为什么需要词向量?
众所周知,不管是机器学习还是深度学习本质上都是对数字的数字,Word Embedding(词嵌入)做的事情就是将单词映射到向量空间里,并用向量来表示
一个简单的对比
- One-hot Vector
对应的词所在的位置设为1,其他为0;
例如:King, Queen, Man and Woman这句里面Queen对应的向量就是([0,1,0,0])
不足:难以发现词之间的关系,以及难以捕捉句法(结构)和语义(意思)之间的关系
- Word2Vec
基本思想是把每个词表征为(K)维的实数向量(每个实数都对应着一个特征,可以是和其他单词之间的联系),将相似的单词分组映射到向量空间的不同部分。也就是Word2Vec能在没有人为干涉下学习到单词之间的关系。
举个最经典的例子:
king- man + woman = queen
实际上的处理是:从king提取了maleness的含义,加上了woman具有的femaleness的意思,最后答案就是queen.
借助表格来理解就是:
| animal | pet | |
|---|---|---|
| dog | -0.4 | 0.02 |
| lion | 0.2 | 0.35 |
比如,animal那一列表示的就是左边的词与animal这个概念的相关性
两个重要模型
-
原理:拥有差不多上下文的两个单词的意思往往是相近的
-
Continuous Bag-of-Words(CBOW)
-
功能:通过上下文预测当前词出现的概率
-
BOW的思想:(v(“a b c”)=1/3( v(“a”) + v(“b”) + v(“c”) ))
-
原理分析
假设文本如下:“the florid prose of the nineteenth century.”
想象有个滑动窗口,中间的词是关键词,两边为相等长度(m,是超参数)的文本来帮助分析。文本的长度为7,就得到了7个one-hot向量,作为神经网络的输入向量,训练目标是:最大化在给定前后文本7情况下输出正确关键词的概率,比如给定("prose","of","nineteenth","century")的情况下,要最大化输出"the"的概率,用公式表示就是(P("the"|("prose","of","nineteenth","century")))
-
特性
- hidden layer只是将权重求和,传递到下一层,是线性的
-
-
Skip-gram
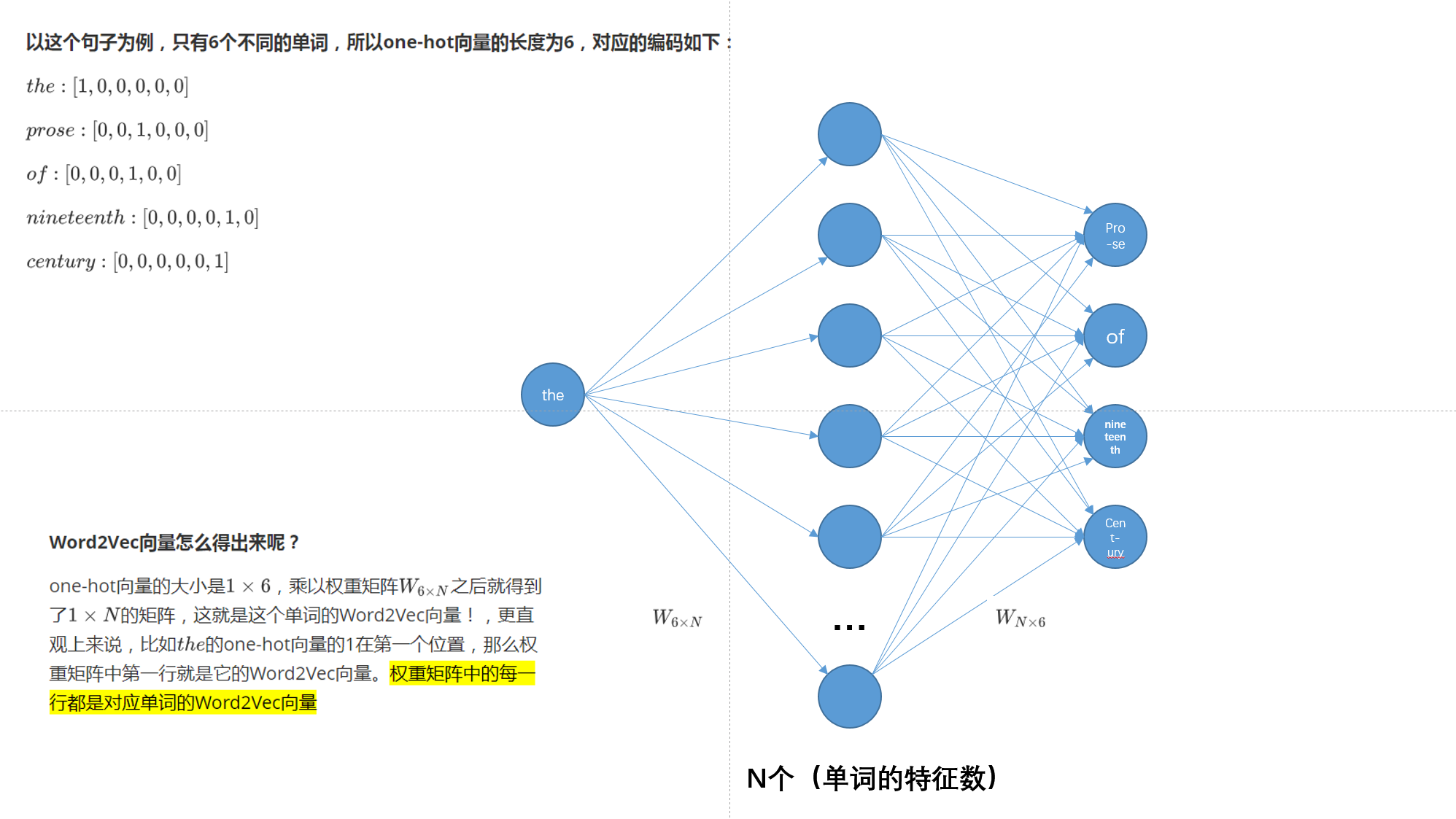
-
功能:根据当前词预测上下文
-
原理分析
- 和CBOW相反,则我们要求的概率就变为(P(Context(w)|w))
- 以上面的句子为例,数据集的构成(,(input,output))就是((the, prose), (the, of), (the,nineteenth), (the, century))
-
损失函数
- 如果假设当前词为(w),那么可以写成(P(w_{t+j}|w_t)(-m<=j<=m,j e0)),每个词都会有一个概率,训练的目标就是最大化这些概率的乘积
- 也就是:(L( heta )=prod_{(-mleq jleq m,j eq0)}P(w_{t+j}|w_t; heta)),表示准确度,要最大化
