一、hashlib模块补充
1,密文验证
import hashlib #引入模块 m =hashlib.md5() # 创建了一个md5算法的对象 m.update(b'123456') print(m.hexdigest())
加盐
m =hashlib.md5(b'bilibili) # 传入固定的盐,必须是byte类型
m.update(b'123456')
print(m.hexdigest())
动态加盐
user = b'bilibili'
m = hashlib.md5(user[::-1]) #以用户名作为盐,还可以切片
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
sha1与md5用法完全一样。只是密码更长,更慢
2,文件的一致性校验
import hashlib 导入模块 def check(filename): 定义函数 md5obj = hashlib.md5() 创建md5算法对象 with open('file1','rb')as f: 以rb形式打开文件 content = f.read() 读取文件 md5obj.update(content) 对文件进行摘要 return md5obj.hexdigest() 返回给调用者 ret = check('file1') ret1 = check('file2') print(ret) print(ret1)
import hashlib
def check(filename):
md5obj = hashlib.md5()
with open('file1','rb')as f:
while True:
content = f.read(4096) 每次读取4096个字节
if content: 如果content不为空
md5obj.update(content) 执行算法
else:
break
return md5obj.hexdigest()
ret = check('file1')
ret1 = check('file2')
print(ret)
print(ret1)
上周模块回顾
序列化 把数据类型变成字符串
为什么要有序列化 因为在网络上和文件中能存在的只有字节
json 在所有语言中通用 只对有限的数据类型进行序列化 字典 列表 字符串 数字 元组
在多次写入dump数据进入文件的时候,不能通过load来取。
pickle 只能在python中使用 对绝大多数数据类型都可以进行序列化
在load的时候,必须拥有被load数据类型对应的类在内存里
dumps 序列化
loads 反序列化
dump 直接向文件中序列化
load 直接对文件反序列化
configparse模块
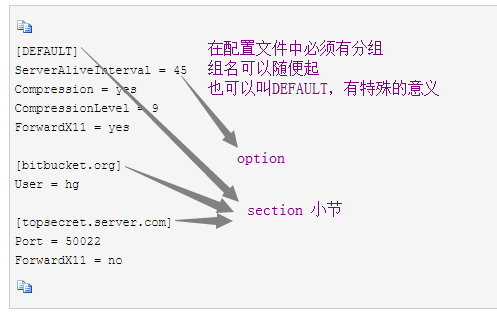
用于配置文件,与ini文件类似,包含一个或多个节(section),每个节可以有多个参数(键=值)。(写入的字母会变小写)
import configparser 导入模块
config = configparser.ConfigParser() 用面向对象创建一个config对象
config["DEFAULT"] = {'a': '45', 利用__getitem__方法,调取section,写入对象
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as f: 打开文件
config.write(f) 写入文件
查找文件内容,基于字典的形式
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
print(config.sections()) # 查看所有的节 但是默认不显示DEFAULT []
print('bitbucket.org' in config) # True 验证某个节是否在文件中
print('bytebong.com' in config) # False
print(config['bitbucket.org']["user"]) # hg 查看某节下面的某个配置项的值
print(config['DEFAULT']['Compression']) #yes ['DEFAULT']相当于全局变量,他的项在其他组都有
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org>
for key in config['bitbucket.org']: # 注意,有default会默认default的键
print(key)
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
配置文件的增删改
import configparser
config.write(open('new2.ini', "w"))
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('yuan') 增
config.remove_section('bitbucket.org') 删
config.remove_option('topsecret.server.com',"forwardx11") 删
config.set('topsecret.server.com','k1','11111') 改
config.set('yuan','k2','22222') 改
section 可以直接操作它的对象来获取所有的节信息
option 可以通过找到的节来查看多有的项
logging模块
log 日志
管理员
服务器上做操作
消费记录
淘宝
日志
给我们在内部操作的时候提供很多遍历
给用户提供更多的信息
在程序使用的过程中自己调试需要看的信息
帮助程序员排查程序的问题
logging模块 不会自动帮你添加日志的内容
你自己想打印什么 你就写什么
logging
简单配置
配置logger对象
简单配置
import logging
默认情况下 只显示 警告 及警告级别以上信息
logging.basicConfig(level=logging.DEBUG, 可通过修改level,调整显示范围
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %y %H:%M:%S',
filename = 'userinfo.log'
)
logging.debug('debug message') # debug 调试模式 级别最低
logging.info('info message') # info 显示正常信息
logging.warning('warning message') # warning 显示警告信息
logging.error('error message') # error 显示错误信息
logging.critical('critical message') # critical 显示严重错误信息
配置参数
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
logging模块的不足:1,编码格式不能设,2,不能同时输出到文件和屏幕
配置logger对象
import logging
logger = logging.getLogger() # 实例化了一个logger对象
fh = logging.FileHandler('test.log',encoding='utf-8') # 实例化了一个文件句柄
sh = logging.StreamHandler()
fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(fmt) # 格式和文件句柄或者屏幕句柄关联
sh.setFormatter(fmt)
sh.setLevel(logging.WARNING)
吸星大法
logger.addHandler(fh) # 和logger关联的只有句柄
logger.addHandler(sh)
logger.setLevel(logging.DEBUG)
logger.debug('debug message') # debug 调试模式 级别最低
logger.info('info message') # info 显示正常信息
logger.warning('warning message') # warning 显示警告信息
logger.error('error message') # error 显示错误信息
logger.critical('critical message')
logging
logging 是记录日志的模块
它不能自己打印内容 只能根据程序员写的代码来完成功能
logging模块提供5中日志级别,从低到高一次:debug info warning error critical
默认从warning模式开始显示
只显示一些基础信息,我们还可以对显示的格式做一些配置
简单配置 配置格式 basicCondfig
问题:编码问题,不能同时输出到文件和屏幕
logger对象配置
高可定制化
首先创造logger对象
创造文件句柄 屏幕句柄
创造格式
使用文件句柄和屏幕句柄 绑定格式
logger对象和句柄关联
logger.setLevel
使用的时候 logger.debug
作业
写一个函数
参数是两个文件的路径
返回的结果是T/F/
import hashlib
def compare(filename1,filename2):
md5sum = []
for file in [filename1,filename2]:
md5 = hashlib.md5()
with open(file,'rb') as f:
while True:
content = f.read(1024)
if content:
md5.update(content)
else:break
md5sum.append(md5.hexdigest())
if md5sum[0] == md5sum[1]:return True
else :return False
print(compare('f1','f2'))
def compare(filename1,filename2):
md5sum = []
for file in [filename1,filename2]:
md5 = hashlib.md5()
with open(file,'rb') as f:
while True:
content = f.read(1024)
if content:
md5.update(content)
else:break
md5sum.append(md5.hexdigest())
if md5sum[0] == md5sum[1]:return True
else :return False
print(compare('f1','f2'))