一、 Github地址:
https://github.com/huihuigo/wc
二、 解题思路
- 功能分析
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
wc.exe -s dirname //递归处理目录下符合条件的文件。
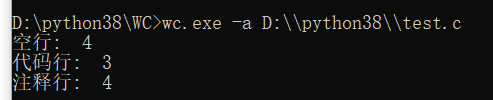
wc.exe -a filename //返回更复杂的数据(代码行 / 空行 / 注释行)
2. 设计思路
为五个功能分别设计一个函数,在主函数中接受参数以及文件名进行函数选择,其中每个函数涉及文件的读操作,以及大量对字符串的处理。
三、 设计实现过程
设计一个模块,五个函数分别对应五个功能,主函数接受参数进行函数选择,并将文件名传入函数。其中递归函数count_dir()会调用count_char() 、count_word() 、count_line()来处理所有符合条件的文件
count_char(filename) //返回文件 file.c 的字符数
count_word(filename) //返回文件 file.c 的词的数目
count_line(filename) //返回文件 file.c 的行数
count_dir(dirname) //递归处理目录下符合条件的文件
count_all(filename) //返回更复杂的数据(代码行 / 空行 / 注释行)
四、 代码说明
- 统计字符数
1 def count_char(filename): 2 try: 3 with open(filename, 'r', encoding='utf-8') as f: 4 text = f.read() 5 return len(text) #调用库函数len计算并返回 6 except FileNotFoundError: 7 print('%s does not exist' % filename)
- 统计词数
1 def count_word(filename): 2 try: 3 with open(filename, 'r', encoding='utf-8') as f: 4 text = f.read() 5 words = re.split(r'W+', text) #调用正则表达式模块对文本进行词的分隔 6 if words[-1] == "": 7 return len(words) - 1 8 return len(words) 9 except FileNotFoundError: 10 print('%s does not exist' % filename)
- 统计行数
1 def count_line(filename): 2 try: 3 with open(filename, 'r', encoding='utf-8') as f: 4 lines = f.readlines() 5 return len(lines) 6 except FileNotFoundError: 7 print('%s does not exist' % filename)
- 递归处理目录
1 def count_dir(dirname): 2 try: 3 for x in os.listdir(dirname): 4 if os.path.isdir(dirname + '\' + x): #调用os模块判断当前文件是否是目录 5 count_dir(dirname + '\' + x) #若是目录则递归处理此目录 6 elif os.path.isfile(dirname + '\' + x) and os.path.splitext(dirname + '\' + x)[1] == '.c': #若是文件且后缀名为.c则处理 7 print(dirname + '\' + x, '字符数, 词数, 行数: ', end='') 8 print(count_char(dirname + '\' + x), count_word(dirname + '\' + x), count_line(dirname + '\' + x)) 9 except FileNotFoundError: 10 print('%s does not exist' % dirname)
- 统计代码行,空行,注释行
1 def count_all(filename): 2 codeline = 0 3 expline = 0 4 blankline = 0 5 try: 6 with open(filename, 'r', encoding='utf-8') as f: 7 while f.tell() != os.path.getsize(filename): 8 line = f.readline().strip() #处理字符串,去掉头尾空白字符 9 if line == '' or len(line) == 1: 10 blankline += 1 11 elif line.startswith('//'): 12 expline += 1 13 elif line.startswith('/*'): 14 expline += 1 15 while True: 16 temp = f.readline().strip() 17 expline += 1 18 if temp.endswith('*/'): 19 break 20 else: 21 codeline += 1 22 return blankline, codeline, expline 23 except FileNotFoundError: 24 print('%s does not exist' % filename)
-
主函数
1 if __name__ == '__main__': 2 choice = sys.argv[1] #通过sys模块读取命令行参数 3 filename = sys.argv[2] 4 if choice == '-c': 5 print('字符数: ', count_char(filename)) 6 elif choice == '-w': 7 print('词数: ', count_word(filename)) 8 elif choice == '-l': 9 print('行数: ', count_line(filename)) 10 elif choice == '-s': 11 count_dir(filename) 12 elif choice == '-a': 13 blankline, codeline, expline = count_all(filename) 14 print('空行: ', blankline) 15 print('代码行: ', codeline) 16 print('注释行: ', expline)
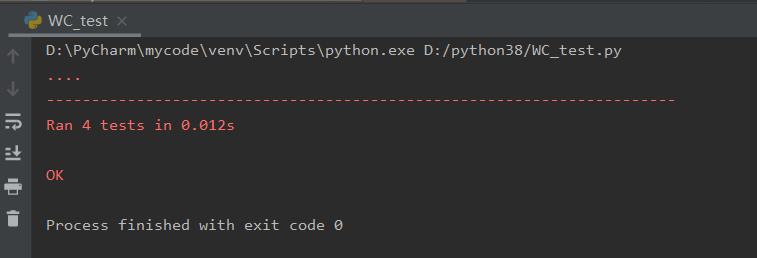
五、单元测试
import WC
import unittest
class TestWc(unittest.TestCase):
def test_count_char(self):
self.assertEqual(WC.count_char('testchar.c'), 36)
self.assertEqual(WC.count_char('testword.c'), 44)
self.assertEqual(WC.count_char('testline.c'), 20)
def test_count_word(self):
self.assertEqual(WC.count_word('testchar.c'), 6)
self.assertEqual(WC.count_word('testword.c'), 8)
self.assertEqual(WC.count_word('testline.c'), 2)
def test_count_line(self):
self.assertEqual(WC.count_line('testchar.c'), 2)
self.assertEqual(WC.count_line('testword.c'), 4)
self.assertEqual(WC.count_line('testline.c'), 8)
def test_count_all(self):
self.assertEqual(WC.count_all('test.c'), (4,3,4))
self.assertEqual(WC.count_all('test2.c'), (1,2,1))
if __name__ == '__main__':
unittest.main()
六、运行结果



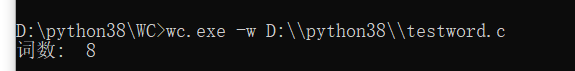



七、PSP记录表
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
20 |
25 |
|
· Estimate |
· 估计这个任务需要多少时间 |
20 |
25 |
|
Development |
开发 |
300 |
360 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
30 |
40 |
|
· Design Spec |
· 生成设计文档 |
10 |
15 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 |
15 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 |
10 |
|
· Design |
· 具体设计 |
30 |
40 |
|
· Coding |
· 具体编码 |
120 |
140 |
|
· Code Review |
· 代码复审 |
30 |
20 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 |
80 |
|
Reporting |
报告 |
20 |
25 |
|
· Test Report |
· 测试报告 |
5 |
10 |
|
· Size Measurement |
· 计算工作量 |
10 |
10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
5 |
5 |
|
合计 |
340 |
410 |
八、项目小结
通过PSP表格去预测和记录自己的开发时间,对于整个项目流程有了更清晰的认识。实际的开发时间总是比预测的开发时间多一些,主要是因为在开发过程中会遇到一些未知的错误。
通过这个项目也认识到自己对一些常用的内置函数还不够熟悉,日后有待继续加强对一些内置函数的熟练掌握
第一次学习使用单元测试,单元测试未能全面覆盖代码,日后有待继续加强对单元测试的学习
未能实现GUI编程,希望尽快学习这个知识盲区。