第1章 电商实时数仓介绍
1.1 普通实时计算与实时数仓比较
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差,开发成本随着需求增加直线上升。

实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据和计算的复用性。
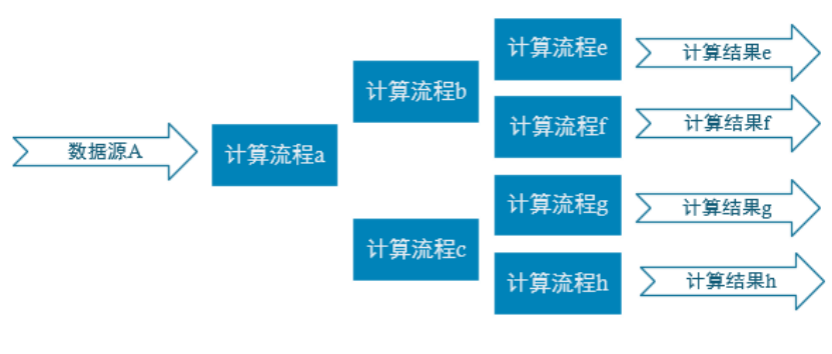
1.2 实时电商数仓项目分层
1)ODS层
原始数据: 日志数据和业务数据
2)DWD层
依据数据对象为单位进行分流,比如订单、页面访问等等
3)DIM层(Hbase+phoenix)
维度数据
4)DWM层
对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,仍然是明细数据。
5)DWS层
根据某个主题将多个事实数据轻度聚合,形成主题宽表。数据存储到clickhouse
6)ADS层
把Clickhouse中的数据根据可视化需要进行筛选聚合
第2章 实时需求概述
2.1 离线计算与实时计算的比较
1)离线需求
就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是Hadoop的MapReduce方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算
2)实时需求
输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
2.2 通常实时指标
2.2.1 日常统计报表或分析图中需要包含当日部分

对于日常企业、网站的运营管理如果仅仅依靠离线计算,数据的时效性往往无法满足。通过实时计算获得当日、分钟级、秒级甚至亚秒的数据更加便于企业对业务进行快速反应与调整。所以实时计算结果往往要与离线数据进行合并或者对比展示在BI或者统计平台中。
2.2.2 实时数据大屏监控
数据大屏,相对于BI工具或者数据分析平台是更加直观的数据可视化方式。尤其是一些大促活动,已经成为必备的一种营销手段。另外还有一些特殊行业,比如交通、电信的行业,那么大屏监控几乎是必备的监控手段。
2.2.3 数据预警或提示
经过大数据实时计算得到的一些风控预警、营销信息提示,能够快速让风控或营销部分得到信息,以便采取各种应对。比如,用户在电商、金融平台中正在进行一些非法或欺诈类操作,那么大数据实时计算可以快速的将情况筛选出来发送风控部门进行处理,甚至自动屏蔽。 或者检测到用户的行为对于某些商品具有较强的购买意愿,那么可以把这些“商机”推送给客服部门,让客服进行主动的跟进。
2.2.4 实时推荐系统
实时推荐就是根据用户的自身属性结合当前的访问行为,经过实时的推荐算法计算,从而将用户可能喜欢的商品、新闻、视频等推送给用户。这种系统一般是由一个用户画像批处理加一个用户行为分析的流处理组合而成。
第3章 计算架构
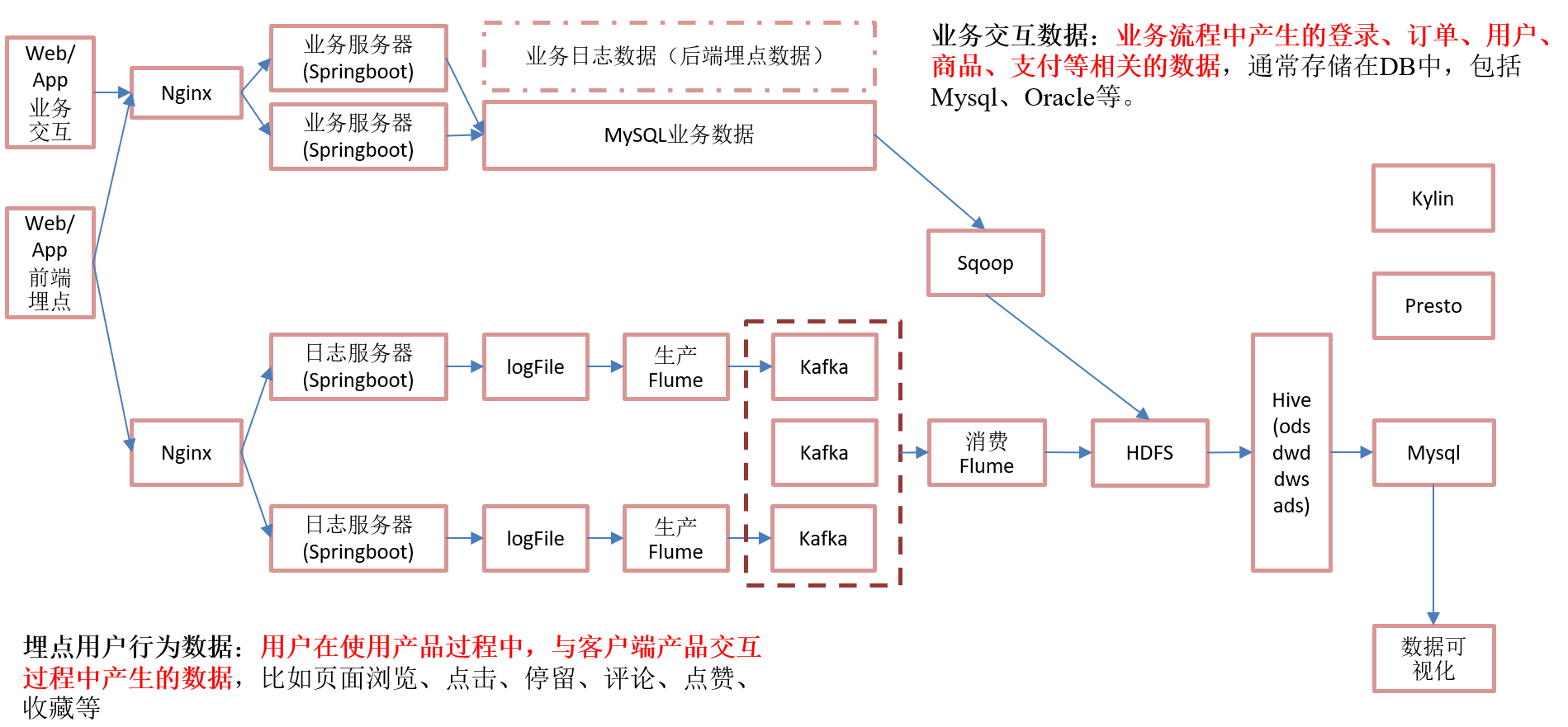
3.1 离线架构
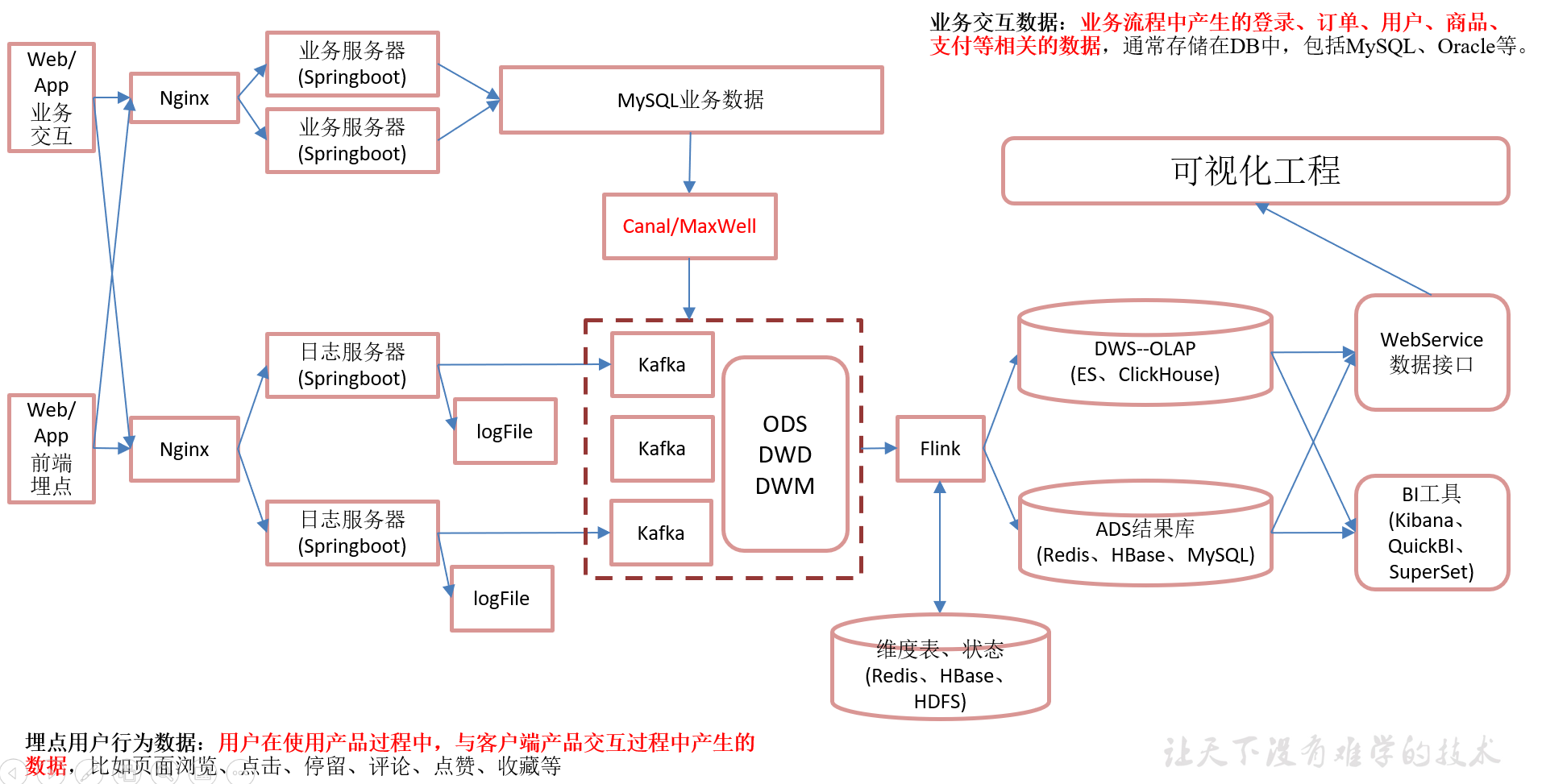
3.2 实时架构
第4章 日志数据采集
整个模拟数据的生产过程与离线数仓中模拟数据的生产过程基本一致, 个别地方需要修改,这里提供了一个模拟生成数据的jar包,可以将日志发送给某一个指定的端口,需要大数据程序员了解如何从指定端口接收数据并数据进行处理的流程。
4.1 模拟数据需要用到的文件列表
cd /opt/software/mock/mock_log

