为什么要学习requests,而不是urllib?
1.requests的底层实现就是urllib。
2.requests在python2和python3中通用,方法完全一样。
3.requests简单易用。
4.requests能够自动帮我们解压(gzip压缩等)网页内容。
在写爬虫的过程中,一定要养成一个好习惯,学会模拟浏览器的User-Agent。
如果不去模拟的话,以Python作为User-Agent去访问,会受到条件的限制。
200
b:
{'Bdpagetype': '1', 'Bdqid': '0xd1d3ed49000252f7', 'Cache-Control': 'private', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Cxy_all': 'baidu+cd213ce012eb7ff371aed51597a8d28c', 'Date': 'Mon, 07 Jan 2019 13:17:46 GMT', 'Expires': 'Mon, 07 Jan 2019 13:17:17 GMT', 'Server': 'BWS/1.1', 'Set-Cookie': 'delPer=0; path=/; domain=.baidu.com, BDSVRTM=0; path=/, BD_HOME=0; path=/, H_PS_PSSID=1425_21121_28206_28131_26350_28266_28140; path=/; domain=.baidu.com', 'Strict-Transport-Security': 'max-age=172800', 'Vary': 'Accept-Encoding', 'X-Ua-Compatible': 'IE=Edge,chrome=1', 'Transfer-Encoding': 'chunked'}
c:
https://www.baidu.com/
d:
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6814.400 QQBrowser/10.3.3005.400', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'BAIDUID=5F37B2B9D539422C5A3B8738B2D77CAE:FG=1; BIDUPSID=5F37B2B9D539422C5A3B8738B2D77CAE; PSTM=1546867066; BD_LAST_QID=16822138656381887118'}
e:
(百度源码,省略)
