study" 如果key不存在则创建一个房子末尾
5 print(d1)
get(key),查看键值对应的元素,不存在则返回NONE
6 print(d1.get("name"))#查看键值对应的元素,不存在则返回NONE
setdefault(key,default=NONE)查看key对应的元素,不存在则创建,Value为NONE
8 print(a.setdefault("city"))
items(),把字典转成一个列表,[(key,value),(key,value)....]
9 print(type(d1.items()),d1.items())#dict_items([('name', 'xx'), ('job', 'it'), ('age', 22), ('salary', 8000)])
copy()
10 d2=d1.copy() #字典的复制
11 print(d2)
keys():输出键值 values():输出Value值
12 print(d1.keys())#dict_keys(['name', 'job', 'age', 'salary']) 输出key值
13 print(d1.values())#dict_values(['xx', 'it', 22, 8000]) 输出value
pop(key)删除元素,popitem()删除最后一个(key,value)
14 print(d1.pop("city"))#删除Key的Value 返回Value
15 print(d1.popitem())#('sex', 'm') 删除最后一个key和value 返回一个tuple
update(dic)更新列表,参数必须是字典
16 a={"age":22}
17 b={"age":32,"sex":"M"}
18 a.update(b) #用于更新列表
19 print(a,b) #{'age': '32', 'sex': 'M'} {'age': '32', 'sex': 'M'}
描述
2 Python 字典 fromkeys() 函数用于创建一个新字典
3 以序列seq中元素做字典的键,value为字典所有键对应的初始值。
4 语法
5 fromkeys()方法语法:
6 dict.fromkeys(seq[, value]))
7 参数
8 seq -- 字典键值列表。
9 value -- 可选参数, 设置键序列(seq)的值。
11 a=["name","city","job","age"]
12 a1=dict.fromkeys(a)
13 print(a1)#{'name': None, 'city': None, 'job': None, 'age': None}
14 b=dict.fromkeys("c",3) #创建一个新字典
15 print(b)#{'c': 3}
四、元组tuple
tuple相当于不可变列表,例如 a=(1,2,3,"xx",(23,1,2),"df"),不能对里边进行修改,只有count(),index()两种方法
在相同数值情况下,元组占用更小的内存
五、集合set

注意:想要创建空集合,你必须使用set() 而不是 {} 。{}用于创建空字典
list去重
list_1=set([1,2,3,5,88,90,789,3])
list_2=set([22,33,5,123,90,"q","e"])
list_3=set([1,3,5])
print(list_1,list_2)
(交集、并集、差集)
print(list_1.intersection(list_2)) #两个集合的交集
print(list_1&list_2) #交集 {90, 5}
print(list_1.union(list_2))#两个集合合并,并集
print(list_1|list_2) #并集
print(list_1.difference(list_2)) #差集,去掉交集,我有的你没有
print(list_1-list_2) #差集
print(list_2.difference(list_1))
print(list_1.symmetric_difference(list_2))#对称差集,去掉相同的元素,连接起来
print(list_1^list_2) #对称差集
关系测试(子集、交集)
print(list_3.issubset(list_1)) #判断是否是子集
print(list_1.isdisjoint(list_2)) #判断两个集合有无交集没有返回Ture
集合的操作
a={"q","w",1,222,452}
print(list_1.pop(),list_1) #随机删除
a.add("3333") #添加一项
print(a)
a.update([1,2333,"df",2223]) #添加多项元素
print(a)
a.remove(1) #删除指定元素
print(a)
print(len(a)) #长度
print(452 in a)
c={1,2}
d={1,2,5,7,900}
print(c<=d) #测试是否为子集
print(d.discard(1),d) #discard 删除指定元素 返回none,删完了不会做什么,并不存在也不会报错