4.2 修改application.yml文件
根据自己实际情况修改配置文件application.yml
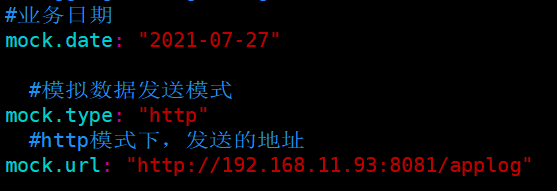
说明:
1)mock.data是模拟的日志数据的日期
2)mock.type 如果模拟实时数据, 则该值必须设置为http
3)mock.url是日志服务器的地址, 表示把模拟出来的数据发送到这个地址. 写这个地址的时候一定要明白你接收日志的服务器的地址是哪里!
4.3 生产模拟数据
java -jar gmall2020-mock-log-2020-12-18.jar
注意: 必须等到接收日志的服务器部署完成之后这里才可以正常工作
第5章 创建父工程
在整个实时数仓项目中, 会有比较多的模块需要管理, 我们统一创建一个父工程来管理不同的模块
1)新建父工程命名FlinkParent
2)新建SpringBoot子工程
第6章 搭建单机版数据采集服务器
6.1 了解springboot
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
使用 Spring boot 好处:
1)内嵌 Tomcat, 不再需要外部的 Tomcat
2)不再需要那些千篇一律,繁琐的 xml 文件。
3)更方便的和各个第三方工具( mysql,redis,elasticsearch,dubbo 等等整合),而只要维护一个配置文件即可。
6.1.1 springboot与SSM的关系
springboot 整合了springmvc, spring 等核心功能。也就是说本质上实现功能的还是原有的spring ,springmvc 的包,但是 springboot单独包装了一层,这样用户就不必直接对 springmvc, spring 等,在 xml 中配置
6.1.2 springboot如何配置
springboot实际上就是把以前需要用户手工配置的部分,全部作为默认项。除非用户需要额外更改不然不用配置。这就是所谓的:“约定大于配置”
如果需要特别配置的时候,去修改application.properties
6.2 在idea创建日志采集服务器
步骤1: 在project中创建springboot子模块
1)父工程的pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.yuange.flink</groupId> <artifactId>FlinkParent</artifactId> <packaging>pom</packaging> <version>1.0-SNAPSHOT</version> <modules> <module>flink-logger</module> </modules> </project>
2)flink-logger 子工程
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.5.3</version> <relativePath/> <!-- lookup parent from repository --> </parent> <artifactId>flink-logger</artifactId> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
步骤2: 创建controller,在controller中定义方法, 用来处理客户端的http请求,如果不做额外配置, controller需要与主程序GmallLoggerApplication同包, 或它所在包的子包下
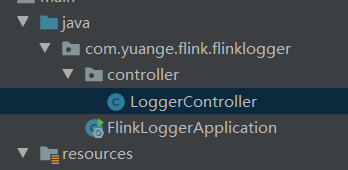
package com.yuange.flink.flinklogger.controller; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; /** * @作者:袁哥 * @时间:2021/7/27 19:54 */ @RestController public class LoggerController { @GetMapping("/applog") public String doLog(@RequestParam("param")String log){ System.out.println(log); return "success"; } }
步骤3: 修改日志服务器端口为8081,在配置文件 resources/application.properties 内添加如下代码:
server.port=8081
步骤4: 启动日志服务器, 发送模拟数据测试
1)启动SpringBoot项目
2)在linux启动模拟数据
(1)修改application.yml : mock.url: http://window地址:8081/applog
注意: window地址必须是在linux虚拟机可以访问到ip地址.
(2)启动程序,生成日志
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
3)观察idea是否收到数据,如果没有收到数据, 请确认地址是否正确
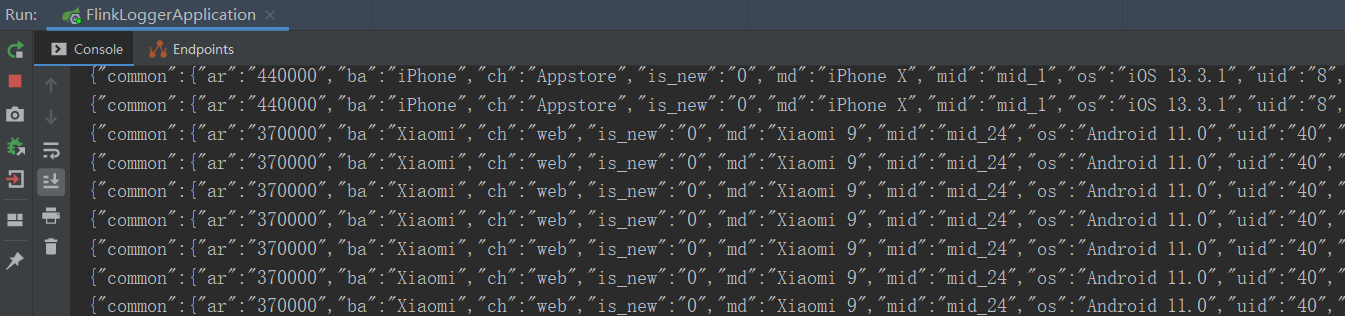
步骤5: 把日志落盘
在本实时项目中,落盘的日志后面并没有使用,主要考虑在企业应用中,采集到数据不仅仅应用到实时项目,也可以其他的一些需求也会可能会用到,比如离线需求。另外也可以起到数据备份的作用。落盘工具使用logback,类似于log4j
1)添加配置文件resources/logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--日志的根目录, 根据需要更改成日志要保存的目录-->
