六、Hive
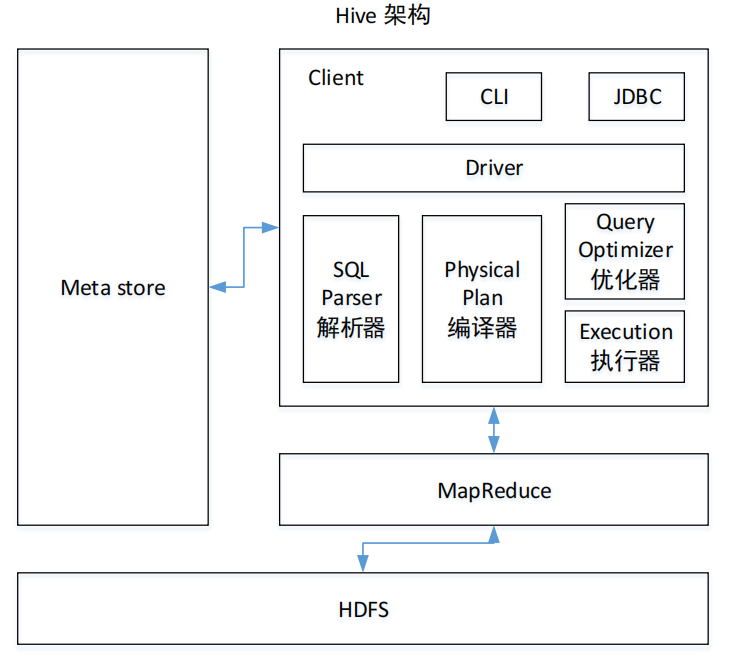
6.1 基本架构
6.2 与数据库的比较
| mysql | hive | |
| 速度 | 数据量小、快 | 数据量大、快 |
| 场景 | 小数据量的增删查改 | 大数据量的查询分析 |
6.3 内部表、外部表
删除内部表:删元数据、原始数据
删除外部表:删元数据
企业怎么用?
主要用外部表,临时表和测试表用内部表
6.4 4个By
order by:全局排序,最终只有一个reducer,结合limit一起使用
sort by:分区内排序
distribute by:分区,指定数据该进入哪个reducer
cluster by:当sort by 与 distribute by字段一致时,且升序,可以用cluster by代替
6.5 系统函数
时间:date_add、date_sub、datediff、next_day、last_day、xxxofxxx、from_unixtime、unix_timestamp、now、date_format
字符串:substring、split、concat、concat_ws、get_json_object、replace、regexp_replace
行列转换:
一行转多行:explode(数组、map)
多行转一行:collect_list、collect_set
一列转多列:if、case when
多列转一列:concat、concat_ws
空值处理:nvl、if
6.6 窗口函数
聚合类、排名、lead、lag、first_value、last_value over(partition by ...order by ... 行的范围)
行的范围:rows、range
例如:sum() over()
| rows | range | |
| 1 | 1 | 1 |
| 2 | 3 | 3 |
| 3 | 6 | 9 |
| 3 | 9 | 9 |
| 4 | 13 | 13 |
| 5 | 18 | 18 |
order by 默认行范围:range 上无边界到当前行
6.7 自定义函数
UDF:一进一出
UDTF:一进多出
UDAF:多进一出
项目里用到了什么?UDTF:用来解析Json数据里面的Array,实现一进多出
为什么不用get_json_object?它只能一进一出
怎么实现?定义一个类,继承GenericUDTF,重写3个方法
初始化方法:输入参数的效验,比如个数、类型,返回类型的约束
process方法:多次调用fowward
close()
完成之后打jar包,上传至HDFS,然后在客户端中输入:
create function 方法名 as 全类名 using jar 'hdfs路径'
为什么用自定义?
