BP算法的简单实现
"""
BPnet 简易实现
约定输入数据维度为(N, input_size)
输出数据维度为(N, output_size)
"""
import pickle
import os, sys
import numpy as np
import matplotlib.pyplot as plt
首先创建一个父类Fun, 主要定义了
forward: 前向方法,需要子类重定义;
Momentum: 一个梯度下降方法;
step: 更新系数的方法;
zero_grad: 将记录的梯度清空;
load: 加载系数;
class Fun:
def __init__(self):
self.parameters = 0.
self.grad = 0.
self.cum_direction = 0.
def forward(self, *input):
raise NotImplementedError
def Momentum(self, grad, lr=0.01, momemtum=0.9):
self.cum_direction = lr * (grad +
momemtum* self.cum_direction)
self.parameters -= self.cum_direction
def step(self, lr=0.01, momemtum=0.9):
self.Momentum(self.grad, lr, momemtum)
return 1
def zero_grad(self):
self.grad = 0.
return 1
def load(self, parameters):
self.parameters = parameters
return 1
def __call__(self, *input):
return self.forward(*input)
Linear 全连接层
全连接层需要注意的是
[y^r = sigma^r (W^Ty^{r-1}+b^r),
]
其中(y^r)表示第(r)层的输出,用(W)代替(W^r)表示系数,而(b^r)表示截距, (sigma^r)是激活函数,注意他是entry-wise的.
另外需要一提的是,因为numpy的特性,我们令(W)的列为每一个神经元所衍生的权重.
令(y_*)表示在(y)末尾添加1,而(W_*)表示在在最后添加一行(b^r).
BP算法,需要我们记录俩个东西,首先:
[egin{array}{ll}
mathrm{d} y^r = & diag({sigma^r}') W^T mathrm{d} y^{r-1} \
& + diag({sigma^r}') mathrm{d} W_*^T y_*^{r-1}.
end{array}
]
如果(mathrm{d} L = delta^T mathrm{d} y^r), 那么
[egin{array}{ll}
mathrm{d} L & = delta^T diag({sigma^r}') W^T mathrm{d} y^{r-1} \
& + mathrm{tr}(y_*^{r-1} delta^T diag({sigma^r}') mathrm{d} W_*^T).
end{array}
]
所以在Linear层,我们需要利用(y_*^{r-1})和(delta^T diag({sigma^r}')).
class Linear(Fun):
def __init__(self, input_size, output_size):
super(Linear, self).__init__()
assert isinstance(input_size, int) and input_size > 0,
"Invalid input_size"
assert isinstance(output_size, int) and output_size > 0, "Invalid output_size"
self.shape = (input_size+1, output_size)
self.parameters = np.random.rand(input_size+1, output_size) * 2 - 1 # (input_size+1, output_size+1)
self.parameters *= 0.01
def forward(self, x):
"""
:param x: (N, input_size)
previeous: (N, input_size+1)
:return:
"""
self.previous = np.insert(x, x.shape[1], values=1., axis=1)
return self.previous @ self.parameters
def backward(self, back_grad):
"""
:param back_grad: (N, output_size)
:return:
"""
self.grad += self.previous.T @ back_grad #w_grad (input_size+1, output_size)
pre_grad = back_grad @ self.parameters.T # (N, input_size+1)
return pre_grad[:, :-1]
ReLu
ReLu激活函数:
[ReLu(x) =
left {
egin{array}{ll}
x, & x > 0, \
0, & x <= 0.
end{array}
ight.
]
显然其导数为:
[ReLu'(x) =
left {
egin{array}{ll}
1, & x > 0, \
0, & xle 0.
end{array}
ight.
]
class ReLu(Fun):
def __init__(self):
super(ReLu, self).__init__()
self.grad = 0.
def forward(self, x):
"""
:param x: (N, output_size)
:return:
"""
self.sign_matrix = np.ones_like(x) #记录输入的是否为正
for i in range(x.shape[0]):
for j in range(x.shape[1]):
if x[i, j] <= 0:
self.sign_matrix[i, j] = 0.