<property name="LOG_HOME" value="D:\Root\workSpace\IntelliJ IDEA 2019.2.4\workSpace\FlinkParent\output"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 需要更换我们的 Controller 类 -->
<logger name="com.yuange.flink.flinklogger.controller.LoggerController"
level="INFO" additivity="true">
<appender-ref ref="rollingFile"/>
<appender-ref ref="console"/>
</logger>
<root level="error" additivity="true">
<appender-ref ref="console"/>
</root>
</configuration>
2)在controller类上添加注解 @Slf4j
package com.yuange.flink.flinklogger.controller; import lombok.extern.slf4j.Slf4j; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; /** * @作者:袁哥 * @时间:2021/7/27 19:54 */ @RestController @Slf4j public class LoggerController { @GetMapping("/applog") public String doLog(@RequestParam("param")String log){ saveToDisk(log); return "success"; } private void saveToDisk(String strLog) { //log.info(logString) 这里的log对象默认情况如果idea不能识别, //写代码的时候会报错(执行并不会报错), 需要在idea安装一个插件: lombok, 看着就舒服了 log.info(strLog); } }
3)确认是否可以正常落盘, 并能在console打印日志.
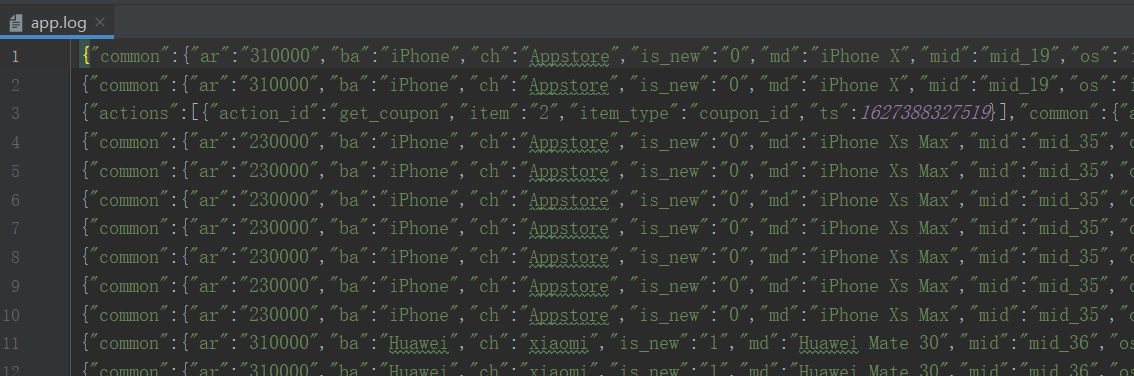
步骤6: 把日志直接写入到kafka中
1)在application.properties中配置Kafka相关配置
#============== kafka =================== # 指定kafka 代理地址,可以多个 spring.kafka.bootstrap-servers=hadoop162:9092,hadoop163:9092,hadoop164:9092 # 指定消息key和消息体的编解码方式 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
2)具体写入kafka的代码
package com.yuange.flink.flinklogger.controller; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; /** * @作者:袁哥 * @时间:2021/7/27 19:54 */ @RestController @Slf4j public class LoggerController { @GetMapping("/applog") public String doLog(@RequestParam("param")String log){ //数据落盘 saveToDisk(log); //写入kafka sendToKafka(log); return "success"; } @Autowired private KafkaTemplate<String,String> kafka; private void sendToKafka(String strLog) { kafka.send("ods_log",strLog); } private void saveToDisk(String strLog) { //log.info(logString) 这里的log对象默认情况如果idea不能识别, //写代码的时候会报错(执行并不会报错), 需要在idea安装一个插件: lombok, 看着就舒服了 log.info(strLog); } }
步骤7: 测试是否可以写入到kafka
1)启动Zookeeper
zk start
2)启动Kafka
kafka.sh start
3)启动终端消费者
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic osd_log
4)启动SpringBoot日志服务器
5)发送模拟数据
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
6)确认kafka是否收到数据
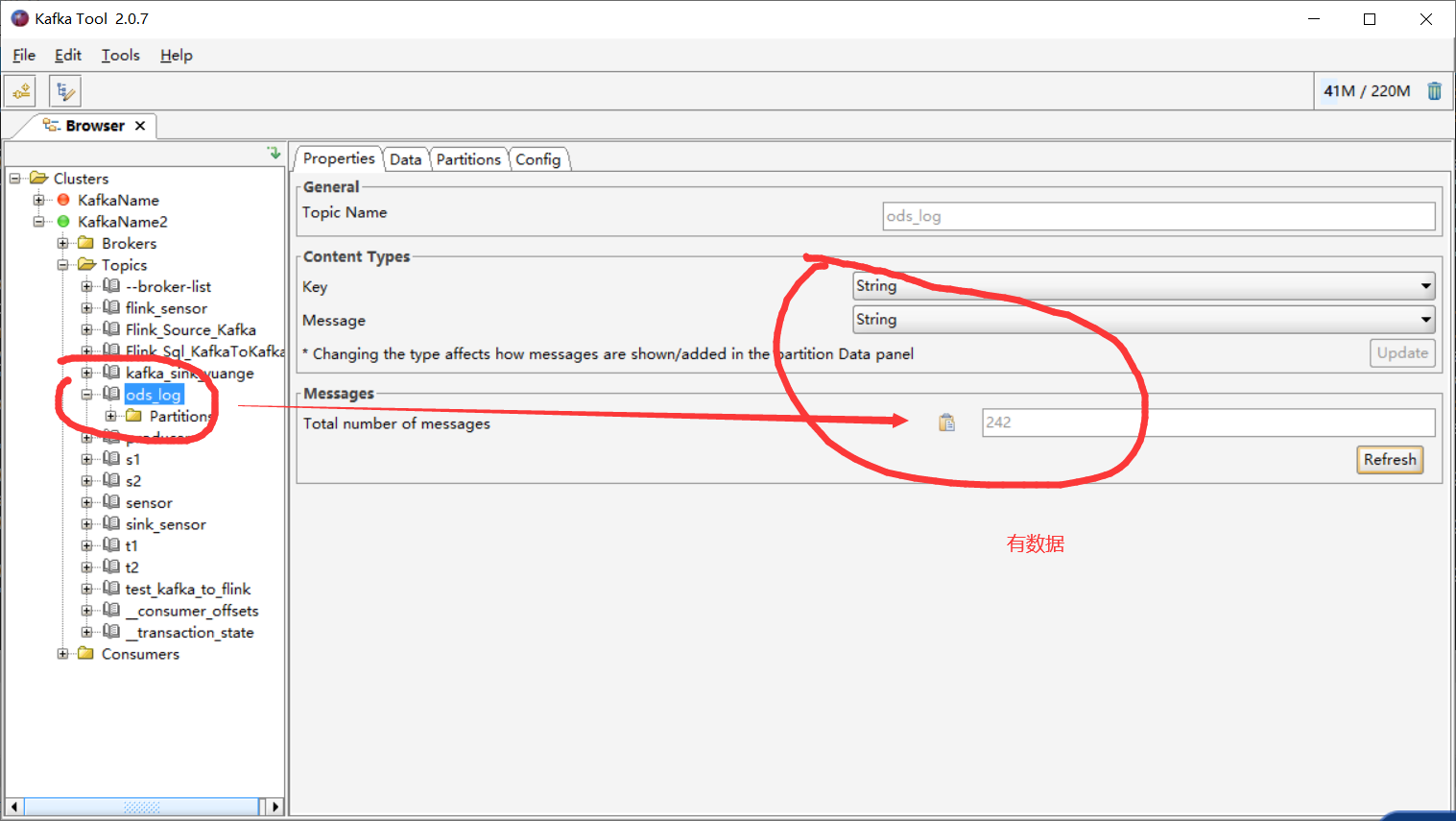
6.3 部署到linux测试数据采集
在idea中如果日志服务器可以测试通过, 现在打包, 然后部署到linux测试.
步骤1: logback.xml中的落盘目录修改为linux的目录
#创建applog目录
mkdir /opt/software/mock/mock_log/applog
<property name="LOG_HOME" value="/opt/software/mock/mock_log/applog"/>
步骤2: 打包flink-logger, 并发送到linux