- 在概率中也经常有:(J( heta)=-frac{1}{T}logL( heta)=-frac{1}{T}sum^T_{t=1} sum log(P(w_{t+j}|w_t; heta))),加个负号就改成最小
- 概率示意(P(o|c)=frac{exp(u_o^Tv_c)}{sum^v_{w=1}exp(u_w^Tv_c)})
- (v_c):当(c)为中心词时用(v)
- (u_c):当(c)在(Context)里时用(u)
-
优点
- 在数据集比较大的时候结果更准确
-
不足
- 词的顺序不重要,并没有考虑到中文的语法
- 一词多义:比如tie的意思有很多个,要如何聚类,可以分出tie-1,tie-2等
代码
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
import requests
warnings.filterwarnings(action='ignore')
import gensim
from gensim.models import Word2Vec
#爬取alice.txt文档
sample = requests.get("http://www.gutenberg.org/files/11/11-0.txt")
s = sample.text
#将换行符变为空格
f = s.replace("
", " ")
data = [] #存储的是单词表
#迭代文本中的每一句话
for i in sent_tokenize(f):
temp = []
#将句子进行分词
for j in word_tokenize(i):
temp.append(j.lower()) #存储的的时候全变为小写
data.append(temp)
#创建CBOW模型
model1 = gensim.models.Word2Vec(data, min_count=1,size=200, window=7) #忽略出现次数小于1的词,size是每个单词的词向量的维度
#输出结果
print("Cosine similarity between 'alice' " + "and 'wonderland' - CBOW : ", model1.similarity('alice', 'wonderland')) #计算两个单词之间的余弦距离,返回相似度
print("Cosine similarity between 'alice' " + "and 'machines' - CBOW : ", model1.similarity('alice', 'machines'))
#创建Skip-Gram模型
model2 = gensim.models.Word2Vec(data, min_count=1, size=200, window=7, sg=1) #sg=1说明使用的是Skip-gram模型
#输入结果
print("Cosine similarity between 'alice' " + "and 'wonderland' - Skip Gram : ", model2.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " + "and 'machines' - Skip Gram : ", model2.similarity('alice', 'machines'))