return x * self.sign_matrix
def backward(self, back_ward):
"""
:param back_ward: (N, output_size)
:return: (N, output_size)
"""
return back_ward * self.sign_matrix
class Sequence(Fun):
"""
Sequence: 用于统一处理Linear层和激活函数
"""
def __init__(self, *fns):
super(Sequence, self).__init__()
self.fns = fns
def forward(self, x):
for fn in self.fns:
x = fn(x)
return x
def backward(self, back_grad):
for fn in self.fns[::-1]:
back_grad = fn.backward(back_grad)
return 1
def step(self, lr=0.01, momemtum=0.9):
for fn in self.fns[::-1]:
fn.step(lr, momemtum)
return 1
def zero_grad(self):
for fn in self.fns:
fn.zero_grad()
return 1
def get_pra(self):
d = dict()
for i, fn in enumerate(self.fns):
s = "params" + str(i)
d.update({s:fn.parameters})
return d
def load(self, parameters):
for i, fn in enumerate(self.fns):
s = "params" + str(i)
fn.load(parameters[s])
return 1
MSELoss
MSE损失函数:
[MSE(hat{y}, y) = |hat{y}-y|^2 / 2. \
]
所以关于(hat{y})的梯度就是:
[
abla_{hat{y}} L = (hat{y} - y).
]
MSELoss 不适合用于分类
class MSELoss(Fun):
def __init__(self, output_size):
super(MSELoss, self).__init__()
self.prime_grad = None #最初的梯度
self.output_size = output_size
def forward(self, x, y):
y = y.reshape(-1, self.output_size)
self.prime_grad = (x - y) / x.size
return np.linalg.norm(x-y) / (2 * x.size)
def backward(self):
if self.prime_grad is None:
raise ValueError("forward first...")
else:
back_grad = self.prime_grad
self.prime_grad = None
return back_grad
交叉熵损失函数
[loss (hat{y}, class) = -log frac{exp(hat{y}[class])}{sum_j exp(hat{y}[j])} = -hat{y}[class]+log (sum_j exp (hat{y}[j])).
]
其导数分俩种,一种(k=class):
[-1 + frac{exp (hat{y}[class])}{sum_j exp (hat{y}[j])},
]
另一种是一般的(k ot = class)
[frac{exp (hat{y}[k])}{sum_j exp (hat{y}[j])}.
]
class CrossEntropyLoss(Fun):
def __init__(self, output_size):
super(CrossEntropyLoss, self).__init__()
self.prime_grad = None
self.output_size = output_size
def forward(self, x, classes):
classes = classes.reshape(1, -1)[0]
pri_grad = np.exp(x)
row_sum = np.sum(pri_grad, axis=1) + 1e-5 #+1e-5是为了放置后面除以0发生
pri_grad /= row_sum
loss = np.sum(np.log(row_sum)) -
np.sum(x[np.arange(len(x)), classes])
pri_grad[np.arange(len(x)), classes] -= 1.
self.prime_grad = pri_grad
return loss
def backward(self):
if self.prime_grad is None:
raise ValueError("forward first...")
else:
back_grad = self.prime_grad
self.prime_grad = None
return back_grad
Net 模块,用以具体定义网络
save_pra: 用以保存网络参数
load: 用以加载网络参数
class Net:
def __init__(self, input_size, output_size):
self.shape = (input_size, output_size)
self.dense = Sequence(
Linear(input_size, 256),
ReLu(),
Linear(256, output_size)
#ReLu()
)
def forward(self, input):
#前向
x = input.reshape(-1, self.shape[0])
x = self.dense(x)
return x
def backward(self, back_grad):
#后面
self.dense.backward(back_grad)
return 1
def step(self, lr=0.01, momemtum=0.9):
#更新参数
self.dense.step(lr, momemtum)
return 1
def zero_grad(self):
#清空参数
self.dense.zero_grad()
return 1
def __call__(self, input):
return self.forward(input)
def get_pra(self):
#获得整个网络的参数
return self.dense.get_pra()
def save_pra(self, filename):
#保存参数
fh = None
try:
fh = open(filename, "wb")
pickle.dump(self.get_pra(), fh, pickle.HIGHEST_PROTOCOL)
return True
except (EnvironmentError, pickle.PicklingError) as err:
print("{0}: export error:{1}".format(
os.path.basename(sys.argv[0]),
err
))
return False
finally:
if fh is not None:
fh.close()
def load(self,filename):
#加载参数
fh = None
try:
fh = open(filename, "rb")
self.dense.load(pickle.load(fh))
return True
except (EnvironmentError, pickle.UnpicklingError) as err:
print("{0}: import error: {1}".format(
os.path.basename(sys.argv[0]),