步骤3: 启动gmll-logger服务器
cd /opt/module/applog
java -jar flink-logger-1.0-SNAPSHOT.jar
步骤4: 启动模拟数据
1)修改/opt/software/mock/mock_log/application.yml 文件
#http模式下,发送的地址
mock.url: "http://hadoop162:8081/applog"
2)启动程序,生产数据
java -jar gmall2020-mock-log-2020-12-18.jar
3)查看Kafka是否有数据
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic ods_log
第7章 搭建集群版数据采集服务器
7.1 部署Nginx
7.1.1 Nginx简介
Nginx (读作“engine x”), 是一个高性能的 HTTP 和反向代理服务器 , 特点是占有内存少,并发能力强,事实上 nginx 的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用 nginx 网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
7.1.2 Nginx和Tomcat的关系
除了 tomcat 以外, apache,nginx,jboss,jetty 等都是 http 服务器。nginx 和 apache 只支持静态页面和 CGI 协议的动态语言,比如 perl 、 php 等, 但是nginx不支持 java 。Java 程序只能通过与 tomcat 配合完成。 nginx 与 tomcat 配合,为 tomcat 集群提供反向代理服务、负载均衡等服务
7.1.3 Nginx功能
1)反向代理


2)负载均衡
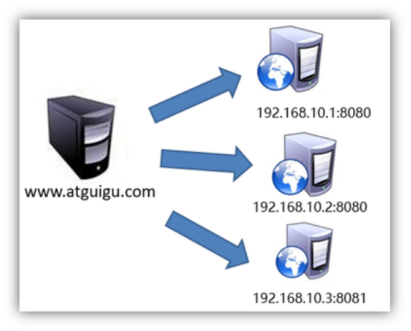
(1)轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某台服务器宕机,则自动剔除故障机器,使用户访问不受影响
(2)weight 指定轮询权重,weight值越大,分配到的几率就越高,主要用于后端每台服务器性能不均衡的情况。
(3)备机模式 平时不工作, 只有其他down 机的时候才会开始工作
(4)公平模式(第三方) 更智能的一个负载均衡算法,此算法可以根据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配。如果想要使用此调度算法,需要Nginx的upstream_fair模块。
3)动静分离
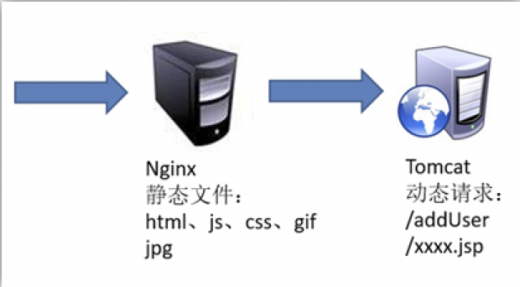
7.1.4 安装部署
1)使用 yum 安装依赖包
sudo yum -y install openssl openssl-devel pcre pcre-devel zlib zlib-devel gcc gcc-c++
2)下载 Nginx,如果已经有下载好的安装包, 此步骤可以省略
wget http://nginx.org/download/nginx-1.12.2.tar.gz
3)解压到当前目录
tar -zxvf nginx-1.12.2.tar.gz
4)编译和安装,进入解压后的根目录
./configure --prefix=/opt/module/nginx
make && make install
5)启动 Nginx
(1)进入安装目录:
cd /opt/module/nginx
(2)启动 nginx:
sbin/nginx
(3)关闭 nginx:
sbin/nginx -s stop
(4)重新加载:
sbin/nginx -s reload
注意:
1)Nginx 默认使用的是 80 端口, 由于非root用户不能使用 1024 以内的端口, 但是在生产环境下不建议使用root用户启动nginx, 主要从安全方面考虑
2)如果使用普通用户启动 Nginx, 需要先执行下面的命令来突破上面的限制:
sudo setcap cap_net_bind_service=+eip /opt/module/nginx/sbin/nginx
6)查看是否启动成功:http://hadoop162
ps -ef | grep nginx


