一、基于度量的程序结构分析
1、第一次作业
(1)类的度量

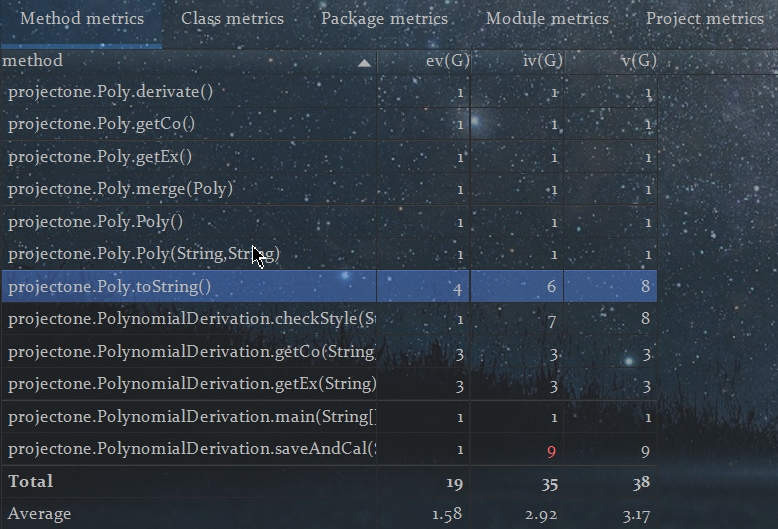
内聚与耦合度分析:第一次作业实际上并没有成功实现真正意义上的面向对象,甚至我的代码第一次完工时整个文件只有一个类,可以说思想完全停留在“面向过程”的C语言时代,类之间的轻重分工严重失调,各种方法与对象全都在主类之中交织在一起,尤其是checkStyle,saveAndCal这两个本地静态函数,承担了太多的功能,没有抽象的层次感,内聚性不强,耦合度过高。
(2)UML类图

构造思路与优缺点分析:正如之前所说,本次作业的构造的思想更多的是“面向过程”的,即使构建了新的Poly类,也只是更多的使用了其封装特性,即类似于C语言的结构体。整个设计思路就是顺着题目的要求,将操作分成如下几个部分,判断输入格式—>计算每一项的导数并储存(合并同类项)—>按正确格式输出成字符串,然后为每一步操作创建相应的实现方法,即图中的checkStyle,saveAndCal,toString三个方法,再依次执行即可。从实现功能完成题目要求的角度来看,这样的设计阶段分工明确,思路清晰;但从实践面向对象思想的角度看的话,这样的构造的缺点十分明显,没有明确的抽象层次,可扩展性太差,只能用于特定题目与特定要求,一旦题目要求发生些许变化,整个构造可能就需要推翻重来。
(3)本次作业收获总结
虽然这次作业没有锻炼到“面向对象”的设计思想,但在实现要求遇到问题的过程中通过查找网上有关资料以及自我思考学习到了一些之前所不知道的内容,也算是收获颇多。
①运用正则表达式判断输入格式(以下为自己在完成第一次作业后所总结的正则表达式使用方法以及相关注意事项):
正则需要转义字符有:'$','(',')','*','+','.','[',']','?','\','^','{','}','|'
转义:两个反斜杠加字符(两个\匹配成,再接转义字符)。如:\.,\+,\-,\{,\( …… 特殊:4个斜杠在正则表达式里面表示一个斜杠。转义到字符中的"\"才真正代表了""。
开始:^
结束:$
字符:[abcAZ] 只代表在括号范围内出现的一个字符
方括号内:[^asd] (除外的字符) [a-cw-z](范围,可分多段)[&&] (交集)
组:([abc]b+)?多个字符组成的串需要次数修饰时用小括号将多个字符组成串
修饰符:*(0次及以上),+(1次及以上),?(0次或1次),{n}(正好出现n次),{n,}(n次及以上),{n,m}(n到m次)
