数据预处理:
一般用0均值化数据,若所有输入都是正的,则得到权重上的梯度也都是正的,会得到次最优的优化梯度
通过标准差来归一化
初始化权重:
如果以0(或相同的值)为所有权重的初始值,会导致所有的神经元将做同样的事,每个神经元将在输入数据上有相同的操作输出相同的值,得到相同的梯度,参数更新也相同,得到完全相同的神经元,学习到的知识也完全相同
方案一:

用很小的随机初始值作为权重初始化值,从概率分布中抽样。这种方法在小型网络中适用,但在深层的网络表现不好。很小的初始化权重会在一次次乘以权重W时,输入大量缩水逐渐趋于0,最后得到一堆0。
在反向传播时,会导致很小的梯度,基本上梯度不更新。
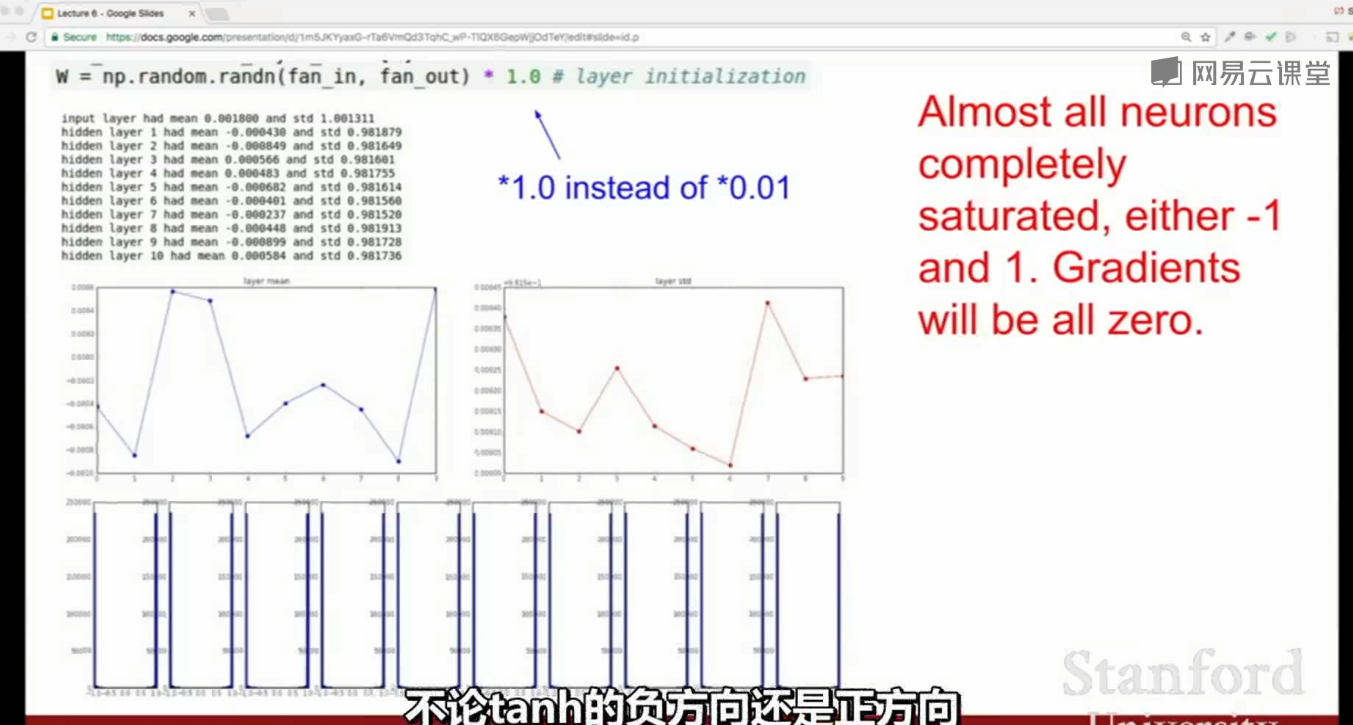
方案二:
用很大的权重(1为标准差系数)作初始化值,在tanh激活函数下,会使得网络很快达到饱和,梯度趋于0,参数不更新