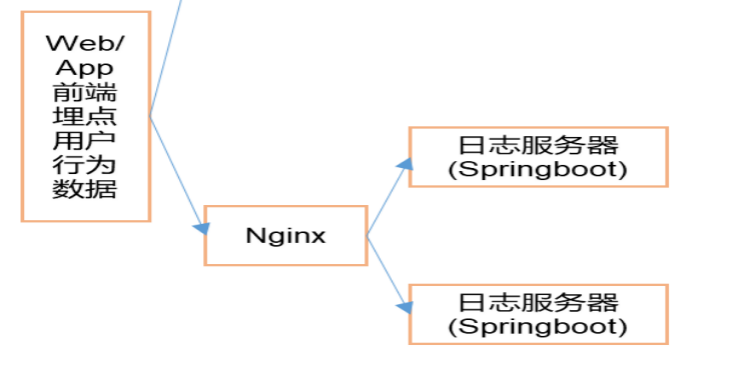
7.1.5 配置负载均衡
模拟数据以后应该发给nginx, 然后nginx再转发给我们的日志服务器,日志服务器我们会分别配置在hadoop162,hadoop163,hadoop164三台设备上
1)打开nginx配置文件
cd /opt/module/nginx/conf
vim nginx.conf
2)修改如下配置
http {
# 启动省略
upstream logcluster{
server hadoop162:8081 weight=1;
server hadoop163:8081 weight=1;
server hadoop164:8081 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#root html;
#index index.html index.htm;
# 代理的服务器集群 命名随意, 但是不能出现下划线
proxy_pass http://logcluster;
proxy_connect_timeout 10;
}
# 其他省略
}
7.2 分发日志服务器
日志服务器每个节点配置一个. (nginx只需要配置到hadoop162单台设备就行了)
xsync /opt/module/applog/
7.3 日志服务器群起脚本
1)新建脚本
vim /home/atguigu/bin/log-lg.sh
2)编写脚本
#!/bin/bash log_app=flink-logger-1.0-SNAPSHOT.jar nginx_home=/opt/module/nginx log_home=/opt/module/applog case $1 in "start") # 在hadoop162启动nginx if [[ -z "`ps -ef | awk '/nginx/ && !/awk/{print $n}'`" ]]; then echo "在hadoop162启动nginx" $nginx_home/sbin/nginx fi # 分别在162-164启动日志服务器$ for host in hadoop162 hadoop163 hadoop164 ; do echo "在 $host 上启动日志服务器" ssh $host "nohup java -jar $log_home/$log_app 1>$log_home/logger.log 2>&1 &" done ;; "stop") echo "在hadoop162停止nginx" $nginx_home/sbin/nginx -s stop for host in hadoop162 hadoop163 hadoop164 ; do echo "在 $host 上停止日志服务器" ssh $host "jps | awk '/$log_app/ {print \$1}' | xargs kill -9" done ;; *) echo "你启动的姿势不对" echo " log.sh start 启动日志采集" echo " log.sh stop 停止日志采集" ;; esac
3)赋予可执行权限
chmod +x /home/atguigu/bin/log-lg.sh
4)分发
xsync /home/atguigu/bin/log-lg.sh
7.4 测试负载均衡
发送模拟数据,注意把端口改为nginx的端口:80
1)启动zookeeper
2)启动kafka
3)启动日志服务器
log-lg.sh start
4)修改配置文件,将访问端口改为80
vim /opt/software/mock/mock_log/application.yml
#http模式下,发送的地址
mock.url: "http://hadoop162:80/applog"
5)启动kafka消费者
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop163:9092 --topic ods_log
6)启动程序,生产数据
cd /opt/software/mock/mock_log
java -jar gmall2020-mock-log-2020-12-18.jar
7)发现Kafka消费到了数据

