RPC 框架设计 - ice_image - 博客园 (cnblogs.com)
(29 封私信) grpc - 搜索结果 - 知乎 (zhihu.com)
现代服务端技术栈介绍 —— Golang、Protobuf 和 gRPC - 知乎 (zhihu.com)
帮你节省一半时间的gRPC入门指南 - 知乎 (zhihu.com)
(29 封私信) rpc面试题 - 搜索结果 - 知乎 (zhihu.com)
RPC是Remote Procedure Call Protocol单词首字母的缩写,简称为:RPC,翻译成中文叫远程过程调用协议。
所谓远程过程调用,通俗的理解就是可以在本地程序中调用运行在另外一台服务器上的程序的功能方法。这种调用的过程跨越了物理服务器的限制,是在网络中完成的,在调用远端服务器上程序的过程中,本地程序等待返回调用结果
,直到远端程序执行完毕,将结果进行返回到本地,最终完成一次完整的调用
需要强调的是:远程过程调用指的是调用远端服务器上的程序的方法整个过程。
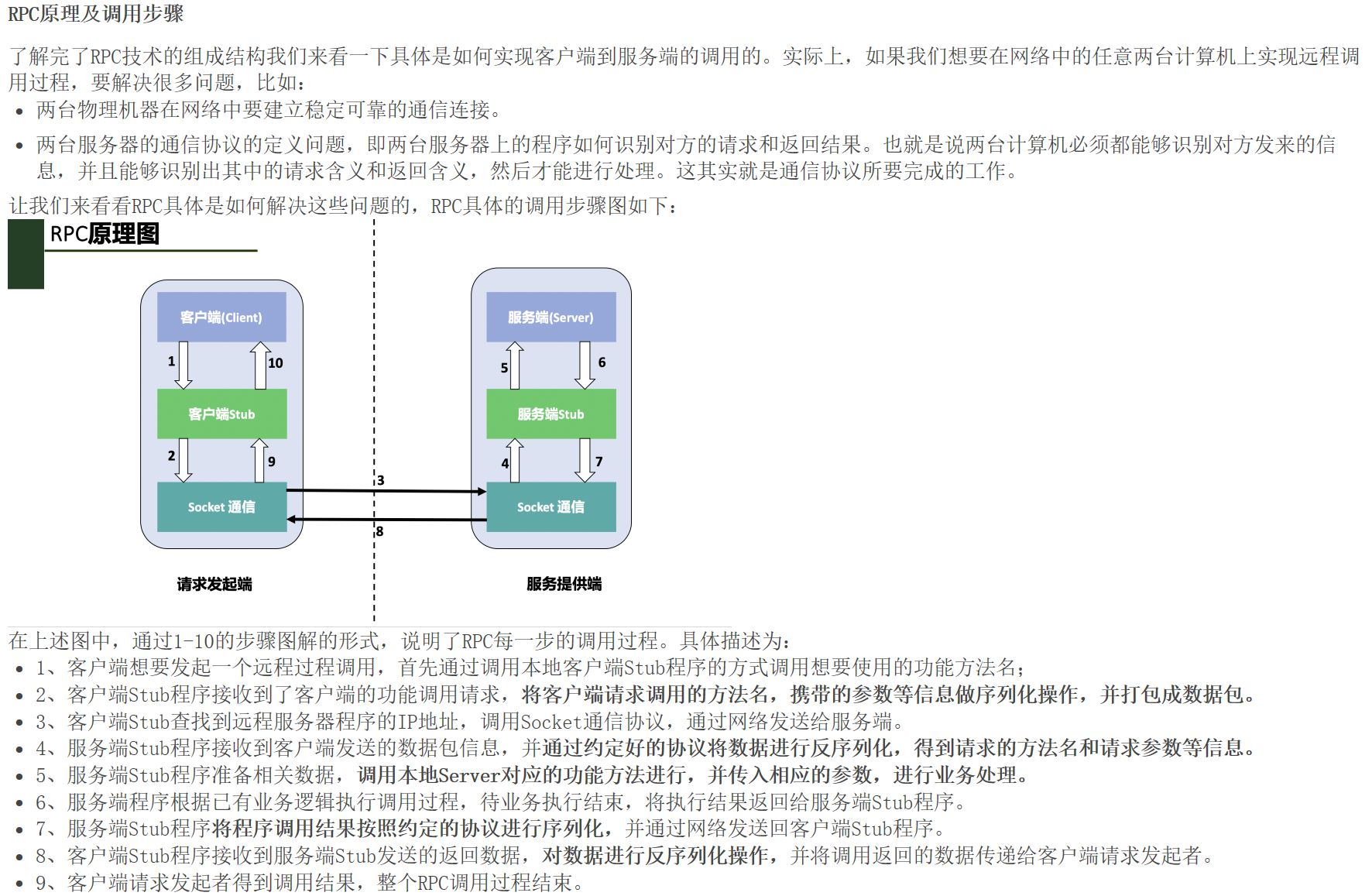
RPC设计组成
RPC技术在架构设计上有四部分组成,分别是:客户端、客户端存根、服务端、服务端存根。
这里提到了客户端和服务端的概念,其属于程序设计架构的一种方式,在现代的计算机软件程序架构设计上,大方向上分为两种方向,分别是:B/S架构、C/S架构。B/S架构指的是浏览器到服务器交互的架构方式,另外一种是在计算机上安装一个单独的应用,称之为客户端,与服务器交互的模式。
由于在服务的调用过程中,有一方是发起调用方,另一方是提供服务方。因此,我们把服务发起方称之为客户端,把服务提供方称之为服务端。
以下是对RPC的四种角色的解释和说明:
- • 客户端(Client):服务调用发起方,也称为服务消费者。
- • 客户端存根(Client Stub):该程序运行在客户端所在的计算机机器上,主要用来存储要调用的服务器的地址,另外,该程序还负责将客户端请求远端服务器程序的数据信息打包成数据包,通过网络发送给服务端Stub程序;其次,还要接收服务端Stub程序发送的调用结果数据包,并解析返回给客户端。
- • 服务端(Server):远端的计算机机器上运行的程序,其中有客户端要调用的方法。
- • 服务端存根(Server Stub):接收客户Stub程序通过网络发送的请求消息数据包,并调用服务端中真正的程序功能方法,完成功能调用;其次,将服务端执行调用的结果进行数据处理打包发送给客户端Stub程序。
RPC涉及到的相关技术
通过上文一系列的文字描述和讲解,我们已经了解了RPC的由来和RPC整个调用过程。我们可以看到RPC是一系列操作的集合,其中涉及到很多对数据的操作,以及网络通信。因此,我们对RPC中涉及到的技术做一个总结和分析:
- 1、动态代理技术: 上文中我们提到的Client Stub和Sever Stub程序,在具体的编码和开发实践过程中,都是使用动态代理技术自动生成的一段程序。
- 2、序列化和反序列化: 在RPC调用的过程中,我们可以看到数据需要在一台机器上传输到另外一台机器上。在互联网上,所有的数据都是以字节的形式进行传输的。而我们在编程的过程中,往往都是使用数据对象,因此想要在网络上将数据对象和相关变量进行传输,就需要对数据对象做序列化和反序列化的操作。
- 序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。
RPC 通信
对于单独部署,独立运行的微服务实例而言,在业务需要时,需要与其他服务进行通信,这种通信方式是进程之间的通讯方式(inter-process communication,简称IPC)。
