富文本编辑器
借助富文本编辑器,网站的编辑人员能够像使用offfice一样编写出漂亮的,所见即所得的页面。此处以TinyMCE的为例,其它富文本编辑器的使用也是类似的。
在虚拟环境中安装包。
pip install django-tinymce==2.6.0
安装完成后,可以使用在管理管理中,也可以自定义表单使用。
示例
1)在TEST6 / settings.py中为INSTALLED_APPS添加编辑器应用。
INSTALLED_APPS = ( ... 'tinymce', )
2)在TEST6 / settings.py中添加编辑器配置。
TINYMCE_DEFAULT_CONFIG = { 'theme': 'advanced', 'width': 600, 'height': 400, }
3)在TEST6 / urls.py中配置编辑器的URL。
urlpatterns = [ ... url(r'^tinymce/', include('tinymce.urls')), ]
在管理中使用
1)在booktest / models.py中,定义模型的属性为HTMLField()类型。
from django.db import models from tinymce.models import HTMLField class GoodsInfo(models.Model): gcontent=HTMLField()
2)生成迁移文件。
python manage.py makemigrations
3)执行迁移。
python manage.py migrate
4)在本示例中没有定义其它的模型类,但是数据库中有这些表,提示是否删除,输入没有后回车,表示不删除,因为其它的示例中需要使用这些表。
5)迁移完成,新开终端,连接的MySQL,使用TEST2数据库,查看表如下:
6)发现并没有表GoodsInfo,解决办法是删除迁移表中关于booktest应用的数据。
delete from django_migrations where app='booktest';
7)再次执行迁移。
python manage.py migrate
成功完成迁移,记得不删除没有。
8)在booktest / admin.py中注册模型类GoodsInfo
from django.contrib import admin from booktest.models import * class GoodsInfoAdmin(admin.ModelAdmin): list_display = ['id'] admin.site.register(GoodsInfo,GoodsInfoAdmin)
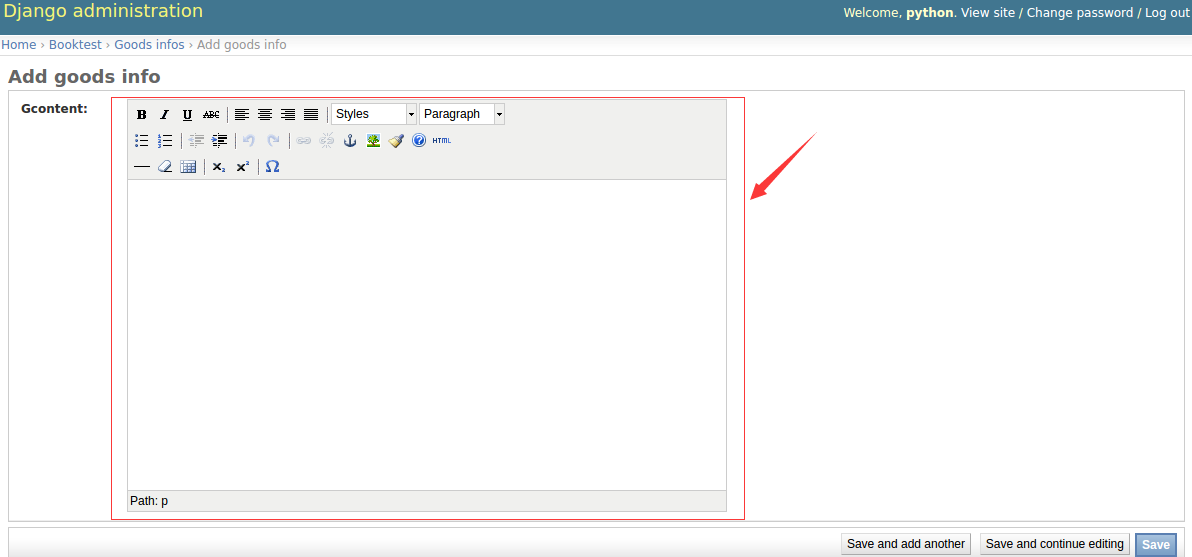
9)运行服务器,进入管理后台管理,点击GoodsInfo的添加,效果如下图
发送邮件
Django的中内置了邮件发送功能,被定义在django.core.mail模块中发送邮件需要使用SMTP服务器,常用的免费服务器有:163,126,QQ,下面以163邮件为例。
1)注册163邮箱itcast88,登录后设置。
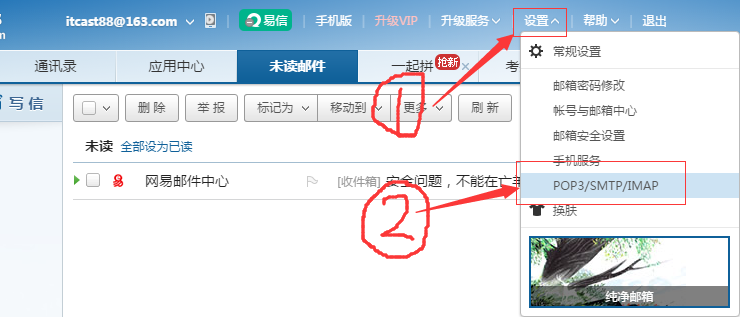
2)在新页面中点击“客户端授权密码”,勾选“开启”,弹出新窗口填写手机验证码。
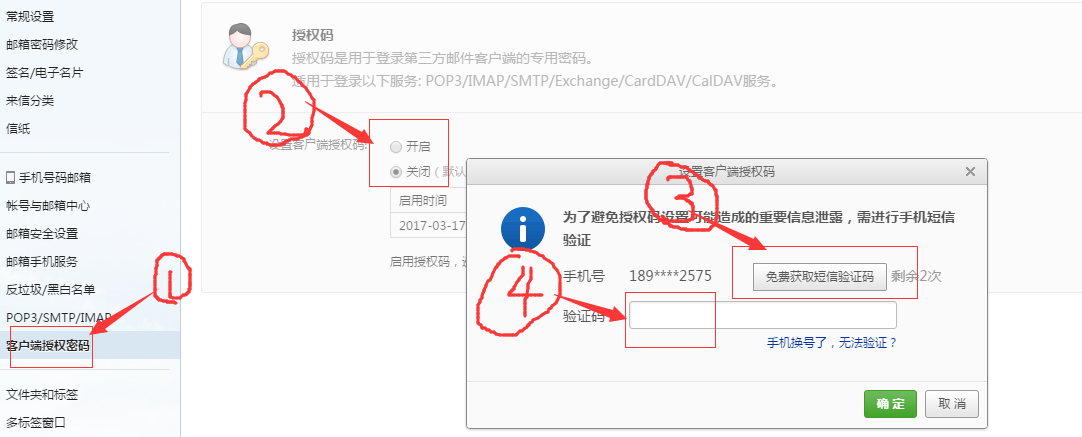
3)填写授权码。
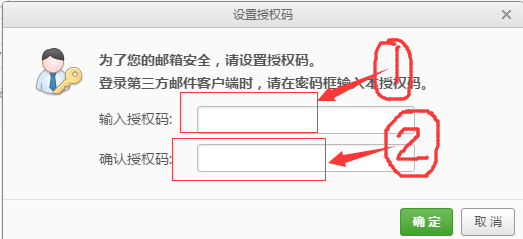
4)提示开启成功。
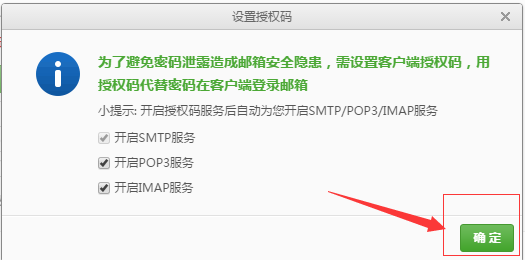
5)打开TEST6 / settings.py文件,点击下图配置。