修饰符只对前面的一个字符或一组字符生效
特殊单字符:(点号 .) 匹配任意字符,( \d) 匹配0~9数字,(\D)匹配非数字,(\s)匹配空白字符,(\S)匹配非空白字符
(\w)匹配可用作标识符的字符即[a-zA-Z_0-9],(\W)匹配不可为标识符的字符
或运算:|,匹配多个不同条件(使用^和$表示不同条件开始和结束),也可以用在单个串内的小部分
在本次作业中用于判断格式的匹配串:strSimplified.matches("(([\+\-]\d+)|([\+\-](\d+\*)?x(\^[\+\-]?\d+)?))+")
②使用HashMap完成合并同类项:
HashMap使用key-value键值映射的方式来实现数据的存储,并通过对key值的操作来查找相应的value是否存在或者是否需要更新。本次作业为了优化性能需要在同幂数的幂函数相加时合并系数,幂数恰好可以用来作为key值,在每次求导完成后得到新的幂函数项时,判断HashMap中是否存在该项幂数作为key,若存在,则需要合并相应系数 并将添加key指向合并后的新项的映射;若不存在,则直接构造key指向项的映射,最后通过迭代器Iterator遍历HashMap并调用toString方法完成输出。
2、第二次作业
(1)类的度量
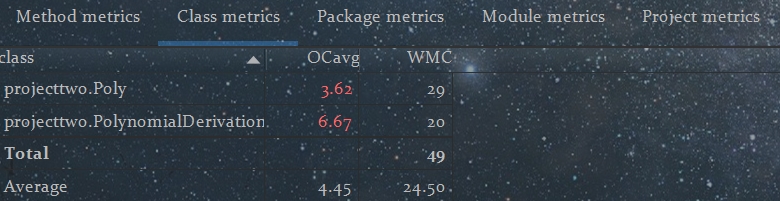
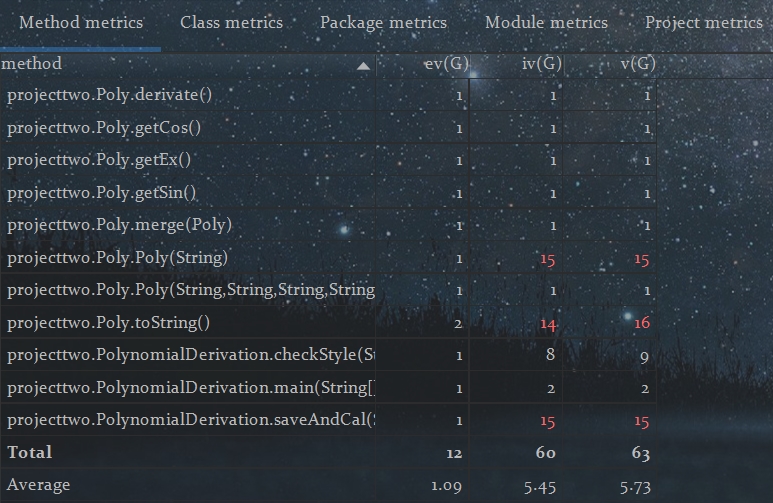
内聚与耦合度分析:可以发现,第二次作业的类与各种方法与第一次作业中的十分相似,保留了第一次作业中主类的架构,只是在另外的Poly中多加了两个属性来处理新的三角函数因子,原有的主类静态函数checkStyle与saveAndCal还是占据大部分功能,而没有通过抽象分层进行解耦。
(2)UML类图

构造思路与优缺点分析:由于上文提到的面向过程程序只能用于特定要求的特点,在初次面对第二次作业时,曾想过推翻原构造,并尝试使用“面向对象”的思想来完成本次题目,但在随后的思考中发现新添加的三角函数因子的底数只能有sin(x)和cos(x)两种形式,这实际上是与原来的幂函数因子是没有本质区别的,进一步发现表达式的每一项都可以写成k*x^a*sin(x)^b*cos(x)^c的形式,且由k,a,b,c即可得到求导后的结果,那么就只需要修改原来的求导函数derivate,并相应调整Poly类的属性与toString即可。于是我就在这次构造中偷了懒,却没想到这一次小小的懒惰让我在面对第三次作业时不得不付出惨痛代价。
