一、 三元表达式
一 、三元表达式
仅应用于:
1、条件成立返回,一个值
2、条件不成立返回 ,一个值
def max2(x,y): #普通函数定义 if x > y: return x else: return y res=max2(10,11) print(res) # res=x if x > y else y #三元表达式 # print(res) #def max2(x,y): #return x if x > y else y #代码简洁,方便 #print(max2(10,11))
二、 递归
一 、递归调用的定义
递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
#直接调用 def foo(): print('from foo') foo() #foo() #间接调用 def bar(): print('from bar') foo() def foo(): print('from foo') bar() #foo()
二、 递归分为两个阶段:递推,回溯
1、回溯
(注意:一定要在满足某种条件结束回溯,否则就会无限递归)
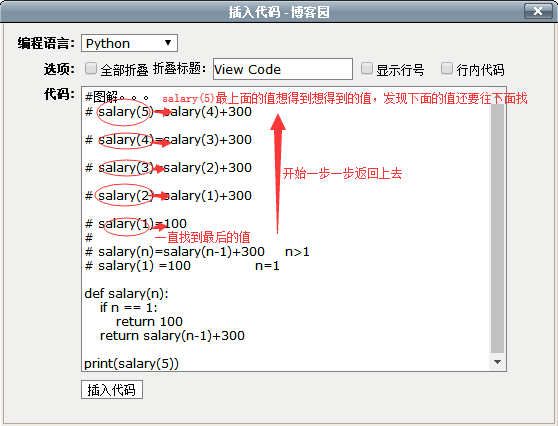
#图解。。。 # salary(5)=salary(4)+300 # salary(4)=salary(3)+300 # salary(3)=salary(2)+300 # salary(2)=salary(1)+300 # salary(1)=100 # # salary(n)=salary(n-1)+300 n>1 # salary(1) =100 n=1 def salary(n): if n == 1: return 100 return salary(n-1)+300 print(salary(5))
三 、python中的递归效率低且没有尾递归优化
总结递归的使用:
1、 必须有一个明确的结束条件
2、 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3、 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,
栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
四 、可以修改递归最大深度
import sys sys.getrecursionlimit() #系统默认的可递归次数1000 sys.setrecursionlimit(2000) # 调整可递归为2000
三、 匿名函数
一 、什么是匿名函数?
#匿名就是没有名字 def func(x,y,z=1): return x+y+z #匿名 lambda x,y,z=1:x+y+z #与函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,除非让其有名字 func=lambda x,y,z=1:x+y+z func(1,2,3) #让其有名字就没有意义
二、匿名的特点:
1、匿名的目的就是没有名字,给匿名函数赋给一个名字是没有意义的
2、匿名函数的参数规则、作用域关系与有名函数是一样
3、匿名函数的函数体通常应该是一个表达式,该表达式必须要有一个返回值
三 、有名字的函数与匿名函数的对比
有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能
匿名函数:一次性使用,随时随时定义 应用:max,min,sorted,map,filter
四、匿名函数和内置模块的一些应用
#匿名函数格式 lambda x,y:x+y #这个值和后面条件可以不断地变化 info=[ {'name':'egon','age':'18','salary':'3000'}, {'name':'wxx','age':'28','salary':'1000'}, {'name':'lxx','age':'38','salary':'2000'} ] max(info,key=lambda dic:int(dic['salary']) ) #跟内置函数max的结合使用,可以轻松的获取我们想要的值 min(info,key=lambda dic:int(dic['salary'])) #还有min取最小 l=sorted(info,key=lambda dic:int(dic['salary'])) #以什么为依据重新排序 map(lambda x:x**2,[1,2,3,4]) #映射,把得到的新值映射到原来的位置 filter(lambda x:x > 2,[1,2,3,4]) #把符合条件的值取出来