前文已经描述过,IPC有两种实现方式,分别为:同步过程调用、异步消息调用。在同步过程调用的具体实现中,有一种实现方式为RPC通信方式,远程过程调用(英语:Remote Procedure Call,缩写为 RPC)。
远程过程调用(英语:Remote Procedure Call,缩写为RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。如果涉及的软件采用面向对象编程,那么远程过程调用亦可称作远程调用或远程方法调用,例:Java RMI。简单地说就是能使应用像调用本地方法一样的调用远程的过程或服务。很显然,这是一种client-server的交互形式,调用者(caller)是client,执行者(executor)是server。典型的实现方式就是request–response通讯机制。
RPC 实现步骤
一个正常的RPC过程可以分为一下几个步骤:
• 1、client调用client stub,这是一次本地过程调用。
• 2、client stub将参数打包成一个消息,然后发送这个消息。打包过程也叫做marshalling。
• 3、client所在的系统将消息发送给server。
• 4、server的的系统将收到的包传给server stub。
• 5、server stub解包得到参数。 解包也被称作 unmarshalling。
• 6、server stub调用服务过程。返回结果按照相反的步骤传给client。
在上述的步骤实现远程接口调用时,所需要执行的函数是存在于远程机器中,即函数是在另外一个进程中执行的。因此,就带来了几个新问题:
• 1、Call ID映射。远端进程中间可以包含定义的多个函数,本地客户端该如何告知远端进程程序调用特定的某个函数呢?因此,在RPC调用过程中,所有的函数都需要有一个自己的ID。开发者在客户端(调用端)和服务端(被调用端)分别维护一个{函数<–>Call ID}的对应表。两者的表不一定完全相同,但是相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,调用者通过映射表查询想要调用的函数的名称,找到对应的Call ID,然后传递给服务端,服务端也通过查表,来确定客户端所需要调用的函数,然后执行相应函数的代码。
• 2、序列化与反序列化。客户端如何把参数传递给远程调用的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
• 3、网络传输。远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传递给服务端,然后在把序列化后的调用结果传回给客户端,完成这种数据传递功能的被成为传输层。大部分的网络传输成都使用TCP协议,属于长连接。
在上述步骤实现中,可以看到其中有对传递的数据进行序列化和反序列化的操作,这就是我们本节内容开始要学习的内容:
Protobuf
简介
Google Protocol Buffer( 简称 Protobuf)是Google公司内部的混合语言数据标准,他们主要用于RPC系统和持续数据存储系统。
Protobuf应用场景
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或RPC数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
简单来说,Protobuf的功能类似于XML,即负责把某种数据结构的信息,以某种格式保存起来。主要用于数据存储、传输协议等使用场景。
为什么已经有了XLM,JSON等已经很普遍的数据传输方式,还要设计出Protobuf这样一种新的数据协议呢?