方案三:Xavier初始化

W从标准的高斯分布中取样,然后根据输入的数量进行缩放,指定我们要求输入的方差等于输出的方差。如果你有少量的输入将会除以较小的数从而得到较大的(需要较大的)权重;如果有大量的输入将会除以较大的数得到较小的(需要较小的)权重。
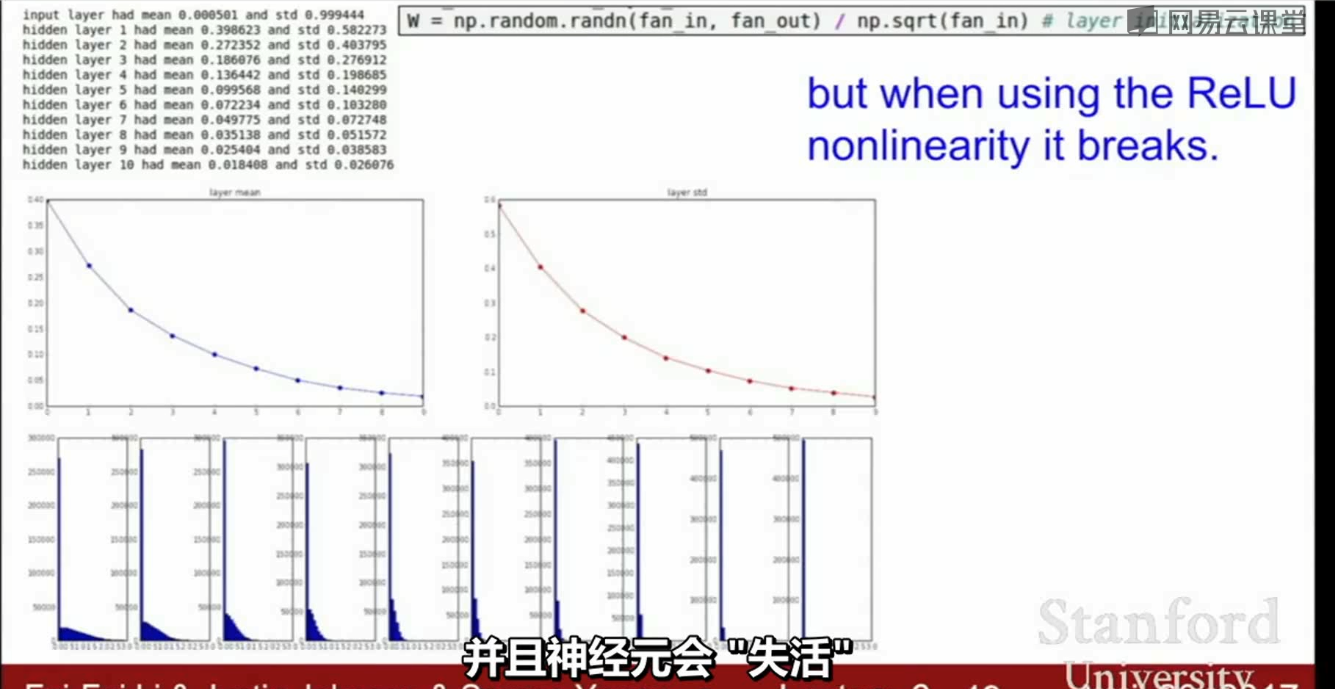
在使用ReLU类似的激活函数时,(一半的神经元被设置为0),实际上是把得到的方差减半,得到一个很小的值,此时又会导致(单位高斯)分布开始收缩,越来越多的峰值会趋近0,神经元会失活。
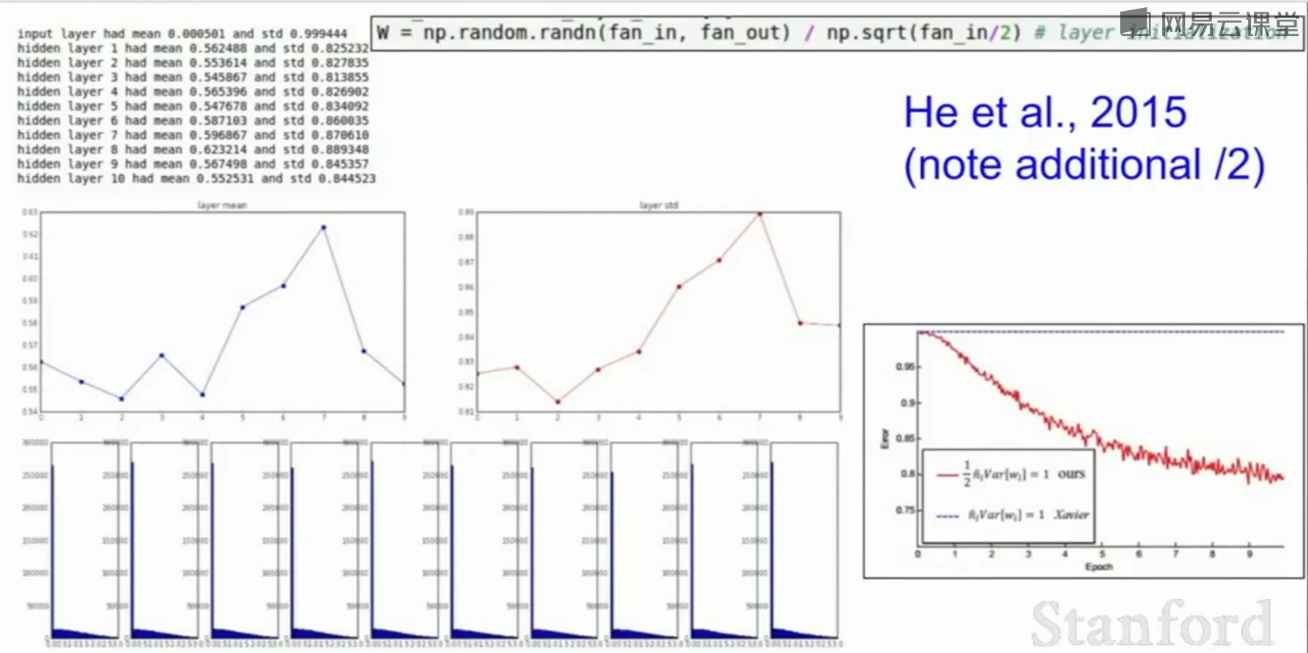
一半神经元被设置为0,只需将输入(分母fan_in)除以2即可解决上述问题:
学习率过大时会导致梯度爆炸
1