第8章 业务数据采集
可以实时采集mysql数据的工具有:canal 和 maxwell,debzium
两个工具是竞品, 各有优缺点
8.1 使用canal实时采集mysql数据
8.1.1 什么是canal
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
8.1.2 canal使用场景
原始场景: otter中间件的一部分,阿里otter中间件的一部分,otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
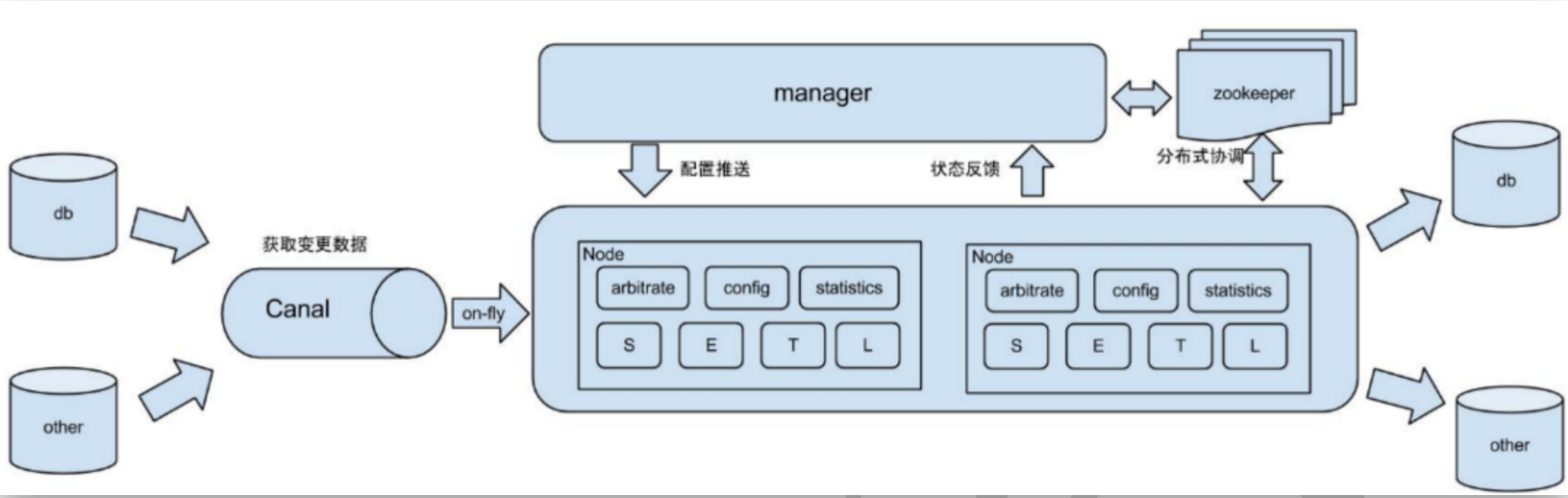
常见场景1: 更新缓存服务器

常用场景2: 制作拉链表
抓取业务数据新增变化表,用于制作拉链表,如果表中没有更新时间, 制作拉链表就需要使用canal实时监控数据的变化
常用场景3:用于实时统计
抓取业务表的新增变化数据,用于制作实时统计,我们实时数仓就是这种应用场景!
8.1.3 canal工作原理
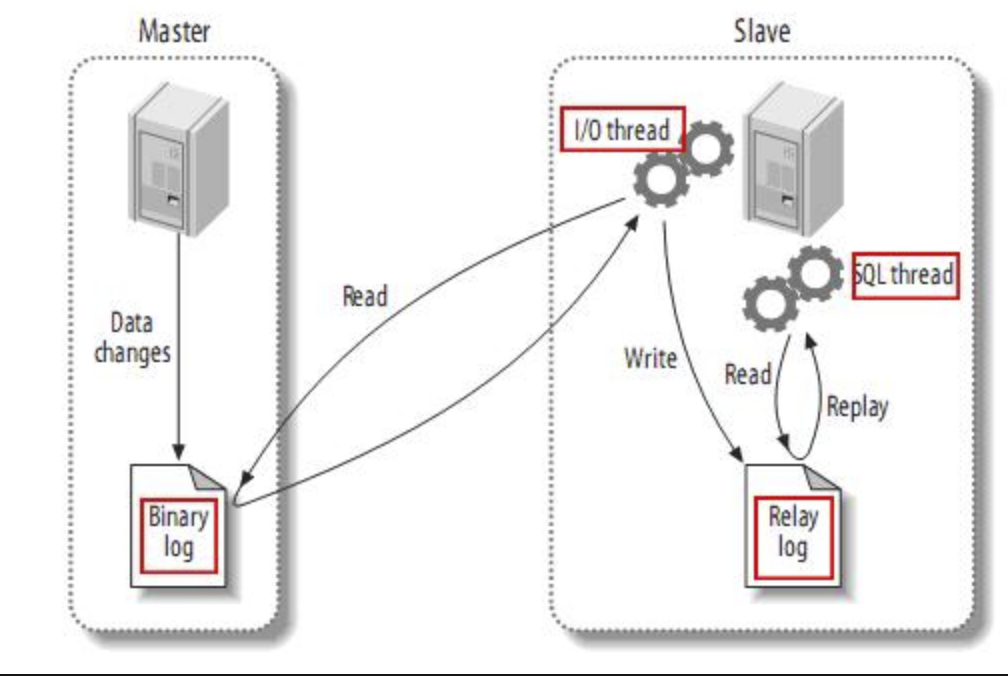
mysql的主从复制原理
1)MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
2)MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal工作原理
1)canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2)MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
3)canal 解析 binary log 对象(原始为 byte 流)

8.1.4 mysql的binlog
1)什么是binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。
二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括/两类文件:
A: 二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制的文件
B:二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
2)开启binlog
默认情况下, mysql是没有开启binlog的, 需要手动开启,开启步骤:
(1)找到mysql的配置文件:my.cnf. 大部分的mysql版本默认在: /etc/my.cnf.如果没有找到, 则可以通过下面的命令查找:
sudo find / -name my.cnf
(2)修改my.cnf. 在my.cnf文件中增加如下内容:
sudo vim /etc/my.cnf
server-id= 1 #日志前缀 log-bin=mysql-bin #同步格式 binlog_format=row #同步的库 binlog-do-db=flinkdb
3)配置说明
(1)server-id: mysql主从复制的时候, 主从之间每个实例必须有独一无二的id
(2)log-bin:这个表示binlog日志的前缀是mysql-bin,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成。 每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
(3)Binlog_format:mysql binlog的格式,有三种值,分别是statement, row, mixed,三者区别如下
statement:
语句级,binlog会记录每次一执行写操作的语句。相对row模式节省空间,但是可能产生不一致性,比如 update tt set create_date=now(),如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
row:
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间
mixed:
statement的升级版,一定程度上解决了,因为一些情况而造成的statement,模式不一致问题,在某些情况下譬如:当函数中包含 UUID() 时, 包含 AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
由于canal不是数据库, 是不能执行sql语句的, 所以, 只能设置为row格式
(3)binlog-do-db:设置把哪个database的变化写入到binlog, 如果不配置, 则所有database的变化都会写入到binlog,如果要设置多个数据库需要, 需要写多次这个参数的配置
binlog-do-db = a binlog-do-db = b
4)检测配置是否成功
(1)重启mysql服务器
sudo systemctl restart mysqld
(2)启动msyql客户端, 执行sql语句:
mysql -uroot -paaaaaa
show variables like'%log_bin%';
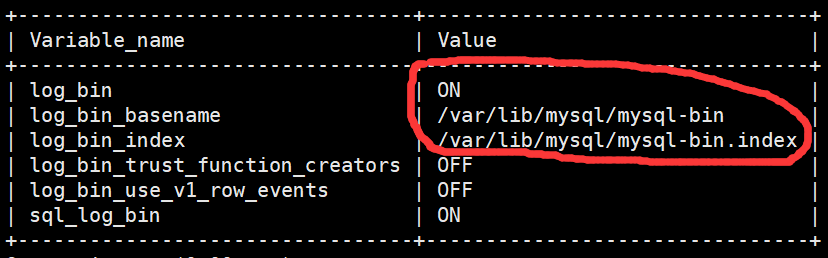
(3)也可以去对应的目录下查看是否生成log_bin文件
cd /var/lib/mysql
sudo ls

