1为什么我们需要KNN
现在为止,我们都知道机器学习模型可以做出预测通过学习以往可以获得的数据.
因为KNN基于特征相似性,所以我们可以使用KNN分类器做分类.

2KNN是什么?
KNN K-近邻,是一种简单的机器学习算法,目前被广泛使用分类.KNN做分类基于基于与 将要分类的点 的邻居的类别.

KNN 存储所有可以获得的例子,并基于相似性的度量做出分类 (也就是说和仓库里的特征进行对比,谁相近 就判为哪一类.)
k在KNN中是一个参数,指的是在多数表决过程中要包括的最近的邻居的数量(这里的意思就是找的所要判别的最近邻居的数量,比如K=5,就么就找5个最近的邻居,这5个中那一个标签占多数,则可以判别出书属于哪一个标签)
(k in KNN is a parameter that refer to the number of nearest neighbors to include in the majority voting process)
3我们怎样选择K 参数?
KNN算法基于特征相似性:选择一个正确的K值是一个参数调优的过程,这对于获得一个更好的精度是非常重要的.
(KNN Algorithm is based on feature similarity:choosing the right value of k is a process called parameter tuning, and is important for better accuracy)
对于不同的K值,最终分类的结果可能是不同的,见下图的情况.当选择K=3时,新样本被判别为方框,但是当选择K=7时新样本被判别为三角形
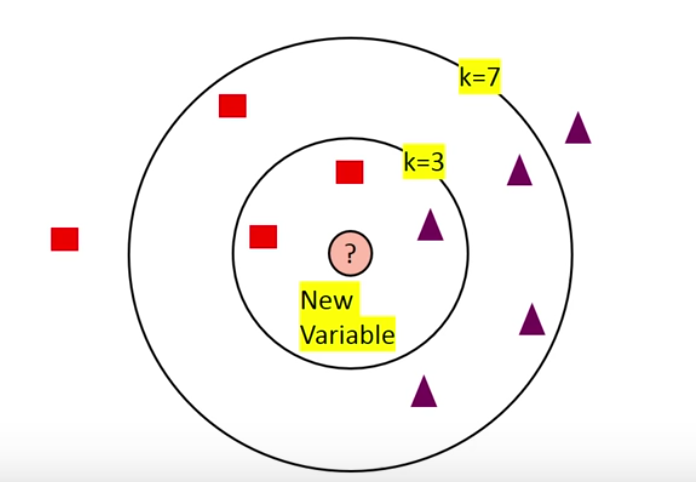
所以我们应该怎样选择一个好的K值呢?一般有下面两个注意点
(1) 对所有数据点数目开平方得到的数作为K值。这里需要注意对谁开平方,我目前理解的是对训练的数据集数量开平方。
(2) 选择K的奇数值是为了避免两类数据之间的混淆。例如在本教程视频中附带的一个例子,对训练数据集开平方得12,409 ,但是作者为了取奇数,用12-1=11把11作为K值。
见下图:

4我们什么时候使用KNN
we can use knn when {date is labled;data is noise free ;data is small}
对于数据集小的解释是:because KNN is a lazy learner ,so doesn't learn a discriminative function from the traing set (因为KNN是一个懒惰的学习者,所以不会从训练集中学习判别函数.对于小的数据集,KNN 是非常好的
)

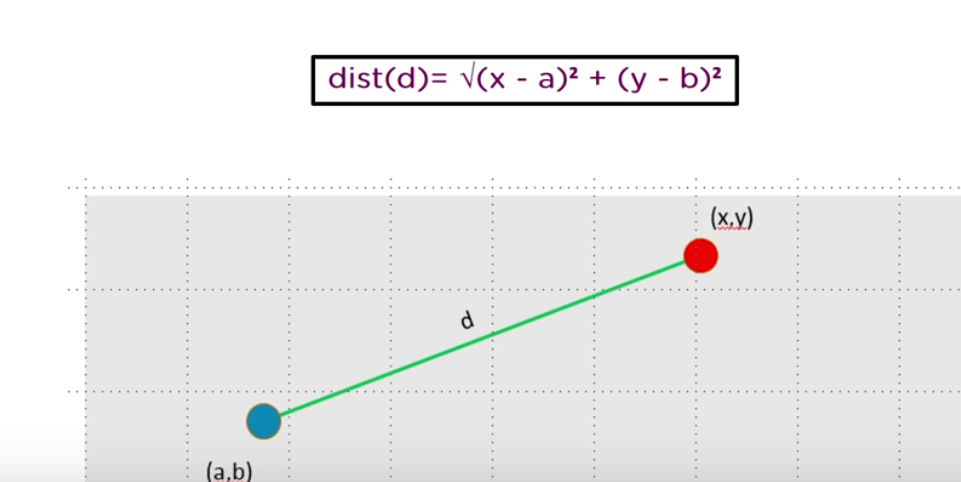
让我们通过计算来更清晰的理解欧式距离

5KNN是怎样工作的 ?
(1) 考虑一个数据集有两个变量:高度(cm)和重量(kg)并且数据集的每一个数据点被分类为正常和重量低的,基于给出的数据集,我们需要来分类一个数据点。怎样找到这个数据段最近的邻居呢? 考虑用欧式距离,那么什么是欧式距离呢?公式如下:
(2)然后,我们计算需要分类的 未知数据点的所有欧式距离显示在下表中。

(3)现在让我们以K=3 来计算出三个最近邻,因为这三个最近邻指示的标签都为Normal,所以待判别的数据点对应的类也是Normal

6 回顾KNN算法(recap the KNN)

KNN算法的回顾一共有4个点,分别为:
(1)指定一个正整数k和一个新样本。
(2)我们在数据库中选择最接近新样本的K个条目
(3)我们发现这些条目最常见的分类
(4)这是我们给新样品的分类
——————————分割线——————————
该视频的后面还讲述了一个使用KNN 算法进行预测糖尿病的实例,收录在我的博客中,如有兴趣,请到分类Python&Python_case查询。