(3)本次作业收获总结
以下两点均来自研讨课上同学和助教的经验分享。
①启发式搜索优化输出:本次作业可以通过sin(x)^2+cos(x)^2=1来对输出长度进行化简,设计搜索函数在sin(x)^n高次幂项中拆出sin(x)^2,用sin(x)^2=1-cos(x)^2化简后比较新的结果是否更短,并向输出更短的方向不断继续通过限制搜索的时间来结束搜索,在平均程度上来讲将得到较优的优化结果。
②HashMap使用自定义类作为key值完成检索:本次作业的项是包含x、sin(x)、cos(x)三种因子的,从而合并同类项时的key值就不再是简单的类型,而是由这三种因子的幂数组成的三元组,可以将三元组定义为类,并使用自定义类作为HashMap的key,这时需要重写Object类的hasCode与equals方法,由比较自定义类的地址改为比较类的内容是否相同,从而完成合并同类项的操作。
3、第三次作业
(1)类的度量



内聚与耦合度分析:与上次作业相比,第三次作业真的算是推翻一切重新来过了。这一次的作业之中实现了层次化构造,将原来的Poly类拆成Expression,Item,Factor三个层次,主类之中只剩下去空格化简的simplified方法,原有的checkStyle和saveAndCal被拆分成isExpression,isItem,is(..)Factor以及各类内的derivate方法,在一定程度上实现了解耦,基本符合了面向对象程序所要求的“高内聚,低耦合”特性。
(2)UML类图
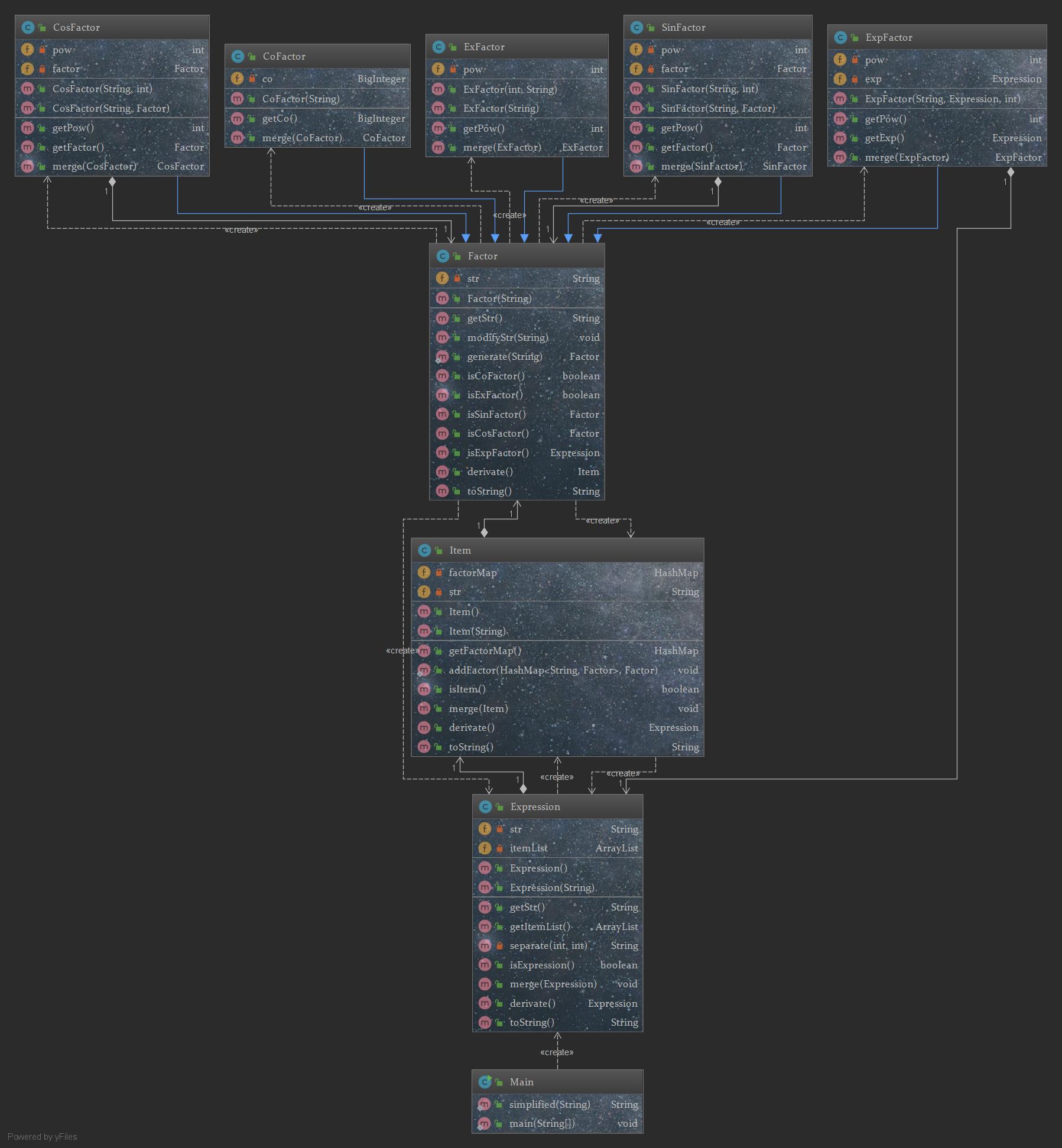
构造思路与优缺点分析:当看到第三次作业中存在表达式因子以及三角函数内含嵌套因子时,我知道终于无法再通过修修补补之前两次丑陋的面向过程程序来蒙混过关了,甚至嵌套因子的存在让功能强大的正则表达式都难以处理。其实仔细阅读指导书可以发现,指导书上关于表达式,项,因子的介绍已经为我们划分出了抽象的层次,于是创建Expression,Item,Factor三个类,并根据因子的分类创建CoFactor,ExFactor,SinFactor,CosFactor,ExpFactor五个子类,根据嵌套因子的存在要求,SinFactor与CosFactor中分别含有一个Factor对象作为成员属性,而ExpFactor中则含有一个Expression对象作为成员属性,完成了底层向上层的返回从而实现了递归下降。