1、解析Json中的Array,一进多出
2、方便使用第三方依赖
6.8 优化
1)map join:大小表,默认打开
2)列式存储:orc、parquet
结构更紧凑,压缩比更高,适合查询更新
| id | name | age |
| 1 | zs | 18 |
| 2 | ls | 20 |
列式存储:1 2 zs ls 18 20
行式存储:1 zs 18 2 ls 20
3)分区、分桶
4)压缩:lzo、snappy
5)小文件:
JVM重用:10
使用CombineHiveInputFormat来进行切片:256m
merge:单独再启动一个job,将平均小于16M的文件,合并为一个最大为256M的文件
map-only:默认开启
map-reduce:默认关闭,设置为开启
6)行列过滤:
避免select *
能先过滤就先过滤
谓词下推:在map阶段,提前过滤(若需要详细了解,请参考博客:https://www.cnblogs.com/LzMingYueShanPao/p/15167014.html)
两张表关联,过滤条件写在on和写在where有什么区别?
select xxx from a join b on a.id > 10
select xxx from a join b where a.id > 10
首先先判断是什么Join
如果是内连接,无任何区别
如果是满外连接,on性能比where差,因为默认开启cbo优化,where可以进行谓词下推
如果是left join或 right join,再判断条件来自哪张表
如果判断条件来自保留表,则on性能比where差,因为on不能进行谓词下推
如果判断条件来自非保留表,则无任何区别,因为默认开启cbo优化,where可以进行谓词下推
7)Map数量
切片大小 = max(minSize,min(maxSize,块大小))
8)reduce数量
估算机制:输入的数据量 / 单个Reducer处理的数据量
参数设置:mapred.reduce.tasks,默认 -1,表示不开启
特殊语法:order by 1个
优先看是否指定了参数,如果没有,就走估算机制
9)多引擎
mr:年月指标
spark:日常的天指标
tez:临时用
若不同引擎结果不一,以MR为主
如何实现不同Job不同引擎来跑?
1、部署spark环境
2、set hive.execution.engine = spark;
sql
set hive.execution.engine = mr;
sql
6.9 数据倾斜
1)现象:yarn页面,个别reduce执行时间明细特别长,卡在99%
2)原因:
数据本身就不均匀
Null值
类型不一致
3)解决方案
辅助措施:提前Combiner,在不影响最终逻辑的情况下
数据本身就不均匀:二次聚合
参数:hive.groupby.skewindata,解决group by数据倾斜,自动实现二次聚合
hive.optimize.skewjoin,解决join的数据倾斜,自动实现二次聚合
null值:
null值无意义,先过滤
null值有意义,二次聚合,使用到nvl
类型不一致:先转换类型,再join a join b on cast(a.id,string) = b.id
6.10 分隔符问题:数据本身携带了hive的分隔符
问题:hive表字段错误
解决:
1、参数 --> 默认分隔符为 �01
2、mysql表导一张到临时表,再同步到hdfs
3、让后端人员改
七、Sqoop
7.1 遇到哪些问题
1)空值问题
| mysql | Hive |
| null | N |
导入时:null-string、null-non-string
导出时:input-null-string、input-null-non-string
2)导出是,遇到一致性问题
底层跑的是4个map任务,解决方法就是手动创建一张临时表,将数据导入临时表中,数据全部进入临时表后,再导入到目标表,有两个参数可以设置:
–staging-table mysql表名_tmp (将数据先导入临时表)
–clear-staging-table (清空临时表)
3)数据倾斜问题
我们一天1个G左右,没遇到
但是以前有个朋友遇到过:split-by 指定自增主键,指定增加map数
7.2 每天业务数据有多少?
60万日活,平均每天6万订单,每个订单10条数据,每条数据平均1k
6万 * 10 * 1k = 600000k ≈ 600M左右
7.3 每天几点跑,跑多久?
00:10开始跑,大概跑10多分钟
7.4 参数
sqoop --import --connect url --user --password --target-dir --delete-target-dir --query 'select xxx from where xxx $condition' --空值处理的两个参数 --split-by --mapper
7.5 导出时,parquet问题
1)先将数据导入到格式为Text格式的临时表中,再导出
2)一开始就不要用列式存储
3)hcatalog导出,sqoop参数,要求版本1.4.5
八、Azkaban
8.1 每天几点跑,跑多久?
