| docker网络模式 | 配置 | 说明 |
| host模式 | -net=host | 容器与宿主机共享network namespace |
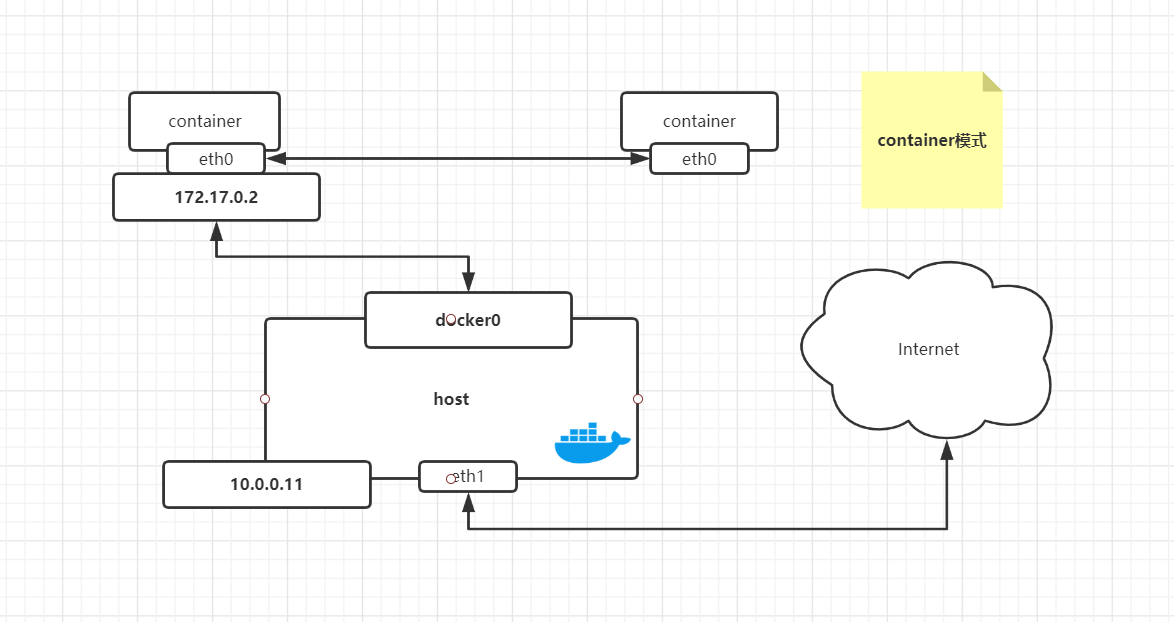
| container模式 | -net=container:NAME_or_ID | 容器和另外一个容器共享network namespace。kubernetes中的pod 就是多个容器共享一个network namespace |
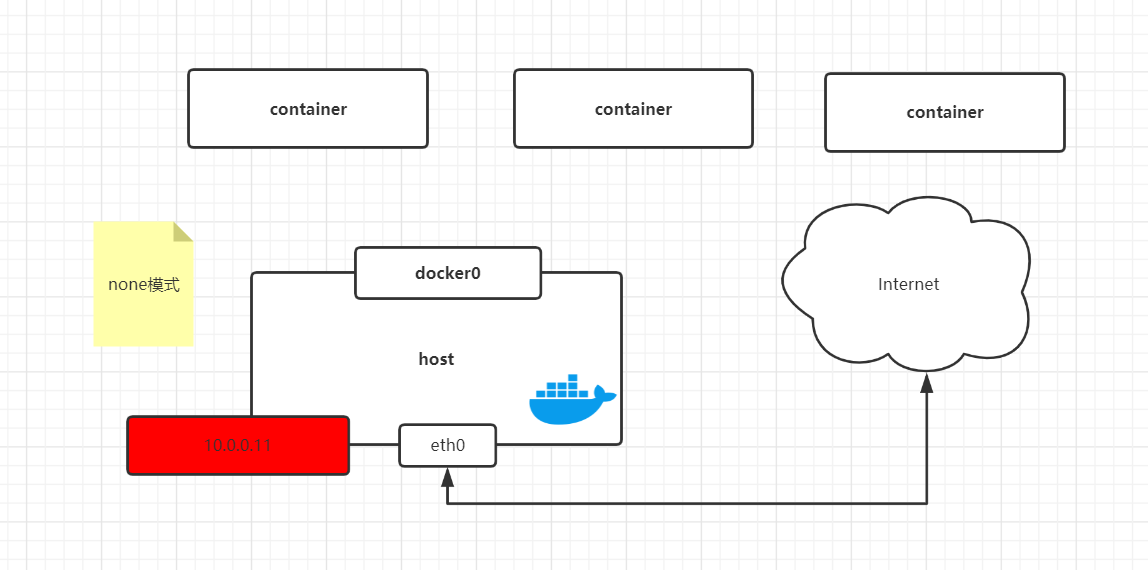
| none模式 | -net=none | 容器有独立的network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥离连接,配置IP等。 |
| bridge模式 | -net=bridge |
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好。
host模式示意图:

实例演示:
#创建一个容器加host网络 docker run -it --network=host alpine:v1 /bin/sh / # hostname docker01 <--主机名 / # cat /etc/hosts <--宿主机的hosts文件 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 docker01 10.0.0.11 docker02 10.0.0.12 / # ip a <--宿主机的ip地址
实例演示:
docker run -it --network container:clever_carson /bin/sh / # ip a <--与别的主机共用一个网络 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 456: eth0@if457: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
这样网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。这种类型的网络没有办法连网,封闭的网络能很好的保证容器的安全性。
None模式示意图:
实例演示:
docker run -it --network none alpine:v1 /bin/sh / # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever <--没有网卡