每个类在创建时传入对应部分的字符串,首先调用is_(类)函数进行递归拆分后在底层的五类Factor中进行格式判断,若格式正确则返回相应创建的新的类,否则输出WF并结束程序。求导过程同样逐层进入,遇到嵌套因子或表达式因子时递归求导,其中需要在项求导时运用乘法法则:[f(x)*g(x)*h(x)*u(x)*...]' =[f(x)]' *g(x)*h(x)*u(x) + f(x)*[g(x)]' *h(x)*u(x) + f(x)*g(x)*h(x)*[u(x)]' + ...,其中f(x),g(x),h(x),u(x)等均为因子Factor对象,Factor对象求导时运用嵌套法则[f(g(x))]' = f'(g(x))*g'(x),其中g(x)可能为Factor也可能为Expression,调用相应类的derivate方法后继续递归循环求导直至最初原始表达式的求导完成。本次构造的优点在于通过底层类内使用顶层类作为成员属性的方式实现了嵌套复杂表达式的拆解,结构清晰,分工明确;缺点一方面是没有充分灵活地将接口的使用融入其中,尤其是父类Factor与五个因子子类之间的方法行为构架尤其糟糕,两个重要方法derivate与toString都是写在父类Factor中,通过if instance of 的方法针对不同子类完成操作,面向对象的多态特性也没有得到体现。此外,在输出长度性能分方面,由于时间仓促,只是实现了最简单的省略+0、省略*1等操作以及项内同类相乘因子的合并(Item类内使用HashMap成员属性存Factor)而没有实现表达式内同类相加项的合并(Expression类中只使用了ArrayList存项),同时对于多余括号嵌套的情况也没有完成处理。
(3)本次作业收获总结
终于在本单元的最后一次作业中成功运用面向对象的思想设计出了能够解决题目要求的程序,这样的构造过程让我充分体会到了“面向对象”抽象层次化思想的强大之处,通过抽象Expression、Item、Factor三个类便可以将复杂的原表达式一层层剥开一点点深入到底层,并通过Factor成员属性的设置再返回顶层从而实现递归,正是因为“对象”的存在才让这种高度抽象的算法有了清晰简单的实现方式。实际上,当我们将一个问题分成几个抽象层次而非几个过程阶段时,就已经实现了从面向过程思想向面向对象思想的转变,可以说本单元的第三次作业是我自己的第一份面向对象程序,是迈向面向对象世界的第一步,这一步虽然艰苦,但却也收获颇丰,希望自己能够在未来的OO之旅中了解到更多更全面的面向对象思想与知识,攻坚克难、再接再厉!