第一个脚本:sqoop同步脚本,00:10开始跑
平均3个多小时,不管怎么跑,早上八点一定会出结果
8.2 日常跑多少指标?活动时多少?
日常跑100来个指标,有活动时200来个
8.3 任务挂了怎么办?
告警:邮件、发短信、发微信、发钉钉、打电话
实现:调用第三方接口,oneAlter
尝试重启:自动重试、手动重试
解决问题:看日志(资源不够、业务表发生改变)
摇人
九、项目架构
9.1 从0到1
1)集群规模:目前有没有服务器给你用,几台?一共有9台,后来增加到12台
2)数据量:日志数据每天60G左右,业务数据每天600多M
3)周期:采用敏捷开发模型,基本上一个月为一个开发周期,比如1.2.3版本号,一个星期更换数据为3的版本号,表示小范围的更新,2这个数据一般一个月更新一次,表示中等规模的更新,1的话一般半年或一年更新一次,表示大的一个版本更迭
4)资金:服务器买了3台,每台服务4万块,3台一共12万多
5)人员:5个人,包含组长
6)指标规划:第一期指标20多个,比如求新老用户、留存率、页面跳转率、活跃人数、每日下单数、每日支付数、每日下单金额等
7)数据来源:oracle、db2、sqlserver、qp、mysql
9.2 数仓概念
1)数据来源:前端埋点日志、javaee后台业务服务
2)产出:报表、用户画像、推荐系统、风控系统
9.3 版本选型
开源版:apache,大厂
商业版:cdh、hdp -->cdp,1个节点1万美金/年
cdh:6.3.2
hdp:3.1.4
建议选哪个?建议选apache、虽然成本比较高昂,但安全性强
9.4 集群规模:几台服务器,60万日活
1)磁盘:半年不扩容
数仓分层:
日志:
ods:6G(压缩后)
dwd:6G(压缩后)
dws + dwt:30G,压缩后3G
ads:忽略
6 + 6 + 3 = 15G,给个20G
20G * 3 副本 * 180天 / 0.7 ≈ 15T,给20T
业务:
2G * 3副本 * 180天 / 0.7 = 2T
kafka:之前给1T
20T + 2T + 1T = 23T
23T / 8T = 3台
2)内存:
7台 * 128G = 896G
1台服务器的NodeManager给100G -->100G * 7 = 700G
离线:128M数据 --> 1G内存(占比约1:8),同时跑70G的数据,大约需要600G内存左右
实时:10 + 几个Job,1个Job10多G,大约需要200G内存左右
通过计算,7台不太够,建议:9~15台
3)CPU
单台20核40线程
40 * 7 = 280(200给集群 ,80给其他)
实时:1个Job,6个并行度 --> 6线程, 6 * 10多个 约等于 90线程
离线:100+ 可用
通过计算,7台不太够,建议9~15台
十、数仓分层
10.1 建模第一步做什么?
理清业务逻辑,求出业务表
10.2 ods
1)使用分区表,避免全表扫描
2)压缩,减少磁盘空间
3)保持数据原貌,起到备份的作用
10.3 dwd + dim
1)清洗工具
hql、spark、flink、python、kettle
2)清洗原则
解析数据
去重
核心字段不能为空
超期数据(爬虫)
脱敏:md5
3)清洗比例:万分之一
若清洗比例较高,找前端和Java开发人员沟通
4)分区
5)压缩
6)列式存储
7)维度退化
基于维度建模的星型模型理论
降维:将某个维度的所有表合并成一张表,以后关联某个维度时,只需要join一次
sku表、spu表、三级、二级、一级分类、品牌、商品平台属性表、商品销售属性表 -->商品维度表
省份表、地区表 --> 地区维度表
活动信息表、活动规则表 --> 活动维度表
8)维度建模
(1)选择业务过程,选择需要的业务表
小公司,30来张,全都要
大公司,上千张,选择需要的业务模块:下单模块、支付模块、物流模块...