接下来就讲一下Get请求方式:
从服务器获取数据,最常见的一种请求方式,Get方式用于在url地址中添加一些参数完成访问。
公式:requests.get(url,headers=?,params=?,**kwargs),其中params是传递的参数,以字典的形式。
https://www.baidu.com/s?wd=%E8%8E%AB%E6%AC%BA%E5%B0%91%E5%B9%B4%E7%A9%B7
https://www.baidu.com/s?wd=%E8%8E%AB%E6%AC%BA%E5%B0%91%E5%B9%B4%E7%A9%B7
Post请求方式:
向服务器传送数据,POST请求参数在请求体中,消息长度没有限制且以隐式的方式进行发送。
在这儿,我们将百度翻译小案例来结合起来进行理解。
公式:requests.post(url,data=?,headers=?,json=?,**kwargs),data是需要传递进去的参数,同样是以参数的形式传递。
所以看到公式,我们寻找的目标自然是data参数了,get的请求方式是在url上显示,但post的请求方式却隐藏在请求中。
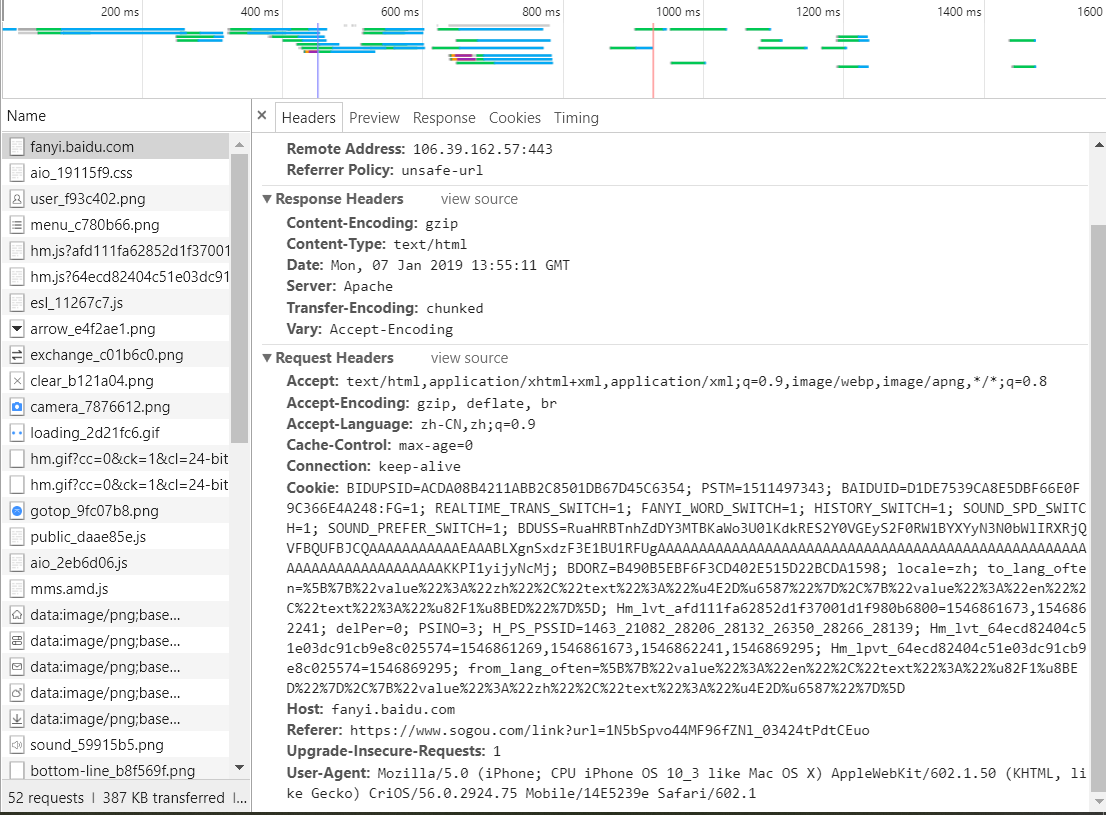
我们在主体网页中,并没有发现有效的data字典参数,所以我们要往下寻找其他基础板块。