err
))
finally:
if fh is not None:
fh.close()
利用pytorch加载数据, dataloader就实现了
import torch
import torchvision
import torchvision.transforms as transforms
root = "C:/Users/pkavs/1jupiterdata/data"
trainset = torchvision.datasets.MNIST(root=root, train=True,
download=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
train_loader = torch.utils.data.DataLoader(trainset, batch_size=10,
shuffle=False, num_workers=0)
net = Net(784, 10)
criterion = CrossEntropyLoss(10)
lr = 0.001
running_loss_sotre = []
for epoch in range(100):
running_loss = 0.0
for i, data in enumerate(train_loader):
if i > 30:
break
img, label = data #获得图片和对应的标签
img = img.numpy().reshape(-1, 784) #将img展成 N x 784的格式
label = label.numpy().reshape(-1, 1)
out = net(img) #获得输出
pre = np.argmax(out, axis=1) #预测数字
loss = criterion(out, label) #计算损失
back_grad = criterion.backward() #计算最初的反向梯度
net.zero_grad() #清空梯度
net.backward(back_grad) #backward
net.step(lr) #更新参数
running_loss += loss #计算总损失(没有取平均)
running_loss_sotre.append(running_loss)
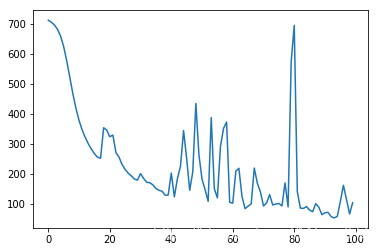
print(running_loss)
712.1688029691725
705.6159884056726
696.3605306115187
681.9076985339979
659.0826257639627
624.2703850543031
576.5937881650244
521.3977792378652
466.47017818483283
417.5564483014553
377.58100395697363
346.1484168296081
321.0583297303844
299.88669109678415
281.73335412780835
266.4387592276925
254.90370768549863
251.07210302796904
353.18543794564295
345.2766226396521
322.9940783753454
328.6428077023008
270.3180403869843
254.9775608799049
230.08133829802637
213.69077670024637
201.2119790409399
192.50392038991563
181.69069506741027
178.2996933457074
199.9777923246425
183.87773045669059
170.99605668520786
169.35489179121672
162.42947830951198
150.1597596908225
143.98469229350468
141.00677525306008
127.59468686946381
128.40368339434258
201.57296802164916
122.20421766353607
182.8687570603292
224.37539134301915
343.40783375914333
250.66337879988703
144.2342106544594
205.95460344415
434.22102036193616
262.12760610791236
181.4400162958133
146.26211257970715
107.27112642333483
386.98537618442816
149.87855150968906
118.72956374544908
290.49626828881196
350.8852347420042
371.930405421759
104.02686372628847
101.15345754083307
208.05191021294857
217.52326838076044
123.5967585636549
82.73846477428404
91.29321266867215
98.7565490505614
218.3168084371386
167.60294451519016
138.7077575534406
91.50995861413155
102.04165505706565
129.74743597062437
94.99038470007001
98.36682096410206
100.15976484641901
91.84933076142981
168.72629650699594
88.56789923054023
573.3308046615387
695.0027992214693
139.41352718479337
84.40384142335002
83.6842770585352
89.64514463543952
77.73045621193755
72.65538892463755
99.59331140163596
87.4561441314255
62.48886272879916
69.1248402550191
70.21564469977797
56.14423053270053
51.8464048296232
56.87218546726085
107.25968791508906
160.84428492958492
113.05206798096374
65.12042358285711
102.60376565303726
running_loss_store = np.array(running_loss_sotre)
plt.plot(np.arange(len(running_loss_store)), running_loss_store)
plt.show()
testset = torchvision.datasets.MNIST(root=root, train=False,
download=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
))
test_loader = torch.utils.data.DataLoader(testset, batch_size=1,
shuffle=False, num_workers=0)
count = 0
correct = 0
for i, data in enumerate(test_loader):
img, label = data #获得图片和对应的标签
img = img.numpy().reshape(-1, 784) #将img展成 N x 784的格式
label = label.numpy()
out = net(img) #获得输出
pre = np.argmax(out, axis=1) #预测数字
correct += pre == label
correct_rate = (correct / 10000)[0]
correct_rate
0.7558