二、自己程序中bug的分析
1、第一次作业
在第一次作业的中测与强测中,我的程序均未被测出bug,而在之后的互测过程中,被发现一处同质bug,造成该bug的主要原因为判断非法空格处的正则表达式中判断幂数中的符号与数字间的空格位置时将幂符号^错写成了符号*,从而导致一些幂数中含空格的WF输入没有被正确检测,反而输出了求导的结果。这一问题一是出在自己写代码时头脑不够清醒,没有对每一行自己写下的代码作出逻辑结果的及时验算,二是测试时自己构造的样例集覆盖面不够广,错过了发现bug的机会。
2、第二次作业
在第二次作业的中测,强测与互测中,我的程序均未被测出bug。
3、第三次作业
在第三次作业的中测与强测中,我的程序均未被测出bug,在之后的互测过程中,被发现一处同质bug。这一次的bug主要是对于类内方法传入参数为对象引用这一点的理解不够到位,在程序的5个子类因子中都有合并同类因子的方法merge,但在实现这个方法时,我并没有new出一个新的该类对象,而是直接对传入的参数对象进行了合并并返回该对象,我本以为这样的储存不会影响结果,但是却暗中改变了原表达式的值,进而导致了计算结果出现莫名其妙的偏差,同时能够发现这一bug的样例又需要十分巧妙的构造,并没有在自己测试的过程中发现。可以说这次的bug十分隐晦,我自己在bug修复的过程中也是反复多次单步调试才完成bug定位并成功修复,但同时也让我吸取了经验教训,认识到使用不变值的重要性。
三、发现别人程序bug所采用的策略
面对7人份每份几百行的代码,直接通过读代码寻找逻辑漏洞显然是不现实的,故采用“黑盒”思想,构造测试集对每份程序进行全面测试以寻找bug,并未完全结合被测试代码的构造设计,但还是读了每份代码的正则构造部分,一方面是增强自己阅读正则表达式的能力,另一方面可以直接发现在输入处理上的一些bug而不需要测试数据进行盲测。
1、鲁棒性测试
①错误的输入格式(如不同的非法空格位置、多余符号、非法空白字符、带幂数的表达式因子)
②压力测试(如最大数据限制下的数据、超过int范围的大整数、超过要求范围的幂数)
③空串或只有空白字符的串
2、功能测试
构造全面测试集:五类因子的各种组合、嵌套因子的组合、正负号与因子的组合等。
四、Applying Creational Pattern
面向对象创建模式主要有以下几种形式:
1、工厂模式
适合凡是出现了大量的产品需要创建,并且具有共同的接口时,可以通过工厂方法模式进行创建。
2、单例模式
单例对象(Singleton)是一种常用的设计模式。在Java应用中,单例对象能保证该对象只有一个实例存在。这样的模式中,某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。同时省去了new操作符,降低了系统内存的使用频率,减轻GC压力。
3、建造者模式
建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以与工程模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注创建符合对象,多个部分。因此,是选择工厂模式还是建造者模式,依实际情况而定。
在本单元的作业之中,第一次和第二次作业只有主类和另外一个项类Poly,不太需要使用创建模式。第三次作业可以使用工厂模式创建对象,我目前的程序是使用各类对象的构造方法且没有使用接口,如果要重构的话,首先需要构造各类共同的求导接口derivater,其次需要构造一个用于创建的工厂类factory,根据传入字符串不同的情况,调用相应的创建方法。在需要求导时,通过接口derivater中的derivate方法在不同类中的重写实现求导。