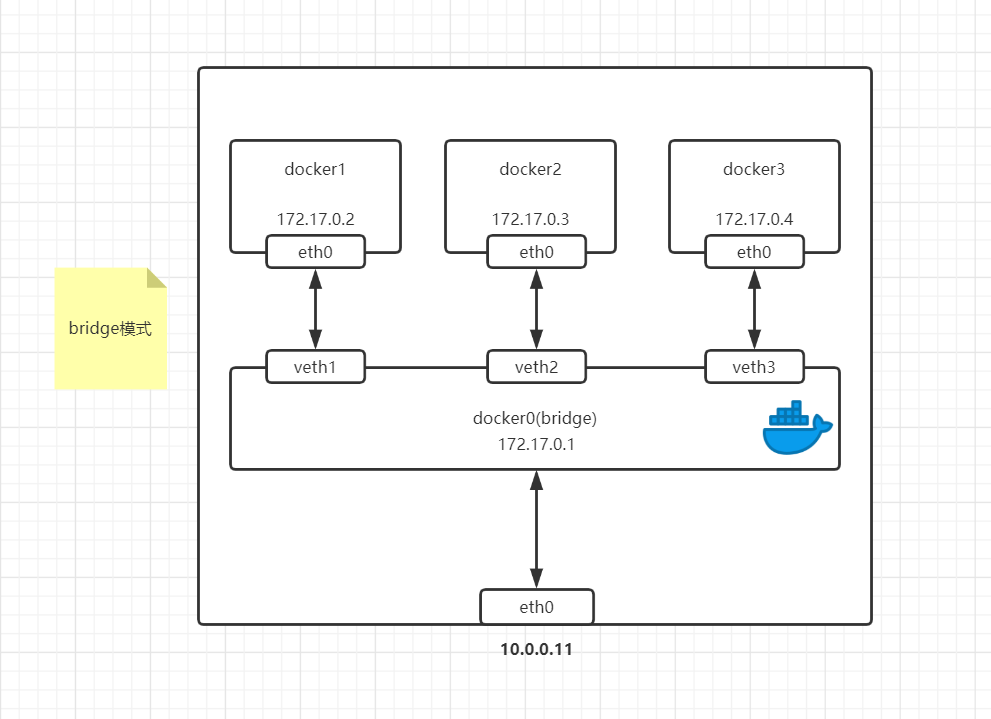
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连接在了一个二层网络中。
从docker0子网中分配一个ip给容器使用,并设置docker的IP地址为容器的默认网关。在关机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show查看。
bridge模式是docker的默认模式,不写-net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转换功能。可以使用iptables -t net -vnL 查看。
桥架网络示意图:
#自定义一个网络 docker network create -d bridge --gateway 172.19.0.1 --subnet 172.19.0.0/16 class # 查看网络列表 docker network ls eb5611ce0e24 class bridge local #容器使用自定义网络 docker run -d -p 81:80 --network class alpine_kod:v3 /bin/sh /init.sh #查看类型 docker inspect 82aee49 | grep Network "NetworkMode": "class", "NetworkSettings": { "Networks": { "NetworkID": "eb5611ce0e24c93301ddbd18c9cc2d9c54943119fc9a8ba0b8a9590df7804bb7",
macvlan类似于虚拟机的桥接网络
-
跨宿主机通信(ping不同宿主机)
-
需要手动管理ip分配
-
不需要端口映射就能被外界访问
注:macvlan最大特点ip地址需要手动添加
# 创建网络 docker network create -d macvlan --subnet 10.0.0.0/24 --gateway 10.0.0.254 -o parent=eth0 macvlan_1 # 参数说明 -d:网络类型(macvlan) --subnet:指定子网范围 --gateway:宿主机网关 -o parent=eth0:基于哪个网卡创建 macvlan_1:网卡名称 # 查看 docker network ls
使用macvlan模式创建容器:
