Mahout应用(一)
Mahout 是应用于hadoop上的数据挖掘工具(废话不多说)
这里先简单介绍一下mahout的一般使用方法。
拿kmeans为列子
Mahout中的kmeans所需要的输入比较特殊需要的输入类型为VectorWritable类型并且是SequenceFile格式存储(一般来讲为了方便查看数据我比较喜欢直接用Text格式直接存储)使用SequenceFile主要是因为可压缩和数据读入速度,mahout认为我们的输出绝大多数不需要看而是为了当做以后的输入。VectorWritable的应用我们以后再说。
Mahout中有一个类叫做InputDriver是用来将输入的文件转化成VectorWritable格式,这里需要注意一下它需要的输入为Text格式存储的输出为SequenceFile格式,也就是Kmeans所需要的格式,每一行为一个Vector必须用空格分隔。

因为不知道读者的mahout版本所以我这里将用mahout.jar来代表mahout的jar包。
假设HDFS上的输入路径为input,输出为buf1 则可以使用命令行直接进行转换:
hadoop jar mahout.jar org.apache.mahout.clustering.conversion.InputDriver -i input -o buf1
这里的数据为大家截个图:
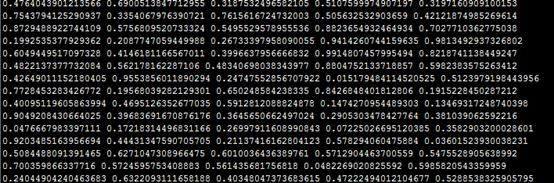
然后就可以使用mahout中的kmeans算法来进行聚类了
这里可以直接使用bin/mahout 来直接操作。
这里我们的输入是上次的输出buf1,输出为output,需要一个路径来存放聚类的中心 buf2,那么命令行代码例子为:
bin/mahout kmeans
--input buf1
--output output
-k 5
-c buf2
--maxIter 100
-cd 0.001
-dm org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure
-cl
为大家解释一下参数,input和output就不解释了,k参数意思为要聚成5类,c参数代表着聚类中心存放的位置,maxIter为最大迭代次数,cd为收敛到多少可以停止,dm为使用的距离公式,有cl参数意味着最后的输出会多一个聚类中心点clusteredPoints(这个是挺必要的为了方便查看结果建议有这个参数如果不查看结果可以没有)。
在若干次mapreduce过程后,我们来查看一下结果:
bin/mahout clusterdump
--seqFileDir output/clusters-4
--pointsDir output/clusteredPoints
--output result.txt
笔者这里迭代四次后收敛所以是clusters-4
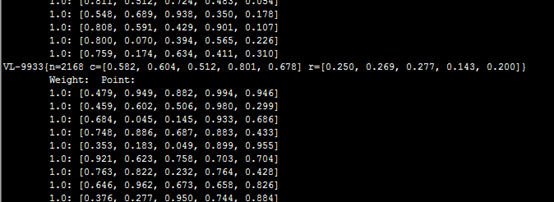
上图为结果,里面的c为中心,r为半径。
欢迎大牛拍砖以后会有其他工具和算法的介绍。