构造线性回归模型
代码
def linear_regression(): """ 自实现一个线性回归 :return: """ # 1)准备数据 x = tf.compat.v1.random_normal(shape=[100, 1]) y_true = tf.matmul(x, [[0.8]]) + 0.7 print("前:",x) # 2)构造模型 # 定义模型参数 用 变量 weights = tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[1, 1])) bias = tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[1, 1])) y_predict = tf.matmul(x, weights) + bias # 3)构造损失函数 均方误差 error = tf.reduce_mean(tf.square(y_predict - y_true)) # 4)优化损失 optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) # 显式地初始化变量 init = tf.compat.v1.global_variables_initializer() # 开启会话 with tf.compat.v1.Session() as sess: # 初始化变量 sess.run(init) print("后:",sess.run(y_true)) # 查看初始化模型参数之后的值 print("训练前模型参数为:权重%f,偏置%f,损失为%f" % (weights.eval(), bias.eval(), error.eval())) #开始训练 for i in range(100): sess.run(optimizer) print("第%d次训练后模型参数为:权重%f,偏置%f,损失为%f" % (i+1, weights.eval(), bias.eval(), error.eval())) return None
构造逻辑回归模型
代码
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data def full_connection(): tf.compat.v1.disable_eager_execution() # 1)准备数据 mnist = input_data.read_data_sets("../mnist_data", one_hot=True) # 用占位符定义真实数据 x = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None, 784]) y_true = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None, 10]) # 2)构造模型 - 全连接 # [None, 784] * W[784, 10] + Bias = [None, 10] weights = tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[784, 10], stddev=0.01)) bias = tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[10], stddev=0.1)) #y_predict = tf.matmul(x, weights) + bias y_predict = tf.compat.v1.nn.softmax(tf.matmul(x, weights) + bias) loss=tf.reduce_mean(-tf.reduce_sum(y_true*tf.compat.v1.log(y_predict),1)) # 3)构造损失函数 #loss_list = tf.nn.softmax_cross_entropy_with_logits(logits=y_predict, labels=y_true) #loss = tf.reduce_mean(loss_list) # 4)优化损失 梯度下降 optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss) #optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=0.01).minimize(loss) # 5)增加准确率计算 argmax(y_true, axis=1)求矩阵行最大值的索引 cast()类型转换 bool_list = tf.equal(tf.argmax(y_true, axis=1), tf.argmax(y_predict, axis=1)) accuracy = tf.reduce_mean(tf.cast(bool_list, tf.float32)) # 初始化变量 init = tf.compat.v1.global_variables_initializer() # 开启会话 with tf.compat.v1.Session() as sess: # 初始化变量 sess.run(init) # 开始训练 for i in range(100): # 获取真实值 image, label = mnist.train.next_batch(500) # print(image.shape) # print(label.shape) _, loss_value, accuracy_value = sess.run([optimizer, loss, accuracy], feed_dict={x: image, y_true: label}) tsst_acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y_true:mnist.test.labels}) print("第%d次的损失为%f,准确率为%f, 测试集准确率%f" % (i+1, loss_value, accuracy_value,tsst_acc)) return None if __name__ == "__main__": full_connection()
神经网络模型
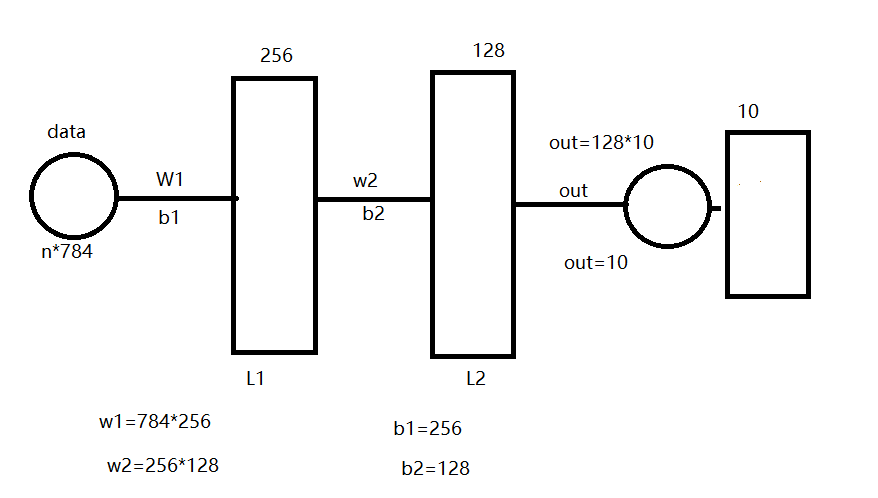
代码
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data tf.compat.v1.disable_eager_execution() mnist = input_data.read_data_sets("./mnist_data", one_hot=True) # 用占位符定义真实数据 x = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None, 784]) y = tf.compat.v1.placeholder(dtype=tf.float32, shape=[None, 10]) weights={ 'w1':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[784, 256], stddev=0.01)), 'w2':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[256, 128], stddev=0.01)), 'out':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[128, 10], stddev=0.01)), } biases={ 'b1':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[256])), 'b2':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[128])), 'out':tf.Variable(initial_value=tf.compat.v1.random_normal(shape=[10])), } def multilayer_perceptron(_x,_weights,_biases) : layer_1 = tf.compat.v1.nn.sigmoid(tf.add(tf.matmul(_x,_weights['w1']),_biases['b1'])) layer_2 = tf.compat.v1.nn.sigmoid(tf.add(tf.matmul(layer_1,_weights['w2']),_biases['b2'])) return (tf.matmul(layer_2,_weights['out']) +_biases['out']) pred=multilayer_perceptron(x,weights,biases) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) # optimizer = tf.compat.v1.train.GradientDescentOptimizer (learning_rate=0.01).minimize(loss) optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=0.01).minimize(loss) bool_list = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(bool_list,tf.float32)) init = tf.compat.v1.global_variables_initializer() with tf.compat.v1.Session() as sess: # 初始化变量 sess.run(init) # 开始训练 for i in range(100): # 获取真实值 image, label = mnist.train.next_batch(500) # print(image.shape) # print(label.shape) _, loss_value, accuracy_value = sess.run([optimizer, loss, accuracy], feed_dict={x: image, y: label}) tsst_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}) print("第%d次的损失为%f,准确率为%f, 测试集准确率%f" % (i + 1, loss_value, accuracy_value, tsst_acc))