#docker01 docker run -it --network macvlan_1 --ip 10.0.0.88 alpine:v1 / # ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 481: eth0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN link/ether 02:42:0a:00:00:58 brd ff:ff:ff:ff:ff:ff inet 10.0.0.88/24 brd 10.0.0.255 scope global eth0 valid_lft forever preferred_lft forever #docker02 docker run -it --netwrok macvlan_1 --ip 10.0.0.99 alpine:v1 / # ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 19: eth0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN link/ether 02:42:0a:00:00:63 brd ff:ff:ff:ff:ff:ff inet 10.0.0.99/24 brd 10.0.0.255 scope global eth0 valid_lft forever preferred_lft forever
注:这里即可以互相ping通而且还可以ping百度
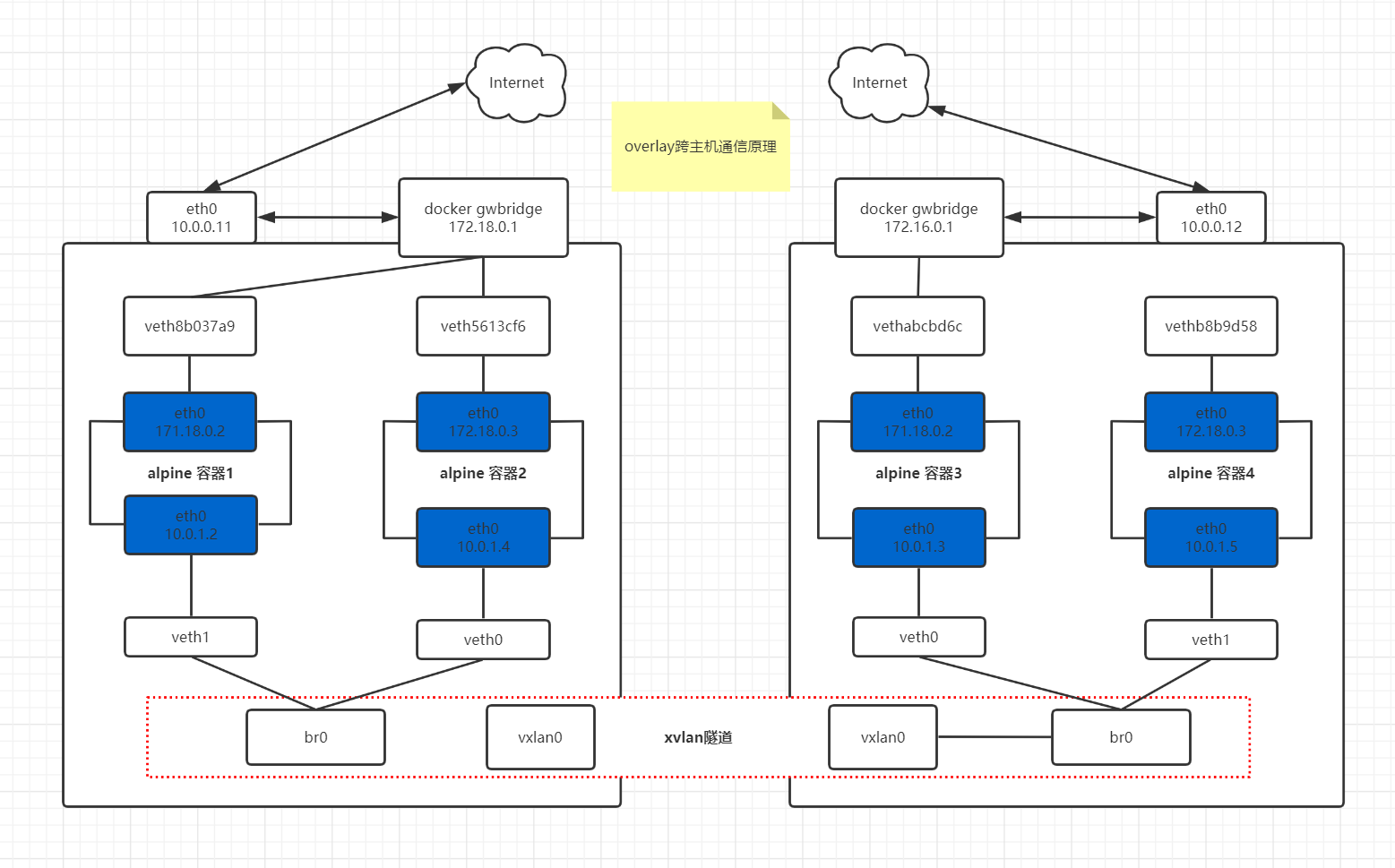
因此,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案
2. 要想使用Docker源生Overlay网络,需要满足下列任意条件:
3. 使用键值存储搭建docker主机集群
需要满足下列条件:
-
集群中主机连接到键值存储,Docker支持 Consul,Etcd和Zookeeper
-
集群中运行一个Docker守护进程
-
集群中主机必须具有唯一的主机名,因为键值存储使用主机名来标识集群成员、
-
集群中Linux主机内核版本在3.12+,支持VXLAN数据报处理,否则可能无法通行
4. 实验
| ip地址 | kernel | |
| docker01 | 10.0.0.11 | 3.10.0-957.el7.x86_64 |
| docker02 | 10.0.0.12 | 3.10.0-957.el7.x86_64 |
