何为GBK,何为GB2312,与区位码有何渊源?
区位码是早些年(1980)中国制定的一个编码标准,如果有玩过小霸王学习机的话,应该会记得有个叫做“区位”的输入法(没记错的话是按F4选择)。就是打四个数字然后就出来汉字了,什么原理呢。请看下面的区位码表,每一个字符都有对应一个编号。其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、制表符、日文等等。
而GB2312编码就是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是:0xA0+区号,0xA0+位号。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312编码就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE
继续字符编码的学习。今天介绍一下GBK(汉字内码扩展规范),GB 2312 GB18030。引用网友的话可以概括一下:
GBK和UTF8的区别:GBK就是在保存你的帖子的时候,一个汉字占用两个字节。。外国人看会出现乱码,此为我中华为自己汉字编码而形成之解决方案。
UTF8就是在保存你的帖子的时候,一个汉字占用3个字节。。但是外国人看的话不会乱码,此为西人为了解决多字节字符而形成之解决方案。
GBK——专门为解决汉字的编码而生成的解决方案。
那么,一个汉字究竟被存储为什么,就需要:先查unicode码表,然后根据在码表的位置进行计算。例如:“电”字,在码表中是3575,计算成utf8就是E794B5,而在GB2312的码表中为B5E7。
GBK的中文编码是双字节来表示的,英文编码是用ASC||码表示的,既用单字节表示。但GBK编码表中也有英文字符的双字节表示形式,所以英文字母可以有2种GBK表示方式。为区分中文,将其最高位都定成1。英文单字节最高位都为0。当用GBK解码时,若高字节最高位为0,则用ASC||码表解码;若高字节最高位为1,则用GBK编码表解码。
编码方式:
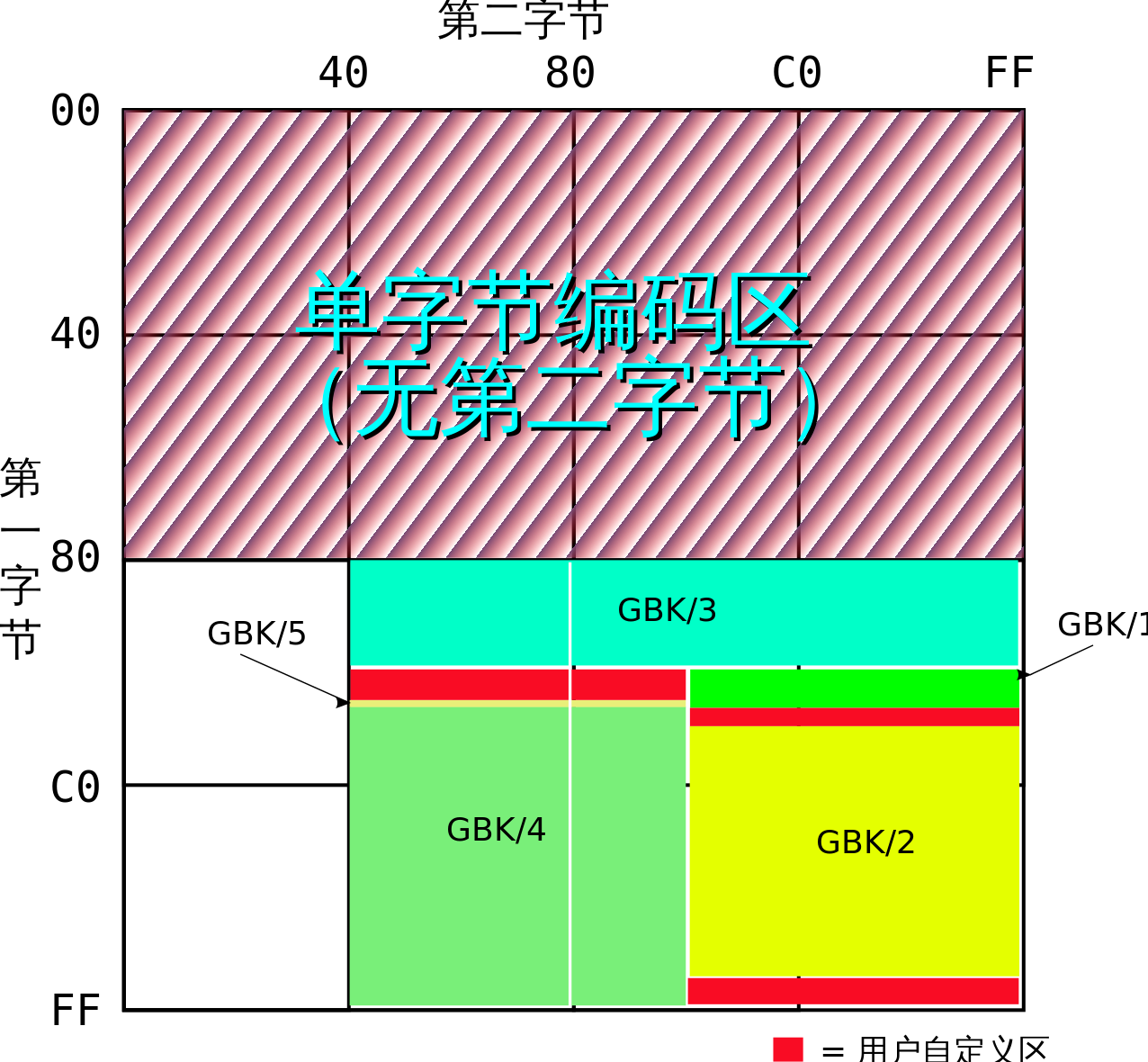
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。具体来说,定义的是下列字节:
| 范围 | 第1字节 | 第2字节 | 编码数 | 字数 |
|---|---|---|---|---|
| 水准GBK/1 | A1–A9 |
A1–FE |
846 | 717 |
| 水准GBK/2 | B0–F7 |
A1–FE |
6,768 | 6,763 |
| 水准GBK/3 | 81–A0 |
40–FE (7F除外) |
6,080 | 6,080 |
| 水准GBK/4 | AA–FE |
40–A0 (7F除外) |
8,160 | 8,160 |
| 水准GBK/5 | A8–A9 |
40–A0 (7F除外) |
192 | 166 |
| 用户定义 | AA–AF |
A1–FE |
564 | |
| 用户定义 | F8–FE |
A1–FE |
658 | |
| 用户定义 | A1–A7 |
40–A0 (7F除外) |
672 | |
| 合计: | 23,940 | 21,886 |
双字节符号可以表达的64K空间如下图所示。绿色和黄色区域是GBK的编码,红色是用户定义区域。没有颜色区域是不正确的代码组合:
要点总结
GBK编码是GB2312编码的超集,向下完全兼容GB2312。
GB18030编码向下兼容GBK和GB2312,
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换。
GBK,GB2312以及Unicode都既是字符集,也是编码方式,而UTF-8只是编码方式,并不是字符集
参考技术博客【点击】
GBK 码表 【点击转载处】
转自:https://www.cnblogs.com/batsing/p/charset.html
https://blog.csdn.net/hherima/article/details/50801360