8.1.5 在mysql准备业务数据
CREATE DATABASE `flinkdb` CHARACTER SET utf8 COLLATE utf8_general_ci;
USE flinkdb;

8.1.6 下载和解压安装canal
1)在mysql创建canal用户,canal需要监控mysql数据, 在企业中一般拿不到root用户, 需新创建只读取权限的用户
Mysql> set global validate_password_policy=0; mysql> set global validate_password_length=4; mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY'canal'; mysql> FLUSH PRIVILEGES;
2)下载canal
wget -P /opt/software/canal https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
3)解压安装canal
mkdir /opt/module/canal
tar -zxvf /opt/software/canal/canal.deployer-1.1.4.tar.gz -C /opt/module/canal

8.1.7 配置canal
canal有两种配置:server级别和instance级别
1)server级别的配置是对整个canal进行配置, 是一些全局性的配置. 一个sever中可以配置多个instance

2)instance级别的配置, 是最小的订阅mysql的队列,比如example实例

3)canal server配置
vim /opt/module/canal/conf/canal.properties
#重点关注以下配置: canal.ip = hadoop162 # canal服务器绑定ip地址 canal.port = 11111 # canal端口号, 将来客户端通过这个端口号可以读到数据 canal.zkServers = hadoop162:2181,hadoop163:2181,hadoop164:2181 # zk地址, 用来管理canal的高可用 # tcp, kafka, RocketMQ # tcp:客户端通过tcp方式从Canal服务端拉取增量数据 # kafka:Canal服务端将增量数据同步到kafka中,客户端从kafka消费数据,此时客户端感知不到Canal的存在,只需要跟kafka交互。 # RocketMQ:同kafka,增量数据同步到RocketMQ中。 canal.serverMode = kafka canal.destinations = yuange # 配置实例, 如果有多个实例, 用逗号隔开. 我们创建一个yaunge实例 canal.mq.servers = hadoop162:9092,hadoop163:9092,hadoop164:9092
4)canal instance配置
(1)把目录名example改为yuange(其实就是和刚才的配置保存一致, 用来表示yuange实例)
mv /opt/module/canal/conf/example /opt/module/canal/conf/yuange

(2)打开实例配置文件:
vim /opt/module/canal/conf/yuange/instance.properties
(3)在其中配置要监控的mysql和监控到的数据发送到kafka
# canal实例(slave)的id, 不能和mysql的id重复. 可以自动生成, 无需手工配置 # canal.instance.mysql.slaveId=0 # 要监控的mysql地址 canal.instance.master.address = hadoop162:3306 # 连接mysql的用户名 canal.instance.dbUsername=canal # 连接mysql的密码 canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # 该实例监控的 库.表 默认所有库下所有表 canal.instance.filter.regex=flinkdb\\..* # 监控gmall数据库下所有包 # kafka topic配置 canal.mq.topic=ods_db # 注释掉此配置, 此配置是只发送到一个固定分区中 # canal.mq.partition=0 # 散列模式的分区数, 要和kafka的topic的分区数保持一致 canal.mq.partitionsNum=2 # 如何计算每条数据进入的分区 canal.mq.partitionHash= .*\\..*:$pk$ # 指定所有的表用主键hash得到分区索引
8.1.8 cana HA配置和启动canal
canal只是支持HA, 不支持高负载, 没有负载均衡的概念.
1)分发canal到hadoop163和hadoop164,注意: 修改canal.ip = hadoop162, 为hadoop163和hadoop164
xsync /opt/module/canal/
2)在hadoop162,hadoop163,hadoop164分别启动canal,注意:需要先启动zookeeper和kafka
/opt/module/canal/bin/startup.sh
3)制作canal统一启停脚本
vim /home/atguigu/bin/canal.sh
#!/bin/bash canal_home=/opt/module/canal case $1 in start) for host in hadoop162 hadoop163 hadoop164 ; do echo "========== $host 启动canal =========" ssh $host "source /etc/profile; ${canal_home}/bin/startup.sh" done ;; stop) for host in hadoop162 hadoop163 hadoop164 ; do echo "========== $host停止 canal =========" ssh $host "source /etc/profile; ${canal_home}/bin/stop.sh" done ;; *) echo "你启动的姿势不对" echo " start 启动canal集群" echo " stop 停止canal集群" ;; esac
8.1.9 测试kafka是否收到实时数据
1)起一个终端消费者, 消费ods_db
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic ods_db
2)修改配置文件
vim /opt/software/mock/mock_db/application.properties
#配置要连接的mysql数据库 spring.datasource.url=jdbc:mysql://hadoop162:3306/flinkdb?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8 spring.datasource.username=root spring.datasource.password=aaaaaa #业务日期 mock.date=2021-07-28
3)生产数据至Mysql
cd /opt/software/mock/mock_db
java -jar gmall2020-mock-db-2020-12-23.jar
4)观察消费者是否消费到数据, 如果没有消费到数据, 则需要重新检测canal配置
8.1.10 接收到的数据格式分析
发送到kafka的数据格式
{ "data":[ { "id":"350", "consignee":"蒋雄", "consignee_tel":"13325313235", "final_total_amount":"389.0", "order_status":"1005", "user_id":"62", "delivery_address":"第17大街第7号楼9单元324门", "order_comment":"描述353475", "out_trade_no":"822287931878949", "trade_body":"十月稻田 沁州黄小米 (黄小米 五谷杂粮 山西特产 真空装 大米伴侣 粥米搭档) 2.5kg等2件商品", "create_time":"2020-08-26 15:02:40", "operate_time":"2020-08-26 15:02:41", "expire_time":"2020-08-26 15:17:40", "tracking_no":null, "parent_order_id":null, "img_url":"http://img.gmall.com/933223.jpg", "province_id":"3", "benefit_reduce_amount":"108.0", "original_total_amount":"488.0", "feight_fee":"9.0" } ], "database":"gmall", "es":1598425361000, "id":73, "isDdl":false, "mysqlType":{ "id":"bigint(20)", "consignee":"varchar(100)", "consignee_tel":"varchar(20)", "final_total_amount":"decimal(16,2)", "order_status":"varchar(20)", "user_id":"bigint(20)", "delivery_address":"varchar(1000)", "order_comment":"varchar(200)", "out_trade_no":"varchar(50)", "trade_body":"varchar(200)", "create_time":"datetime", "operate_time":"datetime", "expire_time":"datetime", "tracking_no":"varchar(100)", "parent_order_id":"bigint(20)", "img_url":"varchar(200)", "province_id":"int(20)", "benefit_reduce_amount":"decimal(16,2)", "original_total_amount":"decimal(16,2)", "feight_fee":"decimal(16,2)" }, "old":[ { "order_status":"1002" } ], "pkNames":[ "id" ], "sql":"", "sqlType":{ "id":-5, "consignee":12, "consignee_tel":12, "final_total_amount":3, "order_status":12, "user_id":-5, "delivery_address":12, "order_comment":12, "out_trade_no":12, "trade_body":12, "create_time":93, "operate_time":93, "expire_time":93, "tracking_no":12, "parent_order_id":-5, "img_url":12, "province_id":4, "benefit_reduce_amount":3, "original_total_amount":3, "feight_fee":3 }, "table":"order_info", "ts":1598425365252, "type":"UPDATE" }
8.1.11 验证canal高可用是否正常工作
1)当前启动canal的时候, 只有一台设备会启动 yuange实例
#启动ZK客户端
zkCli.sh
get /otter/canal/destinations/yuange/running

