一、请求一个网页内容打印
爬取某个网页:
1 from urllib import request 2 # 需要爬取的网页 3 url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1" 4 # 打开网页,并返回 5 rsp = request.urlopen(url) 6 # 读取返回的结果 7 html = rsp.read() 8 # 由于rsp返回的是流文件需要解码 9 html = html.decode() 10 printf(html)
爬取一个网页的基本流程:
1、获取所需网页request.urlopen("网页链接")
2、读取返回页面 rsp.read()
3、解码:html.decode()
二、自动识别网页编码
1 from urllib import request 2 import chardet 3 url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1" 4 res = request.urlopen(url) 5 html = res.read() 6 # 检查编码 7 cs = chardet.detect(html) 8 # 编码设置 9 html = html.decode(cs.get("encoding", "utf-8")) 10 print(html)
第7行返回一个类似{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}的字典 encoding是编码格式,confidence是前面编码格式的概率。第九行进行解码设置,如果有匹配的编码按照获取的方式进行解码,否则按照“utf-8”的方式解码。
三、到百度页面爬取指定内容
1 from urllib import request, parse 2 if __name__ =='__main__': 3 url = "http://www.baidu.com/s?" 4 # 输入关键词 5 wd = input("Input keyword:") 6 # 把关键字以字典保存 7 qs = { 8 "wd":wd 9 } 10 # 把关键字进行编码 11 qs = parse.urlencode(qs) 12 # 拼凑成完整的url 13 fullurl = url + qs 14 res = request.urlopen(fullurl) 15 html = res.read().decode() 16 print(html)
四、进行百度翻译:
解析:
1、打开F12
2、尝试输入单词,发现每输入一个字母都有请求
3、找到请求的地址:https://fanyi.baidu.com/sug
4、在NetWork-All-Headers中查看,发现FormData的关键字是 kw:单词
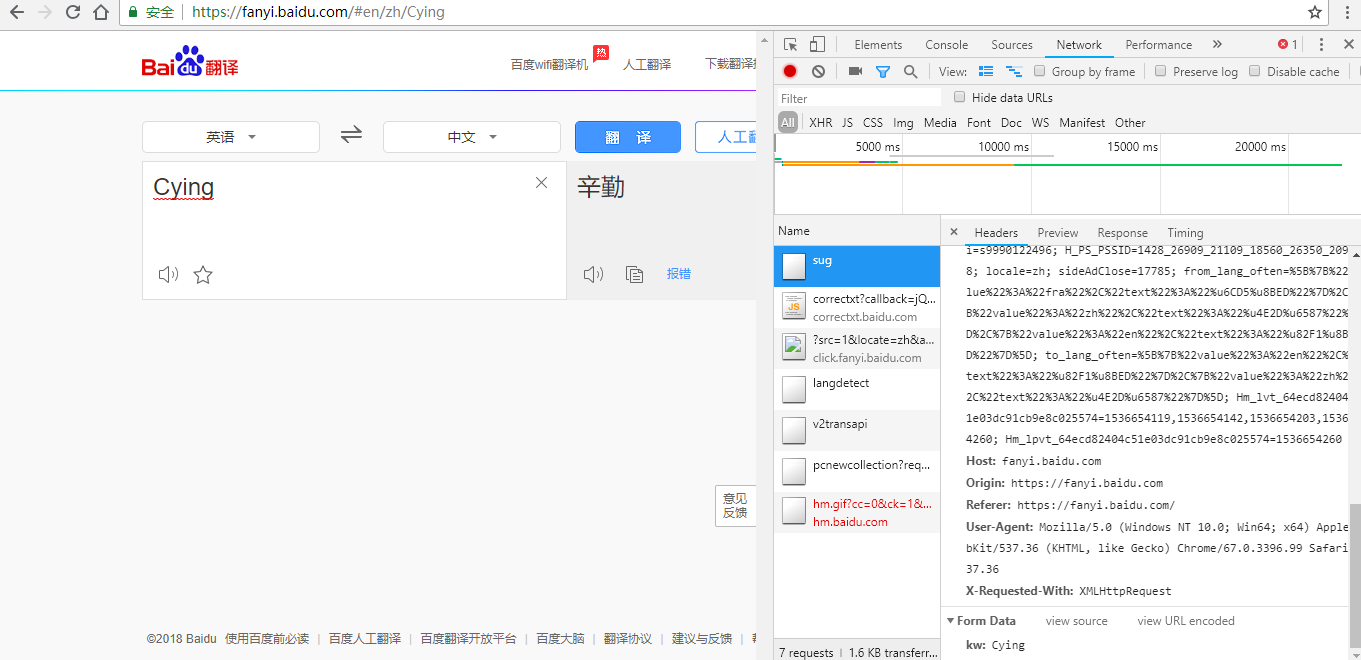
5、打开sug文件发现数据时json格式
方式一:
1 from urllib import request, parse 2 import json 3 baseurl = "https://fanyi.baidu.com/sug" 4 word = input("请输入单词: ") 5 data = { 6 "kw":word 7 } 8 # 对单词进行编码 9 data = parse.urlencode(data).encode() 10 # 构建请求头 11 rsp = request.urlopen(baseurl, data = data) 12 json_data = rsp.read().decode() 13 # 由于返回的是json数据,转换成字典 14 json_data = json.loads(json_data) 15 for item in json_data['data']: 16 print(item['k'], item['v'])
翻译流程:
1、利用data构造内容,然后用URLopen打开
2、返回一个json格式
3、转换成字典,输出
方式二:
1 from urllib import request, parse 2 import json 3 baseurl = "https://fanyi.baidu.com/sug" 4 word = input("请输入单词:") 5 data = { 6 "kw": word 7 } 8 data = parse.urlencode(data).encode('utf-8') 9 headers = { 10 'Content-Length':len(data) 11 } 12 req = request.Request(url = baseurl, data = data, headers = headers) 13 res = request.urlopen(req) 14 json_data = res.read().decode() 15 json_data = json.loads(json_data) 16 for item in json_data['data']: 17 print(item['k'], item['v])
五、urllib.error
在某些时候爬取网站出现问题,可以通过 URLError和HTTPError查找问题
1、URLError产生原因
- 没网
- 没有指定服务器
- 服务器连接失败
1 from urllib import request, error 2 if __name__ == '__main__': 3 url = "http://www.baidu.com" 4 try: 5 req = request.Request(url) 6 res = request.urlopen(req) 7 html = res.read().decode() 8 except error.URLError as e: 9 print("URLError: {0}".format(e.reason)) 10 except Exception as e: 11 print(e)
2、HTTPError
HTTPError一般对应HTTP请求的返回码错误,如果返回的错误码是400以上引发HTTPError
与URLError的关系:
OSError -> URLError -> HTTPError
代码:
1 from urllib import request, error 2 if __name__ == '__main__': 3 url = "http://www.baidu.com" 4 try 5 req = request.Request(url) 6 res = request.urlopen(req) 7 html = res.read().decode() 8 except error.HTTPError as e: 9 print ("URLError: {0}".format(e.reason)) 10 print ("HTTPError: {0}".format(e)) 11 except error.URLError as e: 12 print ("URLError: {0}".format(e.reason)) 13 print ("HTTPError: {0}".format(e)) 14 except Exception as e: 15 print(e)