| docker03 | 10.0.0.13 |
注:我们这里实验使用的是Consul
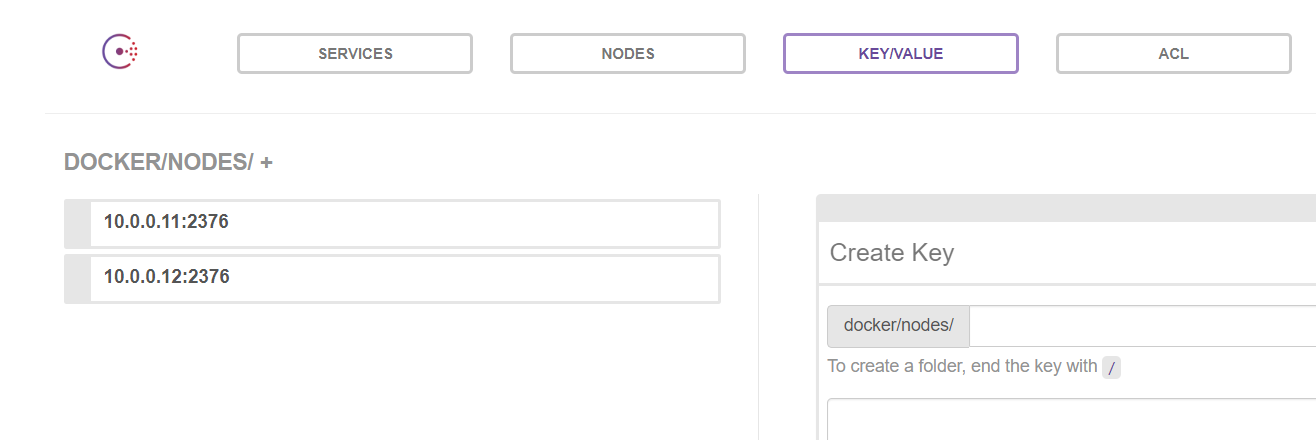
#docker03主机 [root@docker03 ~]# docker pull progrium/consul <---拉取镜像 [root@docker03 ~]# docker run -d -p 8500:8500 -h consul --name consul progrium/consul -server -bootstrap 登录:10.0.0.13:8500 #docker01和02主机 vim /etc/docker/daemon.json 8 "insecure-registries": ["10.0.0.11:5000","10.0.0.12"], 9 "cluster-store": "consul://10.0.0.13:8500", #集群信息存储在consul上 10 "cluster-advertise": "10.0.0.11:2376" #节点自己的信息
效果图:
测试跨主机实例:
#docker01创建容器 docker run -it --network ol1 --name class1 alpine:latest #docker02创建容器 docker run -it --network ol1 --name class2 alpine:lstest 之间互相ping容器名字互通 ping class1 PING class1 (172.31.0.2): 56 data bytes 64 bytes from 172.31.0.2: seq=0 ttl=64 time=0.370 ms 64 bytes from 172.31.0.2: seq=1 ttl=64 time=0.722 ms ping class2 PING class2 (172.31.0.3): 56 data bytes 64 bytes from 172.31.0.3: seq=0 ttl=64 time=0.547 ms 64 bytes from 172.31.0.3: seq=1 ttl=64 time=0.675 ms
使用端口映射访问:
#docker01 docker run -d -p 80:80 --network ol1 --name kod01 alpine_kod:v3 #docker02 docker run -d -p 80:80 --network ol1 --name kod02 alpine_kod:v3 之间相互ping