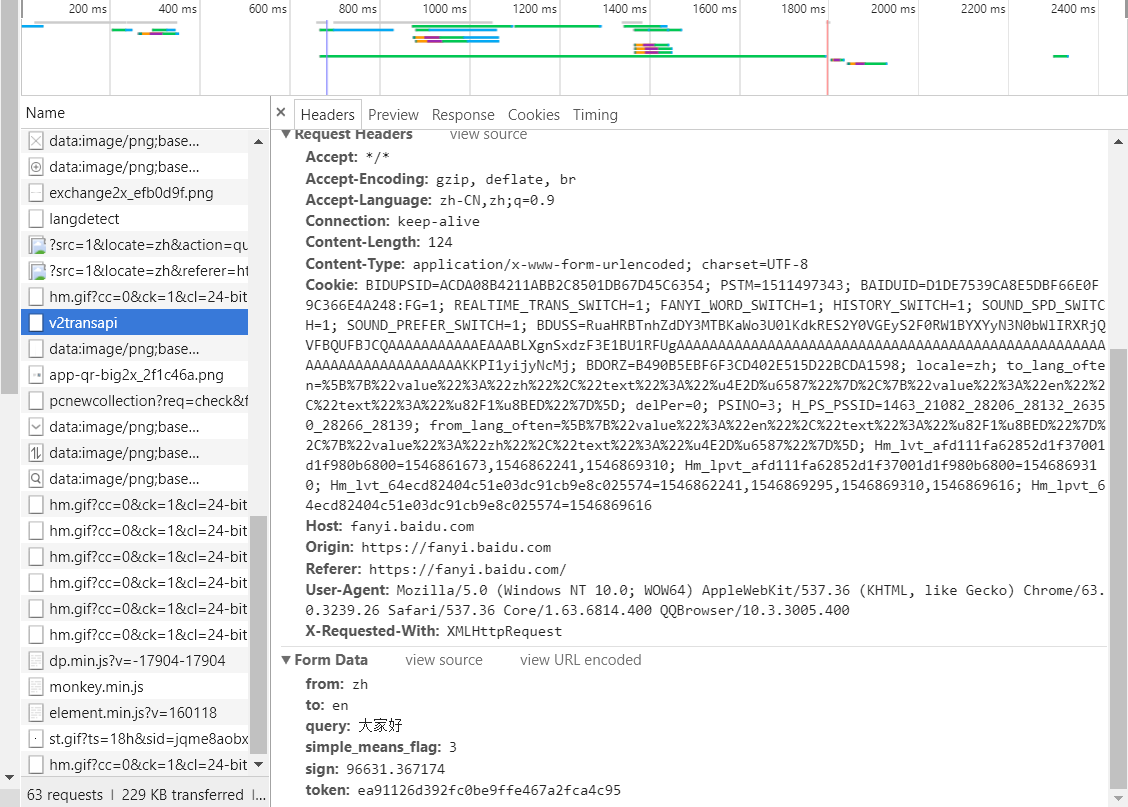
我们找到了要找的一个目标,在v2transapi中发现了一个有效的DATA字典参数,这个时候我们需要检查参数的可用性,
确保后续翻译功能的完美实现,为了验证唯一性,我将换一句话翻译:
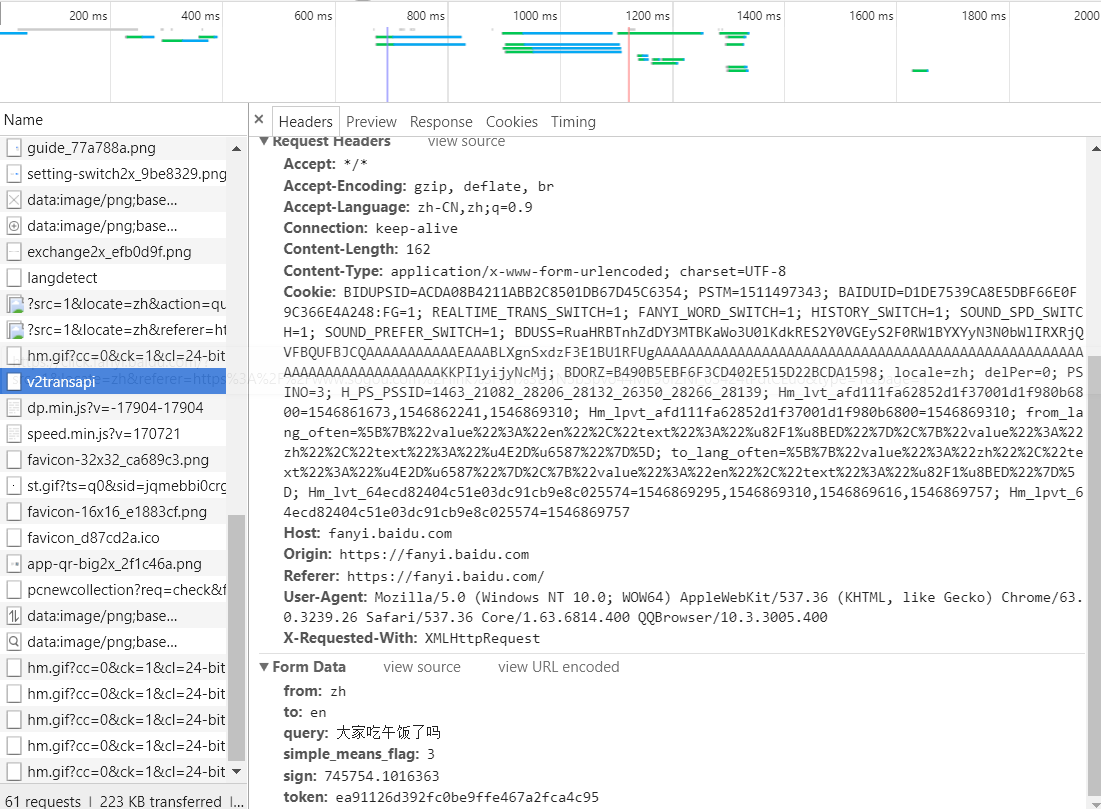
我们可以发现,sign发生了改变,并非唯一性参数,说明这个data字典参数并不适合。
为了解决这个问题,我们将操作系统从windows电脑切换到ipone X手机,然后继续寻找data参数:
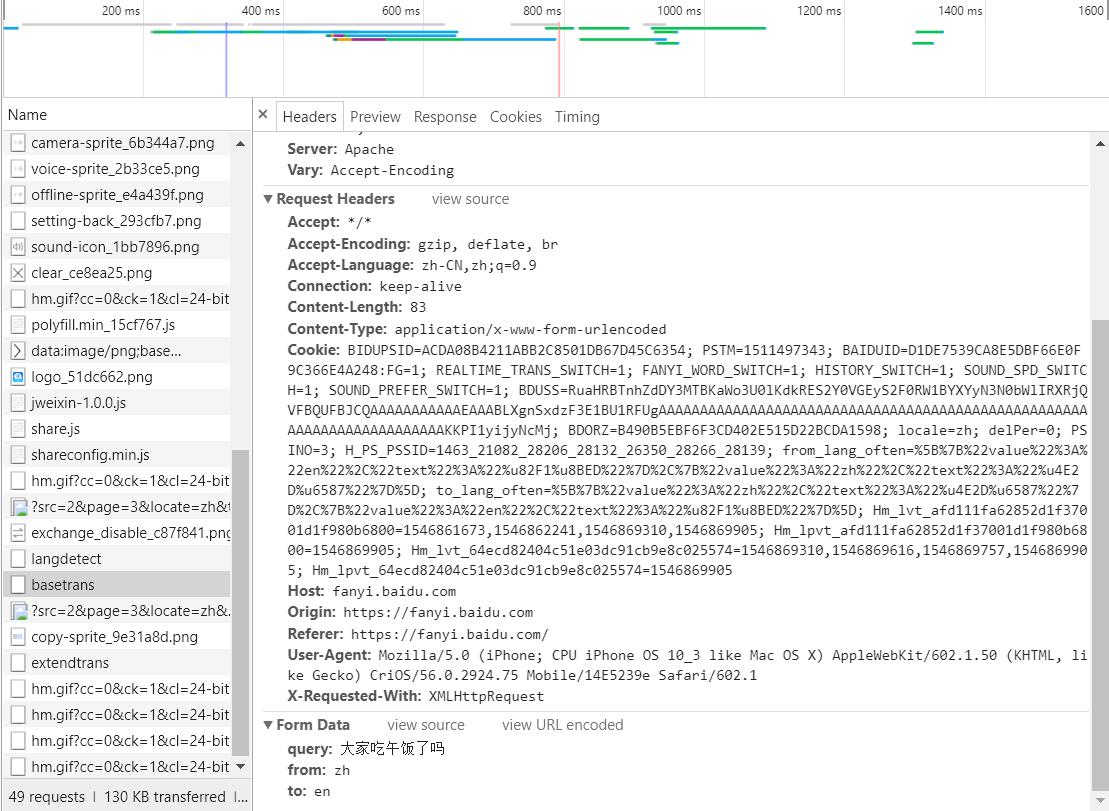
我们惊喜地发现,这个时候data参数具备了唯一性,是在basetrans文件里寻找到的。
所以我们就从这个iponeX操作系统中获取到需要的参数,完成翻译功能。
于是有了url地址,data字典,以及必要的json转换(将json文本转换为Python文本),代码就生成了:
输出结果(加粗的部分为键入的内容):
请输入你要翻译的汉字:大家吃晚饭了吗
Have you had dinner yet?
这样,我们就完成了对百度翻译的爬虫,并爬来翻译功能进行使用。
建议大家多去看看相关的资料,彻底理解一下Get与Post的两种请求方式。