(2)声明粒度
什么是粒度?一行数据代表什么行为
比如订单表的一行数据,代表了一次下单行为
声明最小粒度:只要不做聚合操作,就已经是能达到的最小粒度
(3)确定维度:描述某个业务事实的角度
何时、何地、何人对何物做了何事(时间、地区、用户、商品、下单或支付)
(4)确定事实
关注事实的度量值:个数、件数、金额、次数等可统计的量词
使用业务总线矩阵来计算
10.4 dws:一天的汇总
1)有哪些宽表:主要参考维度表,有多少维度,就有多少宽表
地区、用户(会员)、访客(设备)、商品、活动、优惠券
2)宽表有哪些字段:站在维度的角度,关注事实的度量值
10.5 dwt:一段时间的累计
目的: 避免重复计算
1)有哪些宽表:主要参考维度表 ,有多少维度表,就有多少宽表
地区、用户(会员)、访客(设备)、商品、活动、优惠券
2)宽表有哪些字段:站在维度的角度,关注事实的 开始时间、结束时间、这段时间度量值的累积、最近一段时间度量值的累积
10.6 ads:
指标:
手写:实现思路
比较难的指标:
十一、数仓业务
11.1 埋点格式
页面日志、启动日志、曝光日志、事件日志、错误日志
1)启动日志
{ "common":{}, "start":{} "err":{}, "ts":xxxxxx }
2)其他
{ "common":{}, "actions":[{},{},...], "display":[{},{},.....], "page":{}, "err":{}, "ts":xxxx }
11.2 同步策略
业务数据MySQL --> Sqoop --> HDFS
全量数据:数据量小
sqoop的query "select * from 表名 where 1=1"
新增数据:数据量大,历史数据不会变化
sqoop的query "select * from 表名 where 创建时间=昨天"
新增及变化:数据量大,历史数据会变化(后续dim层,使用拉链表)
sqoop的query "select * from 表名 where 创建时间 = 昨天 or 操作时间 = 昨天"
特殊数据:全量导入
11.3 建模理论
关系建模:业务库MySQL,基于三范式理论的第三范式
减少数据冗余,取哪个维度就要跟哪个维度join一次
维度建模:星型模型、雪花模型、星座模型
降维,取一个维度,只需要join一次,需要数据冗余,不灵活(字段变更)
星型模型:一张事实表周围围绕着多个一级维度表
雪花模型:一张事实表周围围绕着多个多级维度表
星座模型:多个事实表周围围绕着多个一级维度表
11.4 业务库的表发送变化怎么办?
1)新字段,历史数据需不需要补全
需要:一点点改,重新跑任务
不需要:从新增开始,有数据就行,改数仓脚本就行,加上字段
2)减字段
改数仓脚本,减去字段
11.5 数仓有几张表
ods:日志1张,业务27张
dwd:日志5张,9张事实表,6张维度表
dws:宽表6张
dwt:宽表6张
ads:约30张
我们公司100张左右
11.6 数仓哪张表最大?
50G / 5张日志表 = 平均10G
用户行为宽表:10G * 3 = 每天30多G
11.7 实时资源
Flink:JobManager,128M~2G
TaskManager,1)并行度:2的n次方 8
2)内存:4G
3)每个TaskManager的slot数:4
平均一个job至少要10G内存
11.8 平均每张表每天多大?
日志: 每天每张平均10G
业务: 每天每张平均 34m左右,大的表 5倍 =》 170M左右,
小的表 5M左右
11.9 数据治理
元数据管理:hive表的元数据
数据质量监控:数据量的监控、重复数据监控、空值监控
底层实现:SQL
底层:shell脚本
权限管理:ranger
11.10 数据中台
11.11 数据湖