2)停止hadoop163的canal, 然后观察
ssh hadoop163 /opt/module/canal/bin/stop.sh

8.2 使用maxwell实时采集mysql数据
8.2.1 什么是maxwell
maxwell 是由美国zendesk开源,用java编写的Mysql实时抓取软件。 其抓取的原理也是基于binlog。
8.2.2 Maxwell与canal的对比
1)Maxwell 没有 Canal那种server+client模式,只有一个server把数据发送到消息队列或redis。
2)Maxwell 有一个亮点功能,就是Canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
3)Maxwell不能直接支持HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
4)Maxwell只支持json格式,而Canal如果用Server+client模式的话,可以自定义格式。
5)Maxwell比Canal更加轻量级。
8.2.3 使用maxwell前的准备工作
1)在mysql中创建一个数据库, 用于存储maxwell的元数据(可以省略, maxwell会自动创建)
CREATE DATABASE `maxwell` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
2)创建可以操作数据库maxwell的用户:maxwell
USE maxwell; SET GLOBAL validate_password_policy=0; SET GLOBAL validate_password_length=4; GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY 'aaaaaa';
3)给用户maxwell分配操作其他数据库的权限
GRANT SELECT,REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'maxwell'@'%';
FLUSH PRIVILEGES;
8.2.4 安装和配置maxwell
1)下载maxwell
mkdir /opt/software/maxwell
wget -P /opt/software/maxwell https://github.com/zendesk/maxwell/releases/download/v1.27.1/maxwell-1.27.1.tar.gz
2)解压
tar -zxvf /opt/software/maxwell/maxwell-1.27.1.tar.gz -C /opt/module/
3)配置maxwell
cd /opt/module/maxwell-1.27.1
mv config.properties.example config.properties
vim config.properties
#添加如下配置: log_level=info producer=kafka kafka.bootstrap.servers=hadoop162:9092,hadoop163:9092,hadoop164:9092 kafka_topic=ods_db # 按照主键的hash进行分区, 如果不设置是按照数据库分区 producer_partition_by=primary_key # mysql login info host=hadoop162 user=maxwell password=aaaaaa # 排除掉不想监控的数据库 filter=exclude:gmall.* # 初始化维度表数据的时候使用 client_id=maxwell_1
8.2.5 启动maxwell
1)启动maxwell(先停止canal集群)
canal.sh stop
/opt/module/maxwell-1.27.1/bin/maxwell --config /opt/module/maxwell-1.27.1/config.properties --daemon
2)确认kafka是否收到数据,起一个终端消费者:
/opt/module/kafka-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic ods_db
3)在mysql中生成数据至mysql, 确认kafka是否收到数据
java -jar gmall2020-mock-db-2020-12-23.jar
4)查看消费情况
8.2.6 Maxwell发送到kafka的数据格式
{ "database":"flinkdb", "table":"cart_info", "type":"update", "ts":1627449145, "xid":14229, "xoffset":3823, "data":{ "id":141065, "user_id":"1539", "sku_id":23, "cart_price":40, "sku_num":3, "img_url":"http://47.93.148.192:8080/group1/M00/00/02/rBHu8l-0liuAJTluAAVP1d_tXYs725.jpg", "sku_name":"十月稻田 辽河长粒香 东北大米 5kg", "is_checked":null, "create_time":"2021-07-28 13:12:23", "operate_time":null, "is_ordered":1, "order_time":"2021-07-28 13:12:25", "source_type":"2401", "source_id":null }, "old":{ "is_ordered":0, "order_time":null } }
8.3 Canal和Maxwell发送到kafka的数据对比
1)为了方便做对比, 在gmall数据库下创建一个表:test_user_info
create table test_user_info(id int primary key, name varchar(255), tel char(11));
2)插入数据
insert into test_user_info values(1,'lisi','13838389438');
|
Canal |
Maxwell |
|
{ |
{ |
3)删除数据
delete from test_user_info where id=1;
|
Canal |
Maxwell |
|
{ |
{ |
4)更新数据
update test_user_info set name='zs' where id=1;
|
Canal |
Maxwell |
|
{ |
{ |
5)总结数据特点:
(1)日志结构:canal产生的数据会放在数组结构中,maxwell 以影响的数据为单位产生日志,即每影响一条数据就会产生一条日志。如果想知道这些日志是否是通过某一条sql产生的可以通过xid进行判断,相同的xid的日志来自同一sql
(2)数字类型:当原始数据是数字类型时,maxwell会尊重原始数据的类型不增加双引,不变为字符串。Canal一律转换为字符串。
(3)带原始数据字段定义:canal数据中会带入表结构。Maxwell更简洁。
8.4 Maxwell的初始化数据功能
对Mysql中的已有的旧数据, 如何导入到Kafka中? Canal无能为力, Maxwell提供了一个初始化功能, 可以满足我们的需求
/opt/module/maxwell-1.27.1/bin/maxwell-bootstrap --user maxwell --password aaaaaa --host hadoop162 --database flinkdb --table user_info --client_id maxwell_1
maxwell-bootstrap不具备将数据直接导入kafka或者hbase的能力,通过--client_id指定将数据交给哪个maxwell进程处理,在maxwell的conf.properties中配置