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' EMAIL_HOST = 'smtp.163.com' EMAIL_PORT = 25 #发送邮件的邮箱 EMAIL_HOST_USER = 'itcast88@163.com' #在邮箱中设置的客户端授权密码 EMAIL_HOST_PASSWORD = 'python808' #收件人看到的发件人 EMAIL_FROM = 'python<itcast88@163.com>'
6)在booktest / views.py文件中新建视图发送。
from django.conf import settings from django.core.mail import send_mail from django.http import HttpResponse ... def send(request): msg='<a href="http://www.itcast.cn/subject/pythonzly/index.shtml" target="_blank">点击激活</a>' send_mail('注册激活','',settings.EMAIL_FROM, ['itcast88@163.com'], html_message=msg) return HttpResponse('ok')
7)在booktest / urls.py文件中配置。
url(r'^send/$',views.send),
8)启动服务器,在浏览器中输入如下网址:
http://127.0.0.1:8000/send/
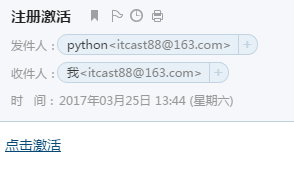
邮件发送成功后,在邮箱中查看邮件如下图:
celery
情景:用户发起request,并等待response返回。在本些views中,可能需要执行一段耗时的程序,那么用户就会等待很长时间,造成不好的用户体验,比如发送邮件、手机验证码等。
使用celery后,情况就不一样了。解决:将耗时的程序放到celery中执行。
- 点击查看celery官方网站
- 点击查看celery中文文档
celery名词:
- 任务task:就是一个Python函数。
- 队列queue:将需要执行的任务加入到队列中。
- 工人worker:在一个新进程中,负责执行队列中的任务。
- 代理人broker:负责调度,在布置环境中使用redis。
安装包:
celery==3.1.25
django-celery==3.1.17
示例
1)在booktest/views.py文件中创建视图sayhello。
import time ... def sayhello(request): print('hello ...') time.sleep(2) print('world ...') return HttpResponse("hello world")
2)在booktest/urls.py中配置。
url(r'^sayhello$',views.sayhello),
3)启动服务器,在浏览器中输入如下网址:
http://127.0.0.1:8000/sayhello/
4)在终端中效果如下图,两次输出之间等待一段时间才会返回结果。
5)在test6/settings.py中安装。
INSTALLED_APPS = ( ... 'djcelery', }
6)在test6/settings.py文件中配置代理和任务模块。
import djcelery djcelery.setup_loader() BROKER_URL = 'redis://127.0.0.1:6379/2'
7)在booktest/目录下创建tasks.py文件。
import time from celery import task @task def sayhello(): print('hello ...') time.sleep(2) print('world ...')
8)打开booktest/views.py文件,修改sayhello视图如下:
from booktest import tasks ... def sayhello(request): # print('hello ...') # time.sleep(2) # print('world ...') tasks.sayhello.delay() return HttpResponse("hello world")
9)执行迁移生成celery需要的数据表。
python manage.py migrate
10)启动Redis,如果已经启动则不需要启动。
sudo service redis start
11)启动worker。
python manage.py celery worker --loglevel=info
12)打开booktest/task.py文件,修改为发送邮件的代码,就可以实现无阻塞发送邮件。
from django.conf import settings from django.core.mail import send_mail from celery import task @task def sayhello(): msg='<a href="http://www.itcast.cn/subject/pythonzly/index.shtml" target="_blank">点击激活</a>' send_mail('注册激活','',settings.EMAIL_FROM, ['itcast88@163.com'], html_message=msg)
全文检索
全文检索不同于特定字段的模糊查询,使用全文检索的效率更高,并且能够对于中文进行分词处理。
- haystack:全文检索的框架,支持whoosh、solr、Xapian、Elasticsearc四种全文检索引擎,点击查看官方网站。
- whoosh:纯Python编写的全文搜索引擎,虽然性能比不上sphinx、xapian、Elasticsearc等,但是无二进制包,程序不会莫名其妙的崩溃,对于小型的站点,whoosh已经足够使用,点击查看whoosh文档。
- jieba:一款免费的中文分词包,如果觉得不好用可以使用一些收费产品。
1)在虚拟环境中依次安装需要的包。
pip install django-haystack
pip install whoosh
pip install jieba
2)修改test6/settings.py文件,安装应用haystack。
INSTALLED_APPS = ( ... 'haystack', )
3)在test6/settings.py文件中配置搜索引擎。
... HAYSTACK_CONNECTIONS = { 'default': { #使用whoosh引擎 'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine', #索引文件路径 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), } } #当添加、修改、删除数据时,自动生成索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
4)在test6/urls.py中添加搜索的配置。
url(r'^search/', include('haystack.urls')),
创建引擎及索引
1)在booktest目录下创建search_indexes.py文件。
from haystack import indexes from booktest.models import GoodsInfo #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return GoodsInfo def index_queryset(self, using=None): return self.get_model().objects.all()
2)在模板目录下创建 “搜索/索引/ booktest /” 目录。
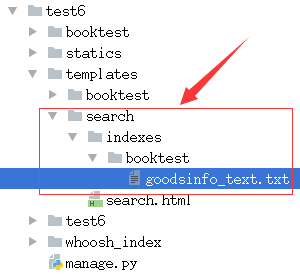