Protobuf 优点
• 性能好/效率高
○ 时间维度:采用XML格式对数据进行序列化时,时间消耗上性能尚可;对于使用XML格式对数据进行反序列化时的时间花费上,耗时长,性能差。
○ 空间维度:XML格式为了保持较好的可读性,引入了一些冗余的文本信息。所以在使用XML格式进行存储数据时,也会消耗空间。
整体而言,Protobuf以高效的二进制方式存储,比XML小3到10倍,快20到100倍。
• 代码生成机制
○ 代码生成机制的含义
在Go语言中,可以通过定义结构体封装描述一个对象,并构造一个新的结构体对象。比如定义Person结构体,并存放于Person.go文件:
type Person struct{
Name string
Age int
Sex int
}
在分布式系统中,因为程序代码时分开部署,比如分别为A、B。A系统在调用B系统时,无法直接采用代码的方式进行调用,因为A系统中不存在B系统中的代码。因此,A系统只负责将调用和通信的数据以二进制数据包的形式传递给B系统,由B系统根据获取到的数据包,自己构建出对应的数据对象,生成数据对象定义代码文件。这种利用编译器,根据数据文件自动生成结构体定义和相关方法的文件的机制被称作代码生成机制。
○ 代码生成机制的优点
首先,代码生成机制能够极大解放开发者编写数据协议解析过程的时间,提高工作效率;其次,易于开发者维护和迭代,当需求发生变更时,开发者只需要修改对应的数据传输文件内容即可完成所有的修改。
• 支持“向后兼容”和“向前兼容”
○ 向后兼容:在软件开发迭代和升级过程中,"后"可以理解为新版本,越新的版本越靠后;而“前”意味着早起的版本或者先前的版本。向“后”兼容即是说当系统升级迭代以后,仍然可以处理老版本的数据业务逻辑。
○ 向前兼容:向前兼容即是系统代码未升级,但是接受到了新的数据,此时老版本生成的系统代码可以处理接收到的新类型的数据。
支持前后兼容是非常重要的一个特点,在庞大的系统开发中,往往不可能统一完成所有模块的升级,为了保证系统功能正常不受影响,应最大限度保证通讯协议的向前兼容和向后兼容。
• 支持多种编程语言
Protobuf不仅仅Google开源的一个数据协议,还有很多种语言的开源项目实现。在Google官方发布的Protobuf的源代码中包含了C++、Java、Python三种语言。本系列课程中,我们学习如何实现Golang语言中的功能实现。
Protobuf 缺点
• 可读性较差
为了提高性能,Protobuf采用了二进制格式进行编码。二进制格式编码对于开发者来说,是没办法阅读的。在进行程序调试时,比较困难。
• 缺乏自描述
诸如XML语言是一种自描述的标记语言,即字段标记的同时就表达了内容对应的含义。而Protobuf协议不是自描述的,Protobuf是通过二进制格式进行数据传输,开发者面对二进制格式的Protobuf,没有办法知道所对应的真实的数据结构,因此在使用Protobuf协议传输时,必须配备对应的proto配置文件。
1 Protocol Buffers 简介
protobuf 即 Protocol Buffers,是一种轻便高效的结构化数据存储格式,与语言、平台无关,可扩展可序列化。protobuf 性能和效率大幅度优于 JSON、XML 等其他的结构化数据格式。protobuf 是以二进制方式存储的,占用空间小,但也带来了可读性差的缺点。protobuf 在通信协议和数据存储等领域应用广泛。例如著名的分布式缓存工具 Memcached 的 Go 语言版本groupcache 就使用了 protobuf 作为其 RPC 数据格式。
Protobuf 在 .proto 定义需要处理的结构化数据,可以通过 protoc 工具,将 .proto 文件转换为 C、C++、Golang、Java、Python 等多种语言的代码,兼容性好,易于使用。