3)在上面的目录中创建 “goodsinfo_text.txt” 文件。
#指定索引的属性 {{object.gcontent}}
4)找到虚拟环境py_django下的干草堆目录。
/home/python/.virtualenvs/py_django/lib/python3.5/site-packages/haystack/backends/
5)在上面的目录中创建ChineseAnalyzer.py文件。
import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t def ChineseAnalyzer(): return ChineseTokenizer()
6)复制whoosh_backend.py文件,改为如下名称:
whoosh_cn_backend.py
7)打开复制出来的新文件,引入中文分析类,内部采用解霸分词。
from .ChineseAnalyzer import ChineseAnalyzer
8)更改词语分析类。
查找 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()
9)初始化索引数据。
python manage.py rebuild_index
10)按提示输入Ý后回车,生成索引。
11)索引生成后目录结构如下图:

使用
按照配置,在管理管理中添加数据后,会自动为数据创建索引,可以直接进行搜索,可以先创建一些测试数据。
1)在booktest / views.py中定义视图查询。
def query(request): return render(request,'booktest/query.html')
2)在booktest / urls.py中配置。
url(r'^query/', views.query),
3)在模板/ booktest /目录中创建模板query.html。
<html>
<head>
<title>全文检索</title>
</head>
<body>
<form method='get' action="/search/" target="_blank">
<input type="text" name="q">
<br>
<input type="submit" value="查询">
</form>
</body>
</html>
4)自定义搜索结果模板:在模板/搜索/目录下创建search.html。
搜索结果进行分页,视图向模板中传递的上下文如下:
- 查询:搜索关键字
- 页:当前页的页面对象
- 分页程序:分页分页程序对象
视图接收的参数如下:
- 参数q表示搜索内容,传递到模板中的数据为查询
- 参数页面表示当前页码
<html>
<head>
<title>全文检索--结果页</title>
</head>
<body>
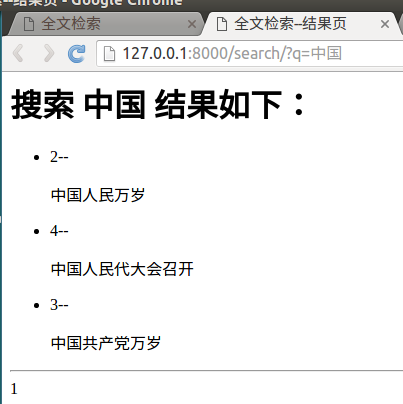
<h1>搜索 <b>{{query}}</b> 结果如下:</h1>
<ul>
{%for item in page%}
<li>{{item.object.id}}--{{item.object.gcontent|safe}}</li>
{%empty%}
<li>啥也没找到</li>
{%endfor%}
</ul>
<hr>
{%for pindex in page.paginator.page_range%}
{%if pindex == page.number%}
{{pindex}}
{%else%}
<a href="?q={{query}}&page={{pindex}}">{{pindex}}</a>
{%endif%}
{%endfor%}
</body>
</html>
5)运行服务器,在浏览器中输入如下地址:
http://127.0.0.1:8000/query/
在文本框中填写要搜索的信息,点击”搜索“按钮。
搜索结果如下: