第6章 Flink流处理核心编程实战
6.1 基于埋点日志数据的网络流量统计
6.1.1 网站总浏览量(PV)的统计
衡量网站流量一个最简单的指标,就是网站的页面浏览量(Page View,PV)。用户每次打开一个页面便记录1次PV,多次打开同一页面则浏览量累计。
一般来说,PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量,如同一个来访者通过不断的刷新页面,也可以制造出非常高的PV。接下来我们就用咱们之前学习的Flink算子来实现PV的统计
1)准备数据:把数据文件 UserBehavior 复制到project的input目录下
2)用于封装数据的JavaBean类
package com.yuange.flink.day03; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/19 19:36 */ @NoArgsConstructor @AllArgsConstructor @Data public class UserBehavior { private Long userId; private Long itemId; private Integer categoryId; private String behavior; private Long timestamp; }
3)pv实现思路1: WordCount
package com.yuange.flink.day03; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @作者:袁哥 * @时间:2021/7/19 19:39 */ public class Flink_Project_PV { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.readTextFile("input/UserBehavior.csv") .map(line -> { String[] split = line.split(","); return new UserBehavior(Long.valueOf(split[0]),Long.valueOf(split[1]), Integer.valueOf(split[2]),split[3],Long.valueOf(split[4])); }) .filter(behavior -> "pv".equals(behavior.getBehavior())) .map(behavior -> Tuple2.of("pv",1L)) .returns(Types.TUPLE(Types.STRING,Types.LONG)) .keyBy(value -> value.f0) .sum(1) .print(); environment.execute(); } }
4)pv实现思路2: process
package com.yuange.flink.day03; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/19 19:39 */ public class Flink_Project_PV_Two { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.readTextFile("input/UserBehavior.csv") .map(line -> { String[] split = line.split(","); return new UserBehavior(Long.valueOf(split[0]),Long.valueOf(split[1]), Integer.valueOf(split[2]),split[3],Long.valueOf(split[4])); }) .keyBy(UserBehavior::getBehavior) .process(new KeyedProcessFunction<String, UserBehavior, Long>() { long count = 0; @Override public void processElement(UserBehavior value, Context ctx, Collector<Long> out) throws Exception { count++; out.collect(count); } }) .print(); environment.execute(); } }
6.1.2 网站独立访客数(UV)的统计
上一个案例中,我们统计的是所有用户对页面的所有浏览行为,也就是说,同一用户的浏览行为会被重复统计。而在实际应用中,我们往往还会关注,到底有多少不同的用户访问了网站,所以另外一个统计流量的重要指标是网站的独立访客数(Unique Visitor,UV)
1)准备数据:对于UserBehavior数据源来说,我们直接可以根据userId来区分不同的用户
2)UV实现思路
package com.yuange.flink.day03; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import scala.collection.mutable.HashSet; /** * @作者:袁哥 * @时间:2021/7/19 19:52 */ public class Flink_Project_UV { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.readTextFile("input/UserBehavior.csv") .flatMap((String line, Collector<Tuple2<String,Long>> out) -> { String[] split = line.split(","); UserBehavior userBehavior = new UserBehavior(Long.valueOf(split[0]), Long.valueOf(split[1]), Integer.valueOf(split[2]), split[3], Long.valueOf(split[4])); if ("pv".equals(userBehavior.getBehavior())) { out.collect(Tuple2.of("uv",userBehavior.getUserId())); } }) .returns(Types.TUPLE(Types.STRING,Types.LONG)) .keyBy(t -> t.f0) .process(new KeyedProcessFunction<String, Tuple2<String, Long>, Integer>() { HashSet<Long> userIds = new HashSet<>(); @Override public void processElement(Tuple2<String, Long> value, Context ctx, Collector<Integer> out) throws Exception { userIds.add(value.f1); out.collect(userIds.size()); } }) .print("uv"); environment.execute(); } }
6.2 市场营销商业指标统计分析
随着智能手机的普及,在如今的电商网站中已经有越来越多的用户来自移动端,相比起传统浏览器的登录方式,手机APP成为了更多用户访问电商网站的首选。对于电商企业来说,一般会通过各种不同的渠道对自己的APP进行市场推广,而这些渠道的统计数据(比如,不同网站上广告链接的点击量、APP下载量)就成了市场营销的重要商业指标。
6.2.1 APP市场推广统计 - 分渠道
1)封装数据的JavaBean类
package com.yuange.flink.day03; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/19 20:07 */ @NoArgsConstructor @AllArgsConstructor @Data public class MarketingUserBehavior { private Long userId; private String behavior; private String channel; private Long timestamp; }
2)实现代码
package com.yuange.flink.day03; import com.sun.javafx.scene.control.behavior.BehaviorBase; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import java.util.Arrays; import java.util.List; import java.util.Random; /** * @作者:袁哥 * @时间:2021/7/19 20:08 */ public class Flink_Project_AppAnalysis_By_Chanel { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.addSource(new AppMarketingDataSource()) .map(behavior -> Tuple2.of(behavior.getChannel() + "_" + behavior.getBehavior(),1L)) .returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(t -> t.f0) .sum(1) .print(); environment.execute(); } public static class AppMarketingDataSource extends RichSourceFunction<MarketingUserBehavior> { boolean canRun = true; Random random = new Random(); List<String> channels = Arrays.asList("huawwei", "xiaomi", "apple", "baidu", "qq", "oppo", "vivo"); List<String> behaviors = Arrays.asList("download", "install", "update", "uninstall"); @Override public void run(SourceContext<MarketingUserBehavior> ctx) throws Exception { while (canRun){ MarketingUserBehavior marketingUserBehavior = new MarketingUserBehavior( (long)random.nextInt(100000000), behaviors.get(random.nextInt(behaviors.size())), channels.get(random.nextInt(channels.size())), System.currentTimeMillis() ); ctx.collect(marketingUserBehavior); Thread.sleep(2000); } } @Override public void cancel() { canRun = false; } } }
6.2.2 APP市场推广统计 - 不分渠道
package com.yuange.flink.day03; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import java.util.Arrays; import java.util.List; import java.util.Random; /** * @作者:袁哥 * @时间:2021/7/19 20:08 */ public class Flink_Project_AppAnalysis { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.addSource(new AppMarketingDataSource()) .map(behavior -> Tuple2.of(behavior.getBehavior(),1L)) .returns(Types.TUPLE(Types.STRING, Types.LONG)) .keyBy(t -> t.f0) .sum(1) .print(); environment.execute(); } public static class AppMarketingDataSource extends RichSourceFunction<MarketingUserBehavior> { boolean canRun = true; Random random = new Random(); List<String> channels = Arrays.asList("huawwei", "xiaomi", "apple", "baidu", "qq", "oppo", "vivo"); List<String> behaviors = Arrays.asList("download", "install", "update", "uninstall"); @Override public void run(SourceContext<MarketingUserBehavior> ctx) throws Exception { while (canRun){ MarketingUserBehavior marketingUserBehavior = new MarketingUserBehavior( (long)random.nextInt(100000000), behaviors.get(random.nextInt(behaviors.size())), channels.get(random.nextInt(channels.size())), System.currentTimeMillis() ); ctx.collect(marketingUserBehavior); Thread.sleep(2000); } } @Override public void cancel() { canRun = false; } } }
6.3 各省份页面广告点击量实时统计
电商网站的市场营销商业指标中,除了自身的APP推广,还会考虑到页面上的广告投放(包括自己经营的产品和其它网站的广告)。所以广告相关的统计分析,也是市场营销的重要指标。
对于广告的统计,最简单也最重要的就是页面广告的点击量,网站往往需要根据广告点击量来制定定价策略和调整推广方式,而且也可以借此收集用户的偏好信息。更加具体的应用是,我们可以根据用户的地理位置进行划分,从而总结出不同省份用户对不同广告的偏好,这样更有助于广告的精准投放。
1)数据准备:在咱们当前的案例中,给大家准备了某电商网站的广告点击日志数据AdClickLog.csv, 本日志数据文件中包含了某电商网站一天用户点击广告行为的事件流,数据集的每一行表示一条用户广告点击行为,由用户ID、广告ID、省份、城市和时间戳组成并以逗号分隔。将文件放置项目目录: input下
2)定义用来封装数据的JavaBean
package com.yuange.flink.day03; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/19 20:21 */ @Data @AllArgsConstructor @NoArgsConstructor public class AdsClickLog { private Long userId; private Long adId; private String province; private String city; private Long timestamp; }
3)具体实现代码
package com.yuange.flink.day03; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import static org.apache.flink.api.common.typeinfo.Types.*; /** * @作者:袁哥 * @时间:2021/7/19 20:22 */ public class Flink_Project_Ads_Click { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.readTextFile("input/AdClickLog.csv") .map(line -> { String[] split = line.split(","); return new AdsClickLog(Long.valueOf(split[0]),Long.valueOf(split[1]),split[2],split[3],Long.valueOf(split[4])); }) .map(ck -> Tuple2.of(Tuple2.of(ck.getProvince(),ck.getAdId()),1L)) .returns(TUPLE(TUPLE(STRING, LONG), LONG)) .keyBy(new KeySelector<Tuple2<Tuple2<String, Long>, Long>, Tuple2<String,Long>>() { @Override public Tuple2<String, Long> getKey(Tuple2<Tuple2<String, Long>, Long> value) throws Exception { return value.f0; } }) .sum(1) .print("省份-广告"); environment.execute(); } }
6.4 订单支付实时监控
在电商网站中,订单的支付作为直接与营销收入挂钩的一环,在业务流程中非常重要。对于订单而言,为了正确控制业务流程,也为了增加用户的支付意愿,网站一般会设置一个支付失效时间,超过一段时间不支付的订单就会被取消。另外,对于订单的支付,我们还应保证用户支付的正确性,这可以通过第三方支付平台的交易数据来做一个实时对账。
1)需求: 来自两条流的订单交易匹配
对于订单支付事件,用户支付完成其实并不算完,我们还得确认平台账户上是否到账了。而往往这会来自不同的日志信息,所以我们要同时读入两条流的数据来做合并处理。
2)数据准备:订单数据从OrderLog.csv中读取,交易数据从ReceiptLog.csv中读取
3)JavaBean类的准备
package com.yuange.flink.day03; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/19 20:34 */ @NoArgsConstructor @AllArgsConstructor @Data public class OrderEvent { private Long orderId; private String eventType; private String txId; private Long eventTime; }
package com.yuange.flink.day03; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/19 20:35 */ @NoArgsConstructor @AllArgsConstructor @Data public class TxEvent { private String txId; private String payChannel; private Long eventTime; }
4)具体实现
package com.yuange.flink.day03; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoProcessFunction; import org.apache.flink.util.Collector; import java.util.HashMap; import java.util.Map; /** * @作者:袁哥 * @时间:2021/7/19 20:36 */ public class Flink_Project_Order { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(2); // 1. 读取Order流 SingleOutputStreamOperator<OrderEvent> orderEventSingleOutputStreamOperator = environment.readTextFile("input/OrderLog.csv") .map(line -> { String[] split = line.split(","); return new OrderEvent(Long.valueOf(split[0]), split[1], split[2], Long.valueOf(split[3])); }); // 2. 读取交易流 SingleOutputStreamOperator<TxEvent> txEventSingleOutputStreamOperator = environment.readTextFile("input/ReceiptLog.csv") .map(line -> { String[] split = line.split(","); return new TxEvent(split[0], split[1], Long.valueOf(split[2])); }); // 3. 两个流连接在一起 ConnectedStreams<OrderEvent, TxEvent> connect = orderEventSingleOutputStreamOperator.connect(txEventSingleOutputStreamOperator); // 4. 因为不同的数据流到达的先后顺序不一致,所以需要匹配对账信息. 输出表示对账成功与否 connect.keyBy("txId","txId") .process(new CoProcessFunction<OrderEvent,TxEvent,String>(){ // 存 txId -> OrderEvent Map<String, OrderEvent> orderMap = new HashMap<>(); // 存储 txId -> TxEvent Map<String, TxEvent> txMap = new HashMap<>(); @Override public void processElement1(OrderEvent value, Context ctx, Collector<String> out) throws Exception { // 获取交易信息 if (txMap.containsKey(value.getTxId())){ out.collect("订单: " + value + " 对账成功"); txMap.remove(value.getTxId()); }else { orderMap.put(value.getTxId(),value); } } @Override public void processElement2(TxEvent value, Context ctx, Collector<String> out) throws Exception { // 获取订单信息 if (orderMap.containsKey(value.getTxId())){ OrderEvent orderEvent = orderMap.get(value.getTxId()); out.collect("订单: " + orderEvent + " 对账成功"); orderMap.remove(value.getTxId()); }else { txMap.put(value.getTxId(),value); } } }) .print(); environment.execute(); } }
第7章 Flink流处理高阶编程
在上一个章节中,我们已经学习了Flink的基础编程API的使用,接下来,我们来学习Flink编程的高阶部分。所谓的高阶部分内容,其实就是Flink与其他计算框架不相同且占优势的地方,比如Window和Exactly-Once,接下来我们就对这些内容进行详细的学习
7.1 Flink的window机制
7.1.1 窗口概述
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而Window窗口是一种切割无限数据为有限块进行处理的手段。
在Flink中, 窗口(window)是处理无界流的核心. 窗口把流切割成有限大小的多个"存储桶"(bucket), 我们在这些桶上进行计算
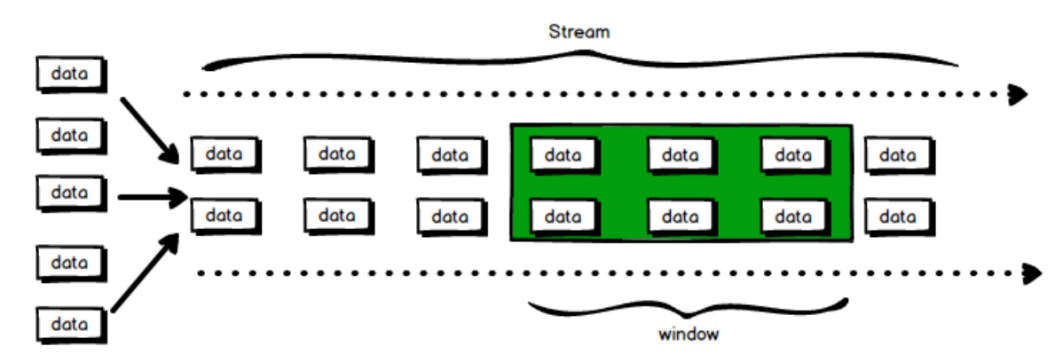
7.1.2 窗口的分类
窗口分为2类:
1)基于时间的窗口(时间驱动)
2)基于元素个数的(数据驱动)
7.1.2.1 基于时间的窗口
时间窗口包含一个开始时间戳(包括)和结束时间戳(不包括), 这两个时间戳一起限制了窗口的尺寸
在代码中, Flink使用TimeWindow这个类来表示基于时间的窗口,这个类提供了key查询开始时间戳和结束时间戳的方法, 还提供了针对给定的窗口获取它允许的最大时间戳的方法(maxTimestamp())
时间窗口又分4种:
1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小, 窗口与窗口之间不会重叠也没有缝隙,比如:如果指定一个长度为5分钟的滚动窗口, 当前窗口开始计算, 每5分钟启动一个新的窗口
滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。

示例代码:
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Tumbling_Windows { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .sum(1) .print(); environment.execute(); } }
说明:
(1)时间间隔可以通过: Time.milliseconds(x), Time.seconds(x), Time.minutes(x),等等来指定.
(2)我们传递给window函数的对象叫窗口分配器.
2)滑动窗口(Sliding Windows)
与滚动窗口一样, 滑动窗口也是有固定的长度,另外一个参数我们叫滑动步长, 用来控制滑动窗口启动的频率,所以,如果滑动步长小于窗口长度, 滑动窗口会重叠,这种情况下,一个元素可能会被分配到多个窗口中。例如, 滑动窗口长度10分钟, 滑动步长5分钟, 则, 每5分钟会得到一个包含最近10分钟的数据.
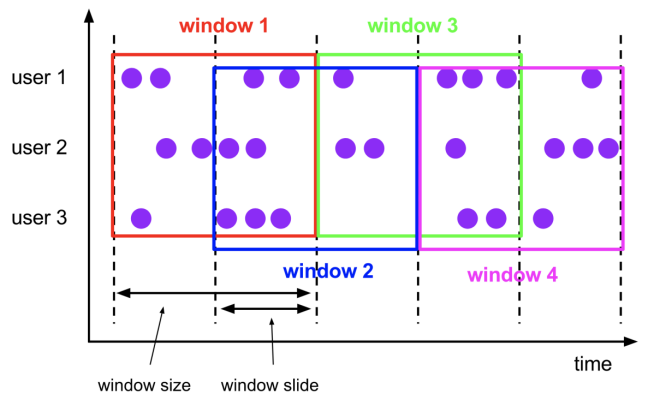
示例代码:
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Sliding_Windows { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))) //窗口大小、步长 .sum(1) .print(); environment.execute(); } }
3)会话窗口(Session Windows)
会话窗口分配器会根据活动的元素进行分组. 会话窗口不会有重叠, 与滚动窗口和滑动窗口相比, 会话窗口也没有固定的开启和关闭时间,如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔),我们可以配置静态的gap, 也可以通过一个gap extractor 函数来定义gap的长度. 当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口

示例代码:
(1)静态gap
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Session_Windows_static { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))) .sum(1) .print(); environment.execute(); } }
(2)动态gap
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.SessionWindowTimeGapExtractor; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Session_Windows_dynamic { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple2<String, Long>>() { @Override public long extract(Tuple2<String, Long> element) { return element.f0.length() * 1000; //返回gap值,单位毫秒 } })) .sum(1) .print(); environment.execute(); } }
创建原理:
因为会话窗口没有固定的开启和关闭时间, 所以会话窗口的创建和关闭与滚动,滑动窗口不同. 在Flink内部, 每到达一个新的元素都会创建一个新的会话窗口, 如果这些窗口彼此相距比较定义的gap小, 则会对他们进行合并. 为了能够合并, 会话窗口算子需要合并触发器和合并窗口函数: ReduceFunction, AggregateFunction, or ProcessWindowFunction
4)全局窗口(Global Windows)
全局窗口分配器会分配相同key的所有元素进入同一个 Global window. 这种窗口机制只有指定自定义的触发器时才有用. 否则, 不会做任何计算, 因为这种窗口没有能够处理聚集在一起元素的结束点.

示例代码:
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows; import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.SessionWindowTimeGapExtractor; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Global_Windows { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .window(GlobalWindows.create()) .sum(1) .print(); environment.execute(); } }
7.1.2.2 基于元素个数的窗口
按照指定的数据条数生成一个Window,与时间无关,分2类:
1)滚动窗口:默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行
2)实例代码(哪个窗口先达到3个元素, 哪个窗口就关闭. 不影响其他的窗口)
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Count_Windows { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .countWindow(3) .sum(1) .print(); environment.execute(); } }
3)滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围最多是3个元素
4)实例代码
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; /** * @作者:袁哥 * @时间:2021/7/19 21:11 */ public class Flink_Count_Windows_Sliding { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { Arrays.stream(value.split(" ")).forEach(word -> out.collect(Tuple2.of(word,1L))); } }) .keyBy(t -> t.f0) .countWindow(3,2) .sum(1) .print(); environment.execute(); } }
7.1.3 Window Function
前面指定了窗口的分配器,接着我们需要来指定如何计算,这事由window function来负责,一旦窗口关闭,window function 去计算处理窗口中的每个元素,window function 可以是ReduceFunction,AggregateFunction,or ProcessWindowFunction中的任意一种,
ReduceFunction,AggregateFunction更加高效, 原因就是Flink可以对到来的元素进行增量聚合 . ProcessWindowFunction 可以得到一个包含这个窗口中所有元素的迭代器, 以及这些元素所属窗口的一些元数据信息,ProcessWindowFunction不能被高效执行的原因是Flink在执行这个函数之前, 需要在内部缓存这个窗口上所有的元素
1)ReduceFunction(增量聚合函数)
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/19 23:00 */ public class Flink_ReduceFunction { public static void main(String[] args) { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { for (String word : value.split(" ")) { out.collect(Tuple2.of(word,1L)); } } }) .keyBy(t -> t.f0) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { System.out.println("Flink_ReduceFunction.reduce"); return Tuple2.of(value1.f0,value1.f1 + value2.f1); } }, new ProcessWindowFunction<Tuple2<String,Long>,String,String, TimeWindow>(){ @Override public void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception { System.out.println("Flink_ReduceFunction.process"); Tuple2<String, Long> tuple2 = elements.iterator().next(); out.collect(context.window() + " " + tuple2); } } ).print(); try { environment.execute(); } catch (Exception e) { e.printStackTrace(); } } }
2)AggregateFunction(增量聚合函数)
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/19 23:21 */ public class Flink_AggregateFunction { public static void main(String[] args) { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); env.socketTextStream("hadoop164", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .aggregate(new AggregateFunction<WaterSensor, Tuple2<Integer, Long>, Double>() { //创建一个累加器: 每个key执行一次 @Override public Tuple2<Integer, Long> createAccumulator() { System.out.println("createAccumulator"); return Tuple2.of(0, 0L); // f0: 表示水位 f1: 表示个数 } // 累加: 每来一个元素执行一次 @Override public Tuple2<Integer, Long> add(WaterSensor value, Tuple2<Integer, Long> accumulator) { System.out.println("add"); return Tuple2.of(accumulator.f0 + value.getVc(), accumulator.f1 + 1); } //返回最终结果: 窗口关闭的时候调用这个方法, 把结果放入后面的流中 @Override public Double getResult(Tuple2<Integer, Long> accumulator) { System.out.println("getResult"); return accumulator.f0 * 1.0 / accumulator.f1; } // 合并两个累加器: 只有sessionwindow才会使用, 其他的无效 @Override public Tuple2<Integer, Long> merge(Tuple2<Integer, Long> a, Tuple2<Integer, Long> b) { System.out.println("merge"); return null; } }, new ProcessWindowFunction<Double, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<Double> elements, Collector<String> out) throws Exception { out.collect(s + "_" + elements.iterator().next()); } } ) .print(); try { env.execute(); } catch (Exception e) { e.printStackTrace(); } } }
3)ProcessWindowFunction(全窗口函数)
package com.yuange.flink.day04; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows; import org.apache.flink.streaming.api.windowing.triggers.Trigger; import org.apache.flink.streaming.api.windowing.triggers.TriggerResult; import org.apache.flink.streaming.api.windowing.windows.GlobalWindow; import org.apache.flink.util.Collector; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/20 8:30 */ public class Flink_Widow_Global { public static void main(String[] args) { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); env.socketTextStream("hadoop164",8888) .flatMap(new FlatMapFunction<String, Tuple2<String,Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { for (String s : value.split(",")) { out.collect(Tuple2.of(s,1L)); } } }) .keyBy(t -> t.f0) .window(GlobalWindows.create()) .trigger(new Trigger<Tuple2<String, Long>, GlobalWindow>() {// 基于个数的窗口: 窗口元素的个数到达3的时候触发 // 每来一个元素, 触发一次这个方法 int count = 0; @Override public TriggerResult onElement(Tuple2<String, Long> element, long timestamp, GlobalWindow window, TriggerContext ctx) throws Exception { System.out.println("Flink_Widow_Global.onElement");; count++; if (count % 3 == 0){ return TriggerResult.FIRE_AND_PURGE; }else { return TriggerResult.CONTINUE; } } // 当基于处理时间的窗口, 会触发这个函数 @Override public TriggerResult onProcessingTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception { System.out.println("Flink_Widow_Global.onProcessingTime"); return null; } // 当基于实践时间的窗口, 会触发这个函数 @Override public TriggerResult onEventTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception { System.out.println("Flink_Widow_Global.onEventTime"); return null; } // 清除一些状态 @Override public void clear(GlobalWindow window, TriggerContext ctx) throws Exception { System.out.println("Flink_Widow_Global.clear"); } }) .process(new ProcessWindowFunction<Tuple2<String, Long>, String, String, GlobalWindow>() { @Override public void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<String> out) throws Exception { ArrayList<String> list = new ArrayList<>(); for (Tuple2<String, Long> element : elements) { list.add(element.f0); } out.collect("key=" + s + ", window=" + context.window() + ",words=" + list); } }) .print(); try { env.execute(); } catch (Exception e) { e.printStackTrace(); } } }
7.2 Keyed vs Non-Keyed Windows
其实, 在用window前首先需要确认应该是在keyBy后的流上用, 还是在没有keyBy的流上使用,在keyed streams上使用窗口, 窗口计算被并行的运用在多个task上, 可以认为每个task都有自己单独窗口,正如前面的代码所示,在非non-keyed stream上使用窗口, 流的并行度只能是1, 所有的窗口逻辑只能在一个单独的task上执行
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)))
需要注意的是: 非key分区的流上使用window, 如果把并行度强行设置为>1, 则会抛出异常
7.3 Flik中的时间语义与WaterMark
7.3.1 Flink中的时间语义
在Flink的流式操作中, 会涉及不同的时间概念
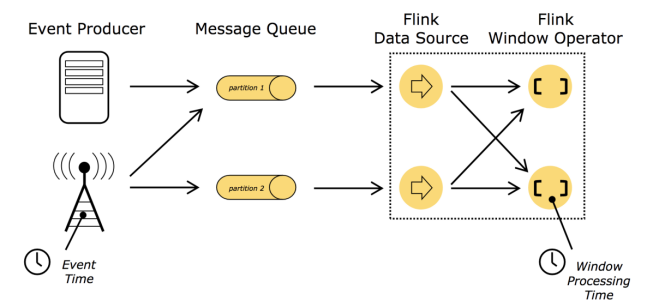
7.3.1.1 处理时间(process time)
处理时间是指的执行操作的各个设备的时间,对于运行在处理时间上的流程序, 所有的基于时间的操作(比如时间窗口)都是使用的设备时钟.比如, 一个长度为1个小时的窗口将会包含设备时钟表示的1个小时内所有的数据. 假设应用程序在 9:15am分启动, 第1个小时窗口将会包含9:15am到10:00am所有的数据, 然后下个窗口是10:00am-11:00am, 等等
处理时间是最简单时间语义, 数据流和设备之间不需要做任何的协调. 他提供了最好的性能和最低的延迟. 但是, 在分布式和异步的环境下, 处理时间没有办法保证确定性, 容易受到数据传递速度的影响: 事件的延迟和乱序
在使用窗口的时候, 如果使用处理时间, 就指定时间分配器为处理时间分配器
7.3.1.2 事件时间(event time)
事件时间是指的这个事件发生的时间,在event进入Flink之前, 通常被嵌入到了event中, 一般作为这个event的时间戳存在,在事件时间体系中, 时间的进度依赖于数据本身, 和任何设备的时间无关,事件时间程序必须制定如何产生Event Time Watermarks(水印),在事件时间体系中, 水印是表示时间进度的标志(作用就相当于现实时间的时钟)
在理想情况下,不管事件时间何时到达或者他们的到达的顺序如何, 事件时间处理将产生完全一致且确定的结果,事件时间处理会在等待无序事件(迟到事件)时产生一定的延迟。由于只能等待有限的时间,因此这限制了确定性事件时间应用程序的可使用性。
假设所有数据都已到达,事件时间操作将按预期方式运行,即使在处理无序或迟到的事件或重新处理历史数据时,也会产生正确且一致的结果。例如,每小时事件时间窗口将包含带有事件时间戳的所有记录,该记录落入该小时,无论它们到达的顺序或处理时间。
在使用窗口的时候, 如果使用事件时间, 就指定时间分配器为事件时间分配器
注意: 、在1.12之前默认的时间语义是处理时间, 从1.12开始, Flink内部已经把默认的语义改成了事件时间
7.3.2 哪种时间更重要

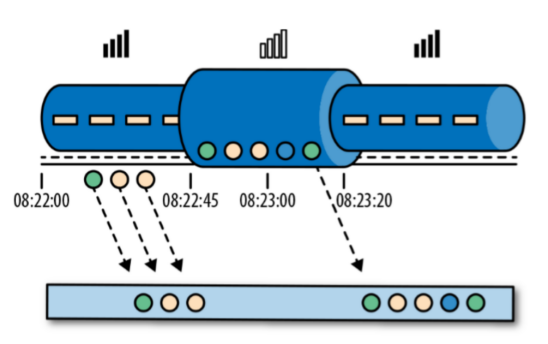
7.3.3 Flink中的WaterMark
支持event time的流式处理框架需要一种能够测量event time 进度的方式. 比如, 一个窗口算子创建了一个长度为1小时的窗口,那么这个算子需要知道事件时间已经到达了这个窗口的关闭时间, 从而在程序中去关闭这个窗口,事件时间可以不依赖处理时间来表示时间的进度,例如, 在程序中, 即使处理时间和事件时间有相同的速度, 事件时间可能会轻微的落后处理时间,另外一方面,使用事件时间可以在几秒内处理已经缓存在Kafka中多周的数据, 这些数据可以照样被正确处理, 就像实时发生的一样能够进入正确的窗口
这种在Flink中去测量事件时间的进度的机制就是 watermark(水印),watermark作为数据流的一部分在流动, 并且携带一个时间戳t,一个Watermark(t)表示在这个流里面事件时间已经到了时间t,意味着此时, 流中不应该存在这样的数据: 他的时间戳t2<=t (时间比较旧或者等于时间戳)
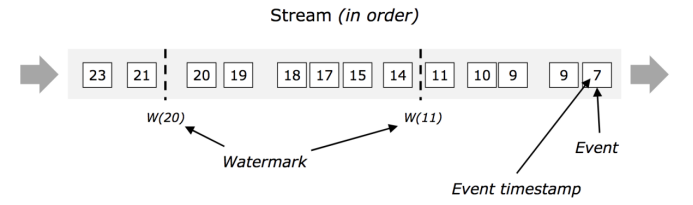
1)有序流中的水印:在下面的这个图中, 事件是有序的(按照他们自己的时间戳来看), watermark是流中一个简单的周期性的标记
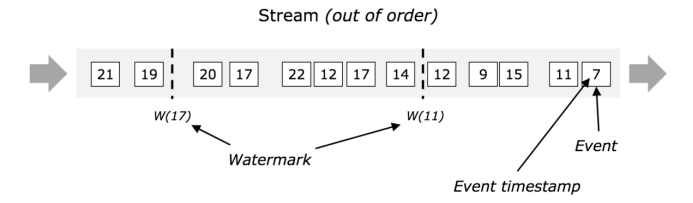
 2)乱序流中的水印:在下图中, 按照他们时间戳来看, 这些事件是乱序的, 则watermark对于这些乱序的流来说至关重要,通常情况下, 水印是一种标记, 是流中的一个点, 所有在这个时间戳(水印中的时间戳)前的数据应该已经全部到达. 一旦水印到达了算子, 则这个算子会提高他内部的时钟的值为这个水印的值
2)乱序流中的水印:在下图中, 按照他们时间戳来看, 这些事件是乱序的, 则watermark对于这些乱序的流来说至关重要,通常情况下, 水印是一种标记, 是流中的一个点, 所有在这个时间戳(水印中的时间戳)前的数据应该已经全部到达. 一旦水印到达了算子, 则这个算子会提高他内部的时钟的值为这个水印的值
7.3.4 Flink中如何产生水印
在 Flink 中, 水印由应用程序开发人员生成, 这通常需要对相应的领域有 一定的了解。完美的水印永远不会错:时间戳小于水印标记时间的事件不会再出现。在特殊情况下(例如非乱序事件流),最近一次事件的时间戳就可能是完美的水印。启发式水印则相反,它只估计时间,因此有可能出错, 即迟到的事件 (其时间戳小于水印标记时间)晚于水印出现。针对启发式水印, Flink 提供了处理迟到元素的机制。
设定水印通常需要用到领域知识。举例来说,如果知道事件的迟到时间不会超过 5 秒, 就可以将水印标记时间设为收到的最大时间戳减去 5 秒。 另 一种做法是,采用一个 Flink 作业监控事件流,学习事件的迟到规律,并以此构建水印生成模型。
7.3.5 EventTime和WaterMark的使用
Flink内置了两个WaterMark生成器:
1)Monotonously Increasing Timestamps(时间戳单调增长:其实就是允许的延迟为0)
WatermarkStrategy.forMonotonousTimestamps();
2)Fixed Amount of Lateness(允许固定时间的延迟)
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
3)代码实例:
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.time.Duration; /** * @作者:袁哥 * @时间:2021/7/20 16:33 */ public class Flink_OrderedWaterMark { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(1); WatermarkStrategy<WaterSensor> wms = WatermarkStrategy .<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 最大容忍的延迟时间 .withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { // 指定时间戳 @Override public long extractTimestamp(WaterSensor element, long recordTimestamp) { return element.getTs() * 1000; } }) // 如果某个并行度水印长时间不更新,则会强制把其他最小的水印向下游传递 .withIdleness(Duration.ofSeconds(20)); environment.socketTextStream("hadoop164",8888) .map(new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String value) throws Exception { String[] split = value.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); } }) .assignTimestampsAndWatermarks(wms) //指定水印和时间戳 .keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { String msg = "当前key=" + s + ",窗口=(" + context.window().getStart() / 1000 + "," + context.window().getEnd() / 1000 + ")" + ",共有" + elements.spliterator().estimateSize() + "条数据"; out.collect(msg); } }) .print(); environment.execute(); } }
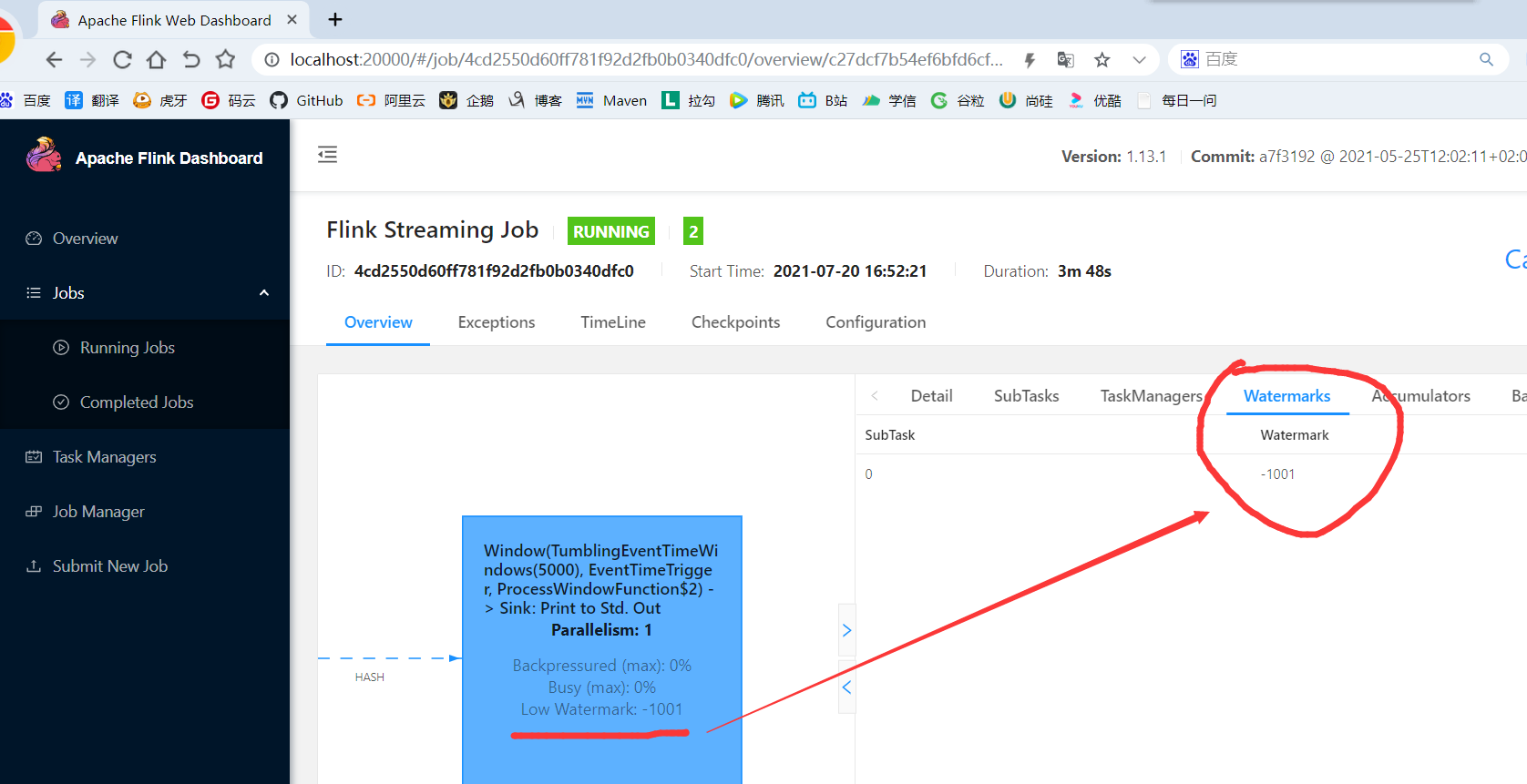
7.3.6 自定义WatermarkStrategy
有2种风格的WaterMark生产方式: periodic(周期性) and punctuated(间歇性).都需要继承接口: WatermarkGenerator
1)周期性
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.time.Duration; /** * @作者:袁哥 * @时间:2021/7/20 16:33 */ public class Flink_OrderedWaterMark_Period { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(1); // 创建水印生产策略 WatermarkStrategy<WaterSensor> wms = new WatermarkStrategy<WaterSensor>() { @Override public WatermarkGenerator<WaterSensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { System.out.println("createWatermarkGenerator"); return new MyPeriod(3); } }.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { @Override public long extractTimestamp(WaterSensor element, long recordTimestamp) { System.out.println("recordTimestamp=" + recordTimestamp); return element.getTs() * 1000; } }); environment.socketTextStream("hadoop164",8888) .map(new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String value) throws Exception { String[] split = value.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); } }) .assignTimestampsAndWatermarks(wms) //指定水印和时间戳 .keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { String msg = "当前key=" + s + ",窗口=(" + context.window().getStart() / 1000 + "," + context.window().getEnd() / 1000 + ")" + ",共有" + elements.spliterator().estimateSize() + "条数据"; out.collect(msg); } }) .print(); environment.execute(); } public static class MyPeriod implements WatermarkGenerator<WaterSensor> { private Long maxTs = Long.MIN_VALUE; private final Long maxDelay; // 允许的最大延迟时间 ms public MyPeriod(long maxDelay) { this.maxDelay = maxDelay * 1000; this.maxTs = Long.MIN_VALUE + this.maxDelay + 1; } // 每收到一个元素, 执行一次. 用来生产WaterMark中的时间戳 @Override public void onEvent(WaterSensor event, long eventTimestamp, WatermarkOutput output) { System.out.println("onEvent " + eventTimestamp); //有了新的元素找到最大的时间戳 Math.max(maxTs,eventTimestamp); System.out.println("maxTs=" + maxTs); } // 周期性的把WaterMark发射出去, 默认周期是200ms @Override public void onPeriodicEmit(WatermarkOutput output) { // System.out.println("onPeriodicEmit"); // 周期性的发射水印: 相当于Flink把自己的时钟调慢了一个最大延迟 output.emitWatermark(new Watermark(maxTs - maxDelay - 1)); } } }
2)间歇性
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 16:33 */ public class Flink_OrderedWaterMark_Punctuated { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(1); // 创建水印生产策略 WatermarkStrategy<WaterSensor> wms = new WatermarkStrategy<WaterSensor>() { @Override public WatermarkGenerator<WaterSensor> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { System.out.println("createWatermarkGenerator"); return new MyPunctuated(3); } }.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { @Override public long extractTimestamp(WaterSensor element, long recordTimestamp) { System.out.println("recordTimestamp=" + recordTimestamp); return element.getTs() * 1000; } }); environment.socketTextStream("hadoop164",8888) .map(new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String value) throws Exception { String[] split = value.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); } }) .assignTimestampsAndWatermarks(wms) //指定水印和时间戳 .keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { String msg = "当前key=" + s + ",窗口=(" + context.window().getStart() / 1000 + "," + context.window().getEnd() / 1000 + ")" + ",共有" + elements.spliterator().estimateSize() + "条数据"; out.collect(msg); } }) .print(); environment.execute(); } public static class MyPunctuated implements WatermarkGenerator<WaterSensor> { private Long maxTs = Long.MIN_VALUE; private final Long maxDelay; // 允许的最大延迟时间 ms public MyPunctuated(long maxDelay) { this.maxDelay = maxDelay * 1000; this.maxTs = Long.MIN_VALUE + this.maxDelay + 1; } // 每收到一个元素, 执行一次. 用来生产WaterMark中的时间戳 @Override public void onEvent(WaterSensor event, long eventTimestamp, WatermarkOutput output) { System.out.println("onEvent---" + eventTimestamp); //有了新的元素找到最大的时间戳 maxTs = Math.max(maxTs, eventTimestamp); output.emitWatermark(new Watermark(maxTs - maxDelay -1)); } @Override public void onPeriodicEmit(WatermarkOutput output) { // 不需要实现 } } }
7.3.7 多并行度下WaterMark的传递
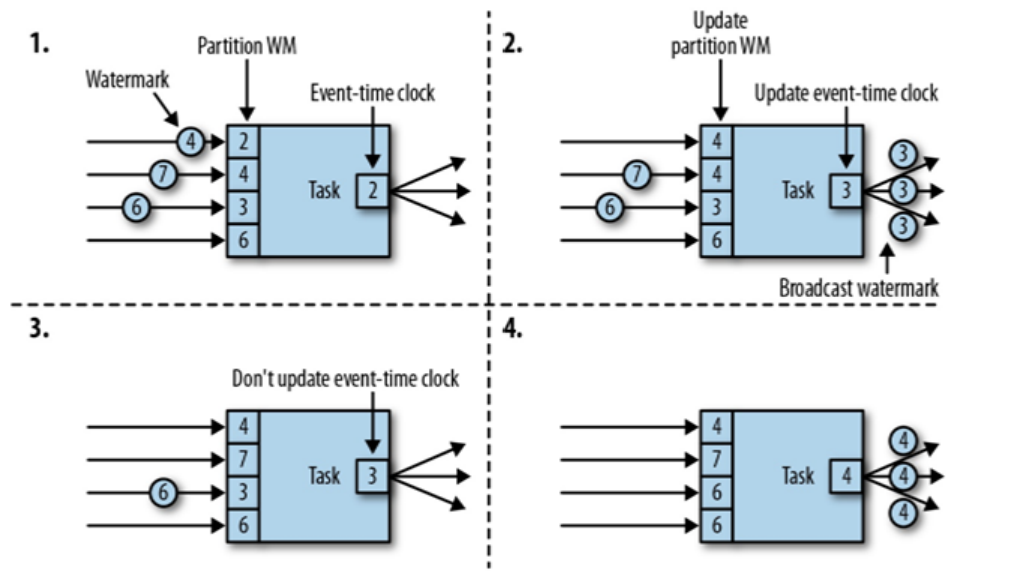
总结: 多并行度的条件下, 向下游传递WaterMark的时候, 总是以最小的那个WaterMark为准! 木桶原理!
7.4 窗口允许迟到的数据
已经添加了wartemark之后, 仍有数据会迟到怎么办? Flink的窗口, 也允许迟到数据。当触发了窗口计算后, 会先计算当前的结果, 但是此时并不会关闭窗口.以后每来一条迟到数据, 则触发一次这条数据所在窗口计算(增量计算)。那么什么时候会真正的关闭窗口呢? wartermark 超过了窗口结束时间+等待时间
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
注意:允许迟到只能运用在event time上
7.5 侧输出流(sideOutput)
7.5.1 接收窗口关闭之后的迟到数据
允许迟到数据, 窗口也会真正的关闭, 如果还有迟到的数据怎么办? Flink提供了一种叫做侧输出流的来处理关窗之后到达的数据
1)新建工具类YuangeUtil
package com.yuange.flink.utils; import java.util.ArrayList; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 18:47 */ public class YuangeUtil { public static <T> List<T> toList(Iterable<T> it){ ArrayList<T> list = new ArrayList<>(); for (T t : it) { list.add(t); } return list; } }
2)代码实现
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import com.yuange.flink.utils.YuangeUtil; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.time.Duration; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 18:40 */ public class Flink_Sideout { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); SingleOutputStreamOperator<String> main = env.socketTextStream("hadoop164", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }) .assignTimestampsAndWatermarks( WatermarkStrategy .<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)) .withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() { @Override public long extractTimestamp(WaterSensor element, long recordTimestamp) { return element.getTs() * 1000; //时间戳返回值必须是毫秒 } }) // 如果某个并行度水印长时间不更新,则会强制把其他最小的水印向下游传递 .withIdleness(Duration.ofSeconds(20)) ) .keyBy(WaterSensor::getId) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .sideOutputLateData(new OutputTag<WaterSensor>("late") { }) //窗口关闭之后来的数据, 会放入这个侧输出流 .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String key, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { List<WaterSensor> waterSensors = YuangeUtil.toList(elements); out.collect(key + "----" + waterSensors + "-----" + context.window()); } }); main.print(); main.getSideOutput(new OutputTag<WaterSensor>("late"){}).print(); env.execute(); } }
7.5.2 使用侧输出流把一个流拆成多个流
split算子可以把一个流分成两个流, 从1.12开始已经被移除了. 官方建议我们用侧输出流来替换split算子的功能.
需求: 采集监控传感器水位值,将水位值高于5cm的值输出到side output
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import com.yuange.flink.utils.YuangeUtil; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.time.Duration; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 18:40 */ public class Flink_Sideout_Two { public static void main(String[] args) throws Exception { OutputTag<WaterSensor> tag = new OutputTag<WaterSensor>("alert") {}; Configuration configuration = new Configuration(); configuration.setInteger("rest.port",20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration); environment.setParallelism(1); // 单独把超过20的水位的数据放入到一个单独的流中, 其他的数据还在主流中 SingleOutputStreamOperator<String> main = environment.socketTextStream("hadoop164", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }) .process(new ProcessFunction<WaterSensor, String>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { if (value.getVc() < 20) { out.collect(value + "正常数据"); } else { ctx.output(tag, value); } } }); main.print(); main.getSideOutput(tag).print("预警流"); environment.execute(); } }
7.6 ProcessFunction API(底层API)
我们之前学习的转换算子是无法访问事件的时间戳信息和水位线信息的。而这在一些应用场景下,极为重要。例如MapFunction这样的map转换算子就无法访问时间戳或者当前事件的事件时间。
基于此,DataStream API提供了一系列的Low-Level转换算子。可以访问时间戳、watermark以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。Process Function用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window函数和转换算子无法实现)。例如,Flink SQL就是使用Process Function实现的。
Flink提供了8个Process Function:
7.6.1 ProcessFunction
env .socketTextStream("hadoop164", 8888) .map(line -> { String[] datas = line.split(","); return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2])); }) .process(new ProcessFunction<WaterSensor, String>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { out.collect(value.toString()); } }) .print();
7.6.2 KeyedProcessFunction
env .socketTextStream("hadoop164", 8888) .map(line -> { String[] datas = line.split(","); return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2])); }) .keyBy(ws -> ws.getId()) .process(new KeyedProcessFunction<String, WaterSensor, String>() { // 泛型1:key的类型 泛型2:输入类型 泛型3:输出类型 @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { System.out.println(ctx.getCurrentKey()); out.collect(value.toString()); } }) .print();
7.6.3 CoProcessFunction
package com.yuange.flink.day04; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 19:26 */ public class Flink_CoProcessFunction { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1); DataStreamSource<Integer> integerDataStreamSource = environment.fromElements(1, 3, 4, 5, 6); DataStreamSource<String> stringDataStreamSource = environment.fromElements("a", "d", "e"); ConnectedStreams<Integer, String> connect = integerDataStreamSource.connect(stringDataStreamSource); connect.process(new CoProcessFunction<Integer, String, String>() { @Override public void processElement1(Integer value, Context ctx, Collector<String> out) throws Exception { out.collect(value.toString()); } @Override public void processElement2(String value, Context ctx, Collector<String> out) throws Exception { out.collect(value); } }) .print(); environment.execute(); } }
7.6.4 ProcessJoinFunction
package com.yuange.flink.day04; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.JoinFunction; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; /** * @作者:袁哥 * @时间:2021/7/20 19:30 */ public class Flink_ProcessJoinFunction { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); SingleOutputStreamOperator<WaterSensor> s1 = environment.socketTextStream("hadoop164", 8888) // 在socket终端只输入毫秒级别的时间戳 .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }); SingleOutputStreamOperator<WaterSensor> s2 = environment.socketTextStream("hadoop164", 9999) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }); s1.join(s2).where(WaterSensor::getId).equalTo(WaterSensor::getId) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .apply(new JoinFunction<WaterSensor, WaterSensor, String>() { @Override public String join(WaterSensor first, WaterSensor second) throws Exception { return "first=" + first + ",second=" + second; } }) .print(); environment.execute(); } }
7.6.5 BroadcastProcessFunction
后面专门讲解
7.6.6 KeyedBroadcastProcessFunction
keyBy之后使用
7.6.7 ProcessWindowFunction
添加窗口之后使用
7.6.8 ProcessAllWindowFunction
全窗口函数之后使用
7.7 定时器
基于处理时间或者事件时间处理过一个元素之后, 注册一个定时器, 然后指定的时间执行,Context和OnTimerContext所持有的TimerService对象拥有以下方法:
1)currentProcessingTime(): Long 返回当前处理时间
2)currentWatermark(): Long 返回当前watermark的时间戳
3)registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前key的processing time的定时器。当processing time到达定时时间时,触发timer。
4)registerEventTimeTimer(timestamp: Long): Unit 会注册当前key的event time 定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。
5)deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定时器。如果没有这个时间戳的定时器,则不执行。
6)deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时器,如果没有此时间戳的定时器,则不执行。
7.7.1 基于处理时间的定时器
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 19:42 */ public class Flink_Timer { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { // 如果水位值超过10, 则注册定时器, 发出水位预警 if (value.getVc() > 10){ long millis = System.currentTimeMillis(); // 当前时间5s之后触发定时器 ctx.timerService().registerProcessingTimeTimer(millis + 5000); } } // 当定时器触发的时候, 会回调这个方法 @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception { out.collect("红色预警=" + ctx.getCurrentKey() + "水位超过10"); } }) .print(); env.execute(); } }
7.7.2 基于事件时间的定时器
在测试的时候, 脑子里面要上课想着: 时间进展依据的是watermark
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 19:42 */ public class Flink_Timer_Two { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); env .socketTextStream("hadoop164", 8888) .map(line -> { String[] data = line.split(","); return new WaterSensor(data[0], Long.valueOf(data[1]), Integer.valueOf(data[2])); }) .assignTimestampsAndWatermarks( WatermarkStrategy .<WaterSensor>forMonotonousTimestamps() .withTimestampAssigner((ws, ts) -> ws.getTs() * 1000) ) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { // 如果水位值超过10, 则注册定时器, 发出水位预警 if (value.getVc() > 10) { // 当前时间5s之后触发定时器 ctx.timerService().registerEventTimeTimer(value.getTs() * 1000 + 5000); } } // 当定时器触发的时候, 会回调这个方法 @Override public void onTimer(long timestamp, // 定时器的时间 OnTimerContext ctx, Collector<String> out) throws Exception { System.out.println(timestamp); out.collect("红色预警: " + ctx.getCurrentKey() + " 水位超过10"); } }) .print(); env.execute(); } }
7.7.3 定时器练习
需求:监控水位传感器的水位值,如果水位值在5s之内(event time)连续上升,则报警。
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 19:42 */ public class Flink_Timer_Project { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(1); SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop164", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2])); }); WatermarkStrategy<WaterSensor> wms = WatermarkStrategy.<WaterSensor>forMonotonousTimestamps() .withTimestampAssigner((element, recordTimestamp) -> element.getTs() * 1000); stream.assignTimestampsAndWatermarks(wms) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { Integer lastVc; private long timerTs; boolean isFirst = true; @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { /* 1. 第一条数据来了之后, 注册一个5秒后触发的定时器 2. 下一条数据来了之后, 判断与上一条的大小关系 3. 如果大于等于上一条, 不用管 4. 如果小于上一条则删除定时器 5. 定时器如果触发, 重新注册一个新的定时器 */ if (isFirst){ // 注册定时器 timerTs = ctx.timestamp() + 5000; ctx.timerService().registerEventTimeTimer(timerTs); isFirst = false; }else { // 判断与上次的水位的比较 if (value.getVc() < lastVc){ // 水位下降 // 删除定时器 ctx.timerService().deleteEventTimeTimer(timerTs); // 当定时器被删之后,需要重新注册一个新的定时器 timerTs = ctx.timestamp() + 5000; ctx.timerService().registerEventTimeTimer(timerTs); }else { System.out.println("水位上升或者不变"); } } lastVc = value.getVc(); } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception { out.collect(ctx.getCurrentKey() + " 在5s内水位连续上升, 发出红色预警"); isFirst = true; } }) .print(); env.execute(); } }
7.8 Flink状态编程
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。
SparkStreaming在状态管理这块做的不好, 很多时候需要借助于外部存储(例如Redis)来手动管理状态, 增加了编程的难度,Flink的状态管理是它的优势之一
7.8.1 什么是状态
在流式计算中有些操作一次处理一个独立的事件(比如解析一个事件), 有些操作却需要记住多个事件的信息(比如窗口操作),那些需要记住多个事件信息的操作就是有状态的,流式计算分为无状态计算和有状态计算两种情况。
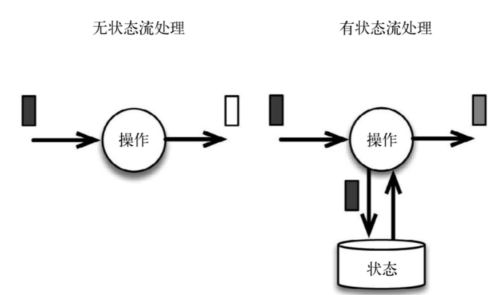
无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收水位数据,并在水位超过指定高度时发出警告。
有状态的计算则会基于多个事件输出结果。以下是一些例子。例如,计算过去一小时的平均水位,就是有状态的计算。所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差20cm以上的水位差读数,则发出警告,这是有状态的计算。流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
7.8.2 为什么需要管理状态
下面的几个场景都需要使用流处理的状态功能:
1)去重:数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
2)检测:检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
3)聚合:对一个时间窗口内的数据进行聚合分析,分析一个小时内水位的情况
4)更新机器学习模型:在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
7.8.3 Flink中的状态分类
Flink包括两种基本类型的状态Managed State和Raw State
|
Managed State |
Raw State |
|
|
状态管理方式 |
Flink Runtime托管, 自动存储, 自动恢复, 自动伸缩 |
用户自己管理 |
|
状态数据结构 |
Flink提供多种常用数据结构, 例如:ListState, MapState等 |
字节数组: byte[] |
|
使用场景 |
绝大数Flink算子 |
所有算子 |
注意:从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State一般是在已有算子和Managed State不够用时,用户自定义算子时使用。在我们平时的使用中Managed State已经足够我们使用
7.8.4 Managed State的分类
对Managed State继续细分,它又有2种类型
a) Operator State(算子状态)
b) Keyed State(键控状态)
|
Operator State |
Keyed State |
|
|
适用用算子类型 |
可用于所有算子: 常用于source, sink, 例如 FlinkKafkaConsumer |
只能用于用于KeyedStream上的算子 |
|
状态分配 |
一个算子的子任务对应一个状态 |
一个Key对应一个State: 一个算子会处理多个Key, 则访问相应的多个State |
|
创建和访问方式 |
实现CheckpointedFunction或ListCheckpointed(已经过时)接口 |
重写RichFunction, 通过里面的RuntimeContext访问 |
|
横向扩展 |
并发改变时有多重重写分配方式可选: 均匀分配和合并后每个得到全量 |
并发改变, State随着Key在实例间迁移 |
|
支持的数据结构 |
ListState和BroadCastState |
ValueState, ListState,MapState ReduceState, AggregatingState |
7.8.5 算子状态的使用
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。(算子子任务之间的状态不能互相访问)
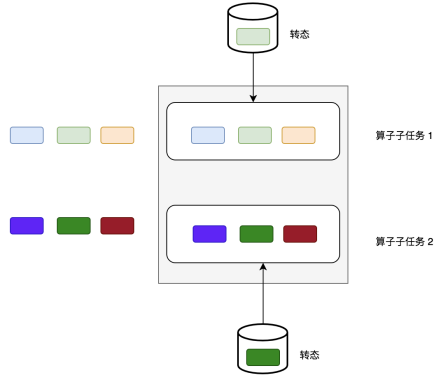
Operator State的实际应用场景不如Keyed State多,它经常被用在Source或Sink等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证Flink应用的Exactly-Once语义。
Flink为算子状态提供三种基本数据结构:
1)列表状态(List state):将状态表示为一组数据的列表
2)联合列表状态(Union list state):也是将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
说明:一种是均匀分配(List state),另外一种是将所有 State 合并为全量 State 再分发给每个实例(Union list state)。
3)广播状态(Broadcast state):是一种特殊的算子状态. 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
案例1: 列表状态
package com.yuange.flink.day05; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.state.FunctionInitializationContext; import org.apache.flink.runtime.state.FunctionSnapshotContext; import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/20 20:53 */ public class Flink_State_Operate_List { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port",20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(2); environment.enableCheckpointing(1000);// 每s做一次Checkpoint environment.socketTextStream("hadoop164",8888)// 在socket终端只输入毫秒级别的时间戳 .flatMap(new MyFlatMapFunction()) .print(); environment.execute(); } public static class MyFlatMapFunction implements FlatMapFunction<String,String>, CheckpointedFunction { private ArrayList<String> words = new ArrayList<>(); private ListState<String> wordList; @Override public void flatMap(String value, Collector<String> out) throws Exception { for (String s : value.split(",")) { words.add(s); } out.collect(words.toString()); if (value.contains("a")){ throw new RuntimeException(); } } //把状态进行快照(保存状态) @Override public void snapshotState(FunctionSnapshotContext context) throws Exception { // 周期性执行: // System.out.println("MyFlatMapFunction.snapshotState"); // 获取算子状态中的列表状态 //wordList.addAll(words); //追加 wordList.update(words); //覆盖 } // 初始化状态: 读取状态 @Override public void initializeState(FunctionInitializationContext context) throws Exception { // 程序启动时执行: 有几个并行度, 就执行几次 System.out.println("MyFlatMapFunction.initializeState"); // flink会从持久化存储的地方把数据恢复 wordList = context.getOperatorStateStore().getListState(new ListStateDescriptor<String>("wordList",String.class)); Iterable<String> strings = wordList.get(); for (String s : strings) { words.add(s); } } } }
案例2: 联合列表状态
package com.yuange.flink.day05; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.state.FunctionInitializationContext; import org.apache.flink.runtime.state.FunctionSnapshotContext; import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.ArrayList; /** * @作者:袁哥 * @时间:2021/7/20 20:53 */ public class Flink_State_Operate_UnList { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port",20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(2); environment.enableCheckpointing(1000);// 每s做一次Checkpoint environment.socketTextStream("hadoop164",8888)// 在socket终端只输入毫秒级别的时间戳 .flatMap(new MyFlatMapFunction()) .print(); environment.execute(); } public static class MyFlatMapFunction implements FlatMapFunction<String,String>, CheckpointedFunction { private ArrayList<String> words = new ArrayList<>(); private ListState<String> wordList; @Override public void flatMap(String value, Collector<String> out) throws Exception { for (String s : value.split(",")) { words.add(s); } out.collect(words.toString()); if (value.contains("a")){ throw new RuntimeException(); } } //把状态进行快照(保存状态) @Override public void snapshotState(FunctionSnapshotContext context) throws Exception { // 周期性执行: // System.out.println("MyFlatMapFunction.snapshotState"); // 获取算子状态中的列表状态 //wordList.addAll(words); //追加 wordList.update(words); //覆盖 } // 初始化状态: 读取状态 @Override public void initializeState(FunctionInitializationContext context) throws Exception { // 程序启动时执行: 有几个并行度, 就执行几次 System.out.println("MyFlatMapFunction.initializeState"); // flink会从持久化存储的地方把数据恢复 wordList = context.getOperatorStateStore().getUnionListState(new ListStateDescriptor<String>("wordList",String.class)); Iterable<String> strings = wordList.get(); for (String s : strings) { words.add(s); } } } }
案例3: 广播状态
从版本1.5.0开始,Apache Flink具有一种新的状态,称为广播状态。广播状态被引入以支持这样的用例:来自一个流的一些数据需要广播到所有下游任务,在那里它被本地存储,并用于处理另一个流上的所有传入元素。作为广播状态自然适合出现的一个例子,我们可以想象一个低吞吐量流,其中包含一组规则,我们希望根据来自另一个流的所有元素对这些规则进行评估。考虑到上述类型的用例,广播状态与其他算子状态的区别在于:
(1)它是一个map格式
(2)它只对输入有广播流和无广播流的特定算子可用
(3)这样的算子可以具有不同名称的多个广播状态。
package com.yuange.flink.day05; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 21:08 */ public class Flink_State_Operate_BroadCast { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port",20000); StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(conf).setParallelism(2); // 两个流: 一个数据流, 正常的数据. 另外一个流是: 控制流, 用来动态控制数据流中的数据的处理逻辑 DataStreamSource<String> dataStream = environment.socketTextStream("hadoop164", 8888); DataStreamSource<String> controlStream = environment.socketTextStream("hadoop164", 9999); //把控制流做成广播流 MapStateDescriptor<String, String> bdState = new MapStateDescriptor<>("bdState", String.class, String.class); BroadcastStream<String> broadcast = controlStream.broadcast(bdState); //用数据流去connect广播流 dataStream.connect(broadcast) .process(new BroadcastProcessFunction<String, String, String>() { // 处理数据流的数据 @Override public void processElement(String value, ReadOnlyContext ctx, Collector<String> out) throws Exception { ReadOnlyBroadcastState<String, String> broadcastState = ctx.getBroadcastState(bdState); String v = broadcastState.get("switch"); if ("1".equals(v)) { out.collect("使用1号逻辑处理数据"); } else if ("2".equals(v)) { out.collect("使用2号逻辑处理数据"); } else { out.collect("使用默认逻辑处理数据"); } } // 处理广播流的数据 @Override public void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception { // 把每天数据放入到广播状态 BroadcastState<String, String> broadcastState = ctx.getBroadcastState(bdState); broadcastState.put("switch",value); } }) .print(); environment.execute(); } }
7.8.6 键控状态的使用
键控状态是根据输入数据流中定义的键(key)来维护和访问的。
Flink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。
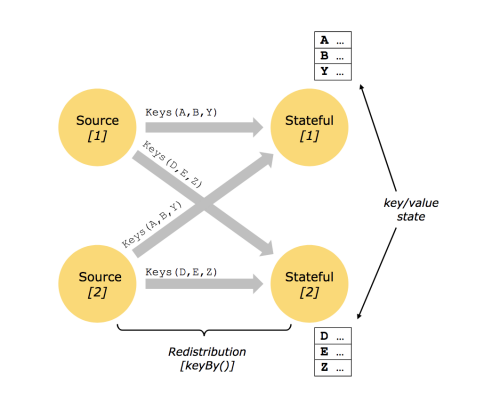
键控状态支持的数据类型
1)ValueState<T>:保存单个值. 每个key有一个状态值,设置使用 update(T), 获取使用 T value()
2)ListState<T>:
(1)保存元素列表.
(2)添加元素: add(T) addAll(List<T>)
(3)获取元素: Iterable<T> get()
(4)覆盖所有元素: update(List<T>)
3)ReducingState<T>:存储单个值,,表示把所有元素的聚合结果添加到状态中,与ListState类似, 但是当使用add(T)的时候ReducingState会使用指定的ReduceFunction进行聚合
4)AggregatingState<IN, OUT>:存储单个值,与ReducingState类似, 都是进行聚合. 不同的是, AggregatingState的聚合的结果和元素类型可以不一样
5)MapState<UK, UV>:
(1)存储键值对列表
(2)添加键值对: put(UK, UV) or putAll(Map<UK, UV>)
(3)根据key获取值: get(UK)
(4)获取所有: entries(), keys() and values()
(5)检测是否为空: isEmpty()
注意:
a) 所有的类型都有clear(),清空当前key的状态
b) 这些状态对象仅用于用户与状态进行交互
c) 状态不是必须存储到内存, 也可以存储在磁盘或者任意其他地方
d) 从状态获取的值与输入元素的key相关
案例1:ValueState:检测传感器的水位值,如果连续的两个水位值超过10,就输出报警。
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_Value { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private ValueState<Integer> lastVcState; @Override public void open(Configuration parameters) throws Exception { // control + alt + f lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState",Integer.class)); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { // 如果是第一次使用状态, 则状态的中的值 null Integer lastVc = lastVcState.value(); if (lastVc != null && value.getVc() > 10 && lastVc > 10) { out.collect(ctx.getCurrentKey() + " 连续两次水位超过10 预警"); } lastVcState.update(value.getVc()); } }) .print(); env.execute(); } }
案例2:ListState:针对每个传感器输出最高的3个水位值
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import com.yuange.flink.utils.YuangeUtil; import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import java.util.Comparator; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_List { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private ListState<Integer> top3State; @Override public void open(Configuration parameters) throws Exception { // control + alt + f top3State = getRuntimeContext() .getListState(new ListStateDescriptor<Integer>("top3State",Integer.class)); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { top3State.add(value.getVc()); List<Integer> list = YuangeUtil.toList(top3State.get()); list.sort(Comparator.reverseOrder());// 对list集合中数据原地排序 if (list.size() > 3){ // 如果长度大于3(其实是4), 删除最后一个 list.remove(list.size() - 1); } top3State.update(list); out.collect(ctx.getCurrentKey() + " " + list.toString()); } }) .print(); env.execute(); } }
案例3:ReducingState:计算每个传感器的水位和
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import com.yuange.flink.utils.YuangeUtil; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.api.common.state.ReducingState; import org.apache.flink.api.common.state.ReducingStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import java.util.Comparator; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_Reduce { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private ReducingState<WaterSensor> sumVcState; @Override public void open(Configuration parameters) throws Exception { ReducingState<WaterSensor> sumVcState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<WaterSensor>( "sumVcState", new ReduceFunction<WaterSensor>() { @Override public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception { value1.setVc(value1.getVc() + value2.getVc()); return value1; } }, WaterSensor.class )); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { sumVcState.add(value); out.collect(ctx.getCurrentKey() + "的水位和是: " + sumVcState.get().getVc()); } }) .print(); env.execute(); } }
案例4:AggregatingState:计算每个传感器的平均水位
写法一:
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.common.state.AggregatingState; import org.apache.flink.api.common.state.AggregatingStateDescriptor; import org.apache.flink.api.common.state.ReducingState; import org.apache.flink.api.common.state.ReducingStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_Aggregate { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private AggregatingState<WaterSensor, Double> avgState; class AvgAcc { Integer sumVc = 0; Long count = 0L; public Double getAvg(){ return sumVc * 1.0 / count; } } @Override public void open(Configuration parameters) throws Exception { avgState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<WaterSensor, AvgAcc, Double>( "avgState", new AggregateFunction<WaterSensor, AvgAcc, Double>() { @Override public AvgAcc createAccumulator() { return new AvgAcc(); } @Override public AvgAcc add(WaterSensor value, AvgAcc accumulator) { accumulator.sumVc += value.getVc(); accumulator.count += 1; return accumulator; } @Override public Double getResult(AvgAcc accumulator) { return accumulator.getAvg(); } @Override public AvgAcc merge(AvgAcc a, AvgAcc b) { a.sumVc += b.sumVc; a.count += b.count; return a; } }, AvgAcc.class )); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { avgState.add(value); out.collect(ctx.getCurrentKey() + " 的平均水位是: " + avgState.get()); } }) .print(); env.execute(); } }
写法二:
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.common.state.AggregatingState; import org.apache.flink.api.common.state.AggregatingStateDescriptor; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_Aggregate_Two { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private AggregatingState<WaterSensor, Double> avgState; @Override public void open(Configuration parameters) throws Exception { avgState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<WaterSensor, Tuple2<Integer, Long>, Double>( "avgState", new AggregateFunction<WaterSensor, Tuple2<Integer, Long>, Double>() { @Override public Tuple2<Integer, Long> createAccumulator() { return Tuple2.of(0, 0L); } @Override public Tuple2<Integer, Long> add(WaterSensor value, Tuple2<Integer, Long> acc) { return Tuple2.of(acc.f0 + value.getVc(), acc.f1 + 1L); } @Override public Double getResult(Tuple2<Integer, Long> acc) { return acc.f0 * 1.0 / acc.f1; } @Override public Tuple2<Integer, Long> merge(Tuple2<Integer, Long> a, Tuple2<Integer, Long> b) { return null; } }, Types.TUPLE(Types.INT, Types.LONG) )); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { avgState.add(value); out.collect(ctx.getCurrentKey() + " 的平均水位是: " + avgState.get()); } }) .print(); env.execute(); } }
案例5:MapState:去重: 去掉重复的水位值。思路: 把水位值作为MapState的key来实现去重, value随意
package com.yuange.flink.day05; import com.yuange.flink.day02.WaterSensor; import com.yuange.flink.utils.YuangeUtil; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.common.state.AggregatingState; import org.apache.flink.api.common.state.AggregatingStateDescriptor; import org.apache.flink.api.common.state.MapState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/20 22:33 */ public class Flink_State_KV_Map { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setInteger("rest.port", 20000); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.setParallelism(2); env.socketTextStream("hadoop164",8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0],Long.valueOf(split[1]),Integer.valueOf(split[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private MapState<Integer, Object> vcState; @Override public void open(Configuration parameters) throws Exception { vcState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Object>( "vcState", Integer.class, Object.class )); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { vcState.put(value.getVc(),new Object()); List<Integer> vcs = YuangeUtil.toList(vcState.keys()); out.collect(ctx.getCurrentKey() + " " + vcs); } }) .print(); env.execute(); } }
7.8.7 状态后端
每传入一条数据,有状态的算子任务都会读取和更新状态。由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务(子任务)都会在本地维护其状态,以确保快速的状态访问。
状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
状态后端主要负责两件事:
1)本地(taskmanager)的状态管理
2)将检查点(checkpoint)状态写入远程存储
状态后端的分类:状态后端作为一个可插入的组件, 没有固定的配置, 我们可以根据需要选择一个合适的状态后端.
Flink提供了3种状态后端(1.12及之前的版本):
1)MemoryStateBackend
内存级别的状态后端(默认)
存储方式:本地状态存储在TaskManager的内存中, checkpoint 存储在JobManager的内存中.
特点:快速, 低延迟, 但不稳定
使用场景: 1. 本地测试 2. 几乎无状态的作业(ETL) 3. JobManager不容易挂, 或者挂了影响不大. 4. 不推荐在生产环境下使用
2)FsStateBackend
存储方式: 本地状态在TaskManager内存, Checkpoint时, 存储在文件系统(hdfs)中
特点: 拥有内存级别的本地访问速度, 和更好的容错保证
使用场景: 1. 常规使用状态的作业. 例如分钟级别窗口聚合, join等 2. 需要开启HA的作业 3. 可以应用在生产环境中
3)RocksDBStateBackend
将所有的状态序列化之后, 存入本地的RocksDB数据库中.(一种NoSql数据库, KV形式存储)
存储方式: 1. 本地状态存储在TaskManager的RocksDB数据库中(实际是内存+磁盘) 2. Checkpoint在外部文件系统(hdfs)中.
使用场景: 1. 超大状态的作业, 例如天级的窗口聚合 2. 需要开启HA的作业 3. 对读写状态性能要求不高的作业 4. 可以使用在生产环境
配置状态后端(1.12及之前版本)
1)全局配置状态后端:在flink-conf.yaml文件中设置默认的全局后端
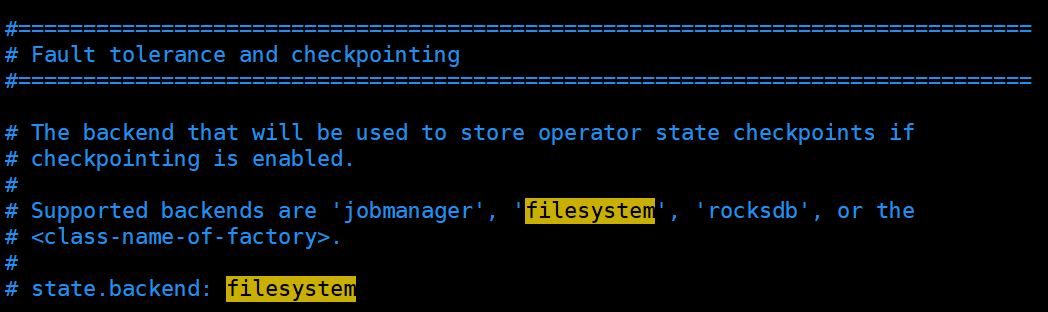
2)在代码中配置状态后端:可以在代码中单独为这个Job设置状态后端
env.setStateBackend(new MemoryStateBackend()); //保存在内存中 env.setStateBackend(new FsStateBackend("hdfs://hadoop162:8020/flink/checkpoints/fs")); //保存在HDFS
env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop162:8020/ck/rocks")); //保存在RocksDB:HDFS中
3)如果要使用RocksDBBackend, 需要先引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.13.1</version>
</dependency>
env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop162:8020/flink/checkpoints/rocksdb"));
Flink提供了2种状态后端(1.13版本):
1)HashMapStateBackend
The HashMapStateBackend holds data internally as objects on the Java heap. Key/value state and window operators hold hash tables that store the values, triggers, etc. The HashMapStateBackend is encouraged for: Jobs with large state, long windows, large key/value states. All high-availability setups. It is also recommended to set managed memory to zero. This will ensure that the maximum amount of memory is allocated for user code on the JVM
2)EmbeddedRocksDBStateBackend
The EmbeddedRocksDBStateBackend holds in-flight data in a RocksDB database that is (per default) stored in the TaskManager local data directories. Unlike storing java objects in HashMapStateBackend, data is stored as serialized byte arrays, which are mainly defined by the type serializer, resulting in key comparisons being byte-wise instead of using Java’s hashCode() and equals() methods. The EmbeddedRocksDBStateBackend always performs asynchronous snapshots. Limitations of the EmbeddedRocksDBStateBackend: As RocksDB’s JNI bridge API is based on byte[], the maximum supported size per key and per value is 2^31 bytes each. States that use merge operations in RocksDB (e.g. ListState) can silently accumulate value sizes > 2^31 bytes and will then fail on their next retrieval. This is currently a limitation of RocksDB JNI. The EmbeddedRocksDBStateBackend is encouraged for: Jobs with very large state, long windows, large key/value states. All high-availability setups. Note that the amount of state that you can keep is only limited by the amount of disk space available. This allows keeping very large state, compared to the HashMapStateBackend that keeps state in memory. This also means, however, that the maximum throughput that can be achieved will be lower with this state backend. All reads/writes from/to this backend have to go through de-/serialization to retrieve/store the state objects, which is also more expensive than always working with the on-heap representation as the heap-based backends are doing. Check also recommendations about the task executor memory configuration for the EmbeddedRocksDBStateBackend. EmbeddedRocksDBStateBackend is currently the only backend that offers incremental checkpoints (see here). Certain RocksDB native metrics are available but disabled by default, you can find full documentation here The total memory amount of RocksDB instance(s) per slot can also be bounded, please refer to documentation here for details.
配置状态后端(1.13版本)
1)全局配置状态后端:在flink-conf.yaml文件中设置默认的全局后端
# The backend that will be used to store operator state checkpoints state.backend: hashmap # Directory for storing checkpoints state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
2)在代码中配置状态后端:可以在代码中单独为这个Job设置状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new HashMapStateBackend()); //保存在本地 env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage()); //保存在远程端,JobManager内存中
env.setStateBackend(new HashMapStateBackend()); //保存在本地 env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop162:8020/ck"); //保存在HDFS中
env.setStateBackend(new EmbeddedRocksDBStateBackend()); //保存在RocksDB
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop162:8020/ck/rocks"); //保存在HDFS
3)如果要使用EmbeddedRocksDBStateBackend, 需要先引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.13.1</version>
</dependency>
7.9 Flink的容错机制
7.9.1 状态的一致性
当在分布式系统中引入状态时,自然也引入了一致性问题。
一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?
一致性级别,在流处理中,一致性可以分为3个级别:
1)at-most-once(最多一次):这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。
2)at-least-once(至少一次):这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
3)exactly-once(严格一次):这指的是系统保证在发生故障后得到的计数结果与正确值一致,既不多算也不少算
曾经,at-least-once非常流行。第一代流处理器(如Storm和Samza)刚问世时只保证at-least-once,原因有二:
1)保证exactly-once的系统实现起来更复杂。这在基础架构层(决定什么代表正确,以及exactly-once的范围是什么)和实现层都很有挑战性
2)流处理系统的早期用户愿意接受框架的局限性,并在应用层想办法弥补(例如使应用程序具有幂等性,或者用批量计算层再做一遍计算)。
最先保证exactly-once的系统(Storm Trident和Spark Streaming)在性能和表现力这两个方面付出了很大的代价。为了保证exactly-once,这些系统无法单独地对每条记录运用应用逻辑,而是同时处理多条(一批)记录,保证对每一批的处理要么全部成功,要么全部失败。这就导致在得到结果前,必须等待一批记录处理结束。因此,用户经常不得不使用两个流处理框架(一个用来保证exactly-once,另一个用来对每个元素做低延迟处理),结果使基础设施更加复杂。曾经,用户不得不在保证exactly-once与获得低延迟和效率之间权衡利弊。Flink避免了这种权衡。
Flink的一个重大价值在于,它既保证了exactly-once,又具有低延迟和高吞吐的处理能力。从根本上说,Flink通过使自身满足所有需求来避免权衡,它是业界的一次意义重大的技术飞跃。尽管这在外行看来很神奇,但是一旦了解,就会恍然大悟。
端到端的状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。
具体划分如下:
1)source端:需要外部源可重设数据的读取位置,目前我们使用的Kafka Source具有这种特性:读取数据的时候可以指定offset
2)flink内部:依赖checkpoint机制
3)sink端:需要保证从故障恢复时,数据不会重复写入外部系统. 有2种实现形式
a) 幂等(Idempotent)写入:所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
b) 事务性(Transactional)写入:需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
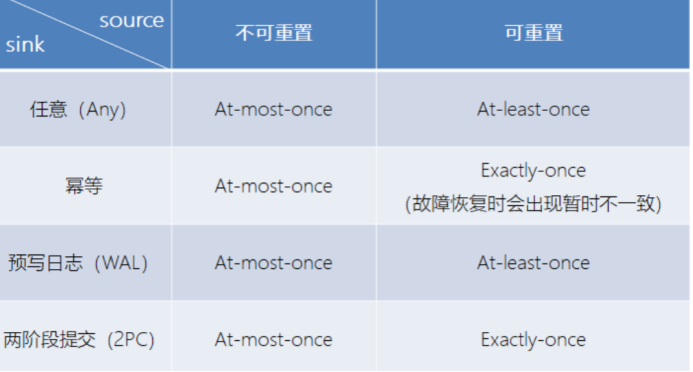
7.9.2 Checkpoint原理
Flink具体如何保证exactly-once呢? 它使用一种被称为"检查点"(checkpoint)的特性,在出现故障时将系统重置回正确状态。下面通过简单的类比来解释检查点的作用。
假设你和两位朋友正在数项链上有多少颗珠子,如下图所示。你捏住珠子,边数边拨,每拨过一颗珠子就给总数加一。你的朋友也这样数他们手中的珠子。当你分神忘记数到哪里时,怎么办呢? 如果项链上有很多珠子,你显然不想从头再数一遍,尤其是当三人的速度不一样却又试图合作的时候,更是如此(比如想记录前一分钟三人一共数了多少颗珠子,回想一下一分钟滚动窗口)。

于是,你想了一个更好的办法:在项链上每隔一段就松松地系上一根有色皮筋,将珠子分隔开; 当珠子被拨动的时候,皮筋也可以被拨动; 然后,你安排一个助手,让他在你和朋友拨到皮筋时记录总数。用这种方法,当有人数错时,就不必从头开始数。相反,你向其他人发出错误警示,然后你们都从上一根皮筋处开始重数,助手则会告诉每个人重数时的起始数值,例如在粉色皮筋处的数值是多少。
Flink检查点的作用就类似于皮筋标记。数珠子这个类比的关键点是: 对于指定的皮筋而言,珠子的相对位置是确定的; 这让皮筋成为重新计数的参考点。总状态(珠子的总数)在每颗珠子被拨动之后更新一次,助手则会保存与每根皮筋对应的检查点状态,如当遇到粉色皮筋时一共数了多少珠子,当遇到橙色皮筋时又是多少。当问题出现时,这种方法使得重新计数变得简单。
Flink的检查点算法
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性
快照的实现算法:
a) 简单算法--暂停应用, 然后开始做检查点, 再重新恢复应用
b) Flink的改进Checkpoint算法,Flink的checkpoint机制原理来自"Chandy-Lamport algorithm"算法(分布式快照算)的一种变体: 异步 barrier 快照(asynchronous barrier snapshotting),每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
理解Barrier(障碍)
流的barrier是Flink的Checkpoint中的一个核心概念,多个barrier被插入到数据流中, 然后作为数据流的一部分随着数据流动(有点类似于Watermark),这些barrier不会跨越流中的数据,每个barrier会把数据流分成两部分:一部分数据进入当前的快照 , 另一部分数据进入下一个快照 . 每个barrier携带着快照的id,barrier 不会暂停数据的流动, 所以非常轻量级。在流中, 同一时间可以有来源于多个不同快照的多个barrier, 这个意味着可以并发的出现不同的快照
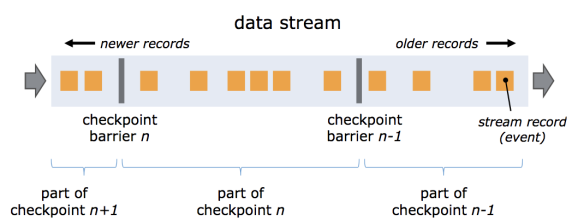
Flink的检查点制作过程
第一步: Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint,然后Source Task会在数据流中安插CheckPoint barrier
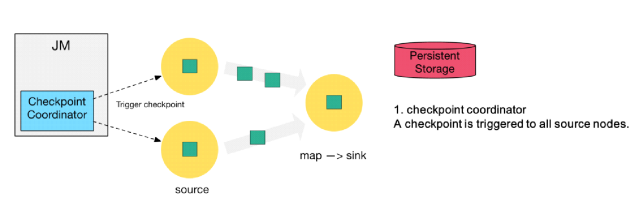
第二步: source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有进来的 barrier 才会执行相应的 Checkpoint(barrier对齐, 但是新版本有一种新的: barrier)
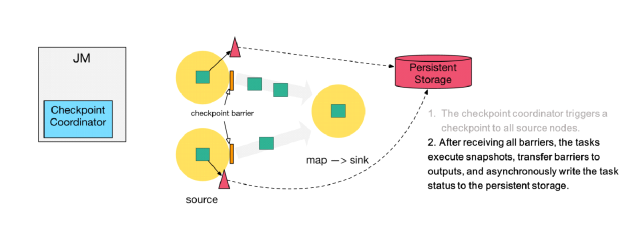
第三步: 当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
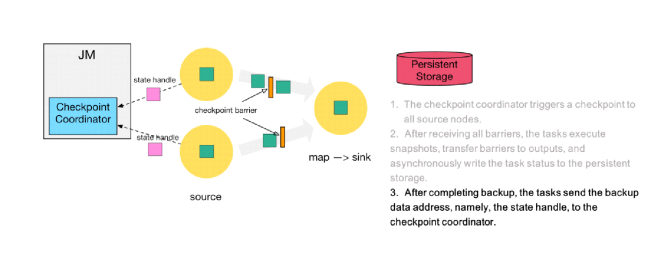
第四步: 下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
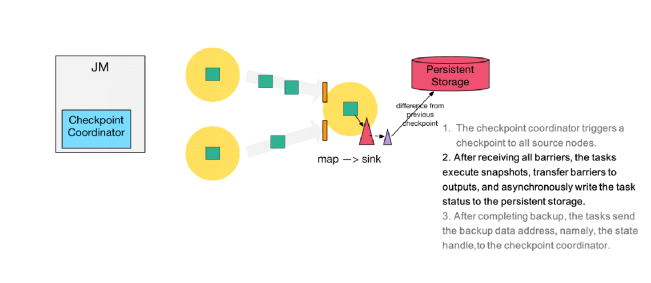
第五步: 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。

第六步: 最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
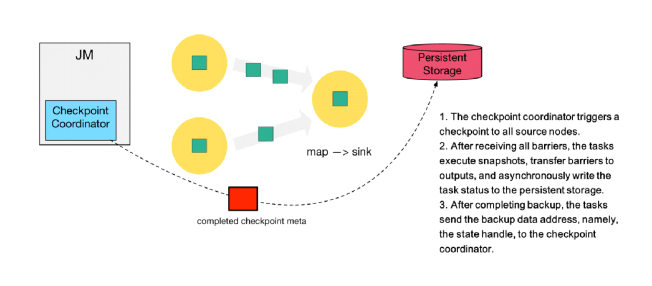
严格一次语义: barrier对齐
在多并行度下, 如果要实现严格一次, 则要执行barrier对齐,当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment),以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
https://ci.apache.org/projects/flink/flink-docs-release-1.12/fig/stream_aligning.svg
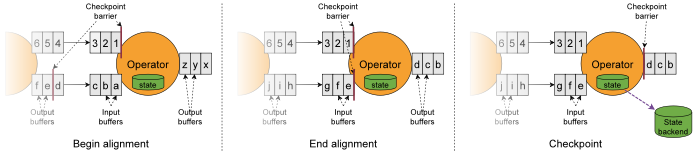 1)当operator收到数字流的barrier n时, 它就不能处理(但是可以接收)来自该流的任何数据记录,直到它从字母流所有输入接收到 barrier n 为止。否则,它会混合属于快照 n 的记录和属于快照 n + 1 的记录。
1)当operator收到数字流的barrier n时, 它就不能处理(但是可以接收)来自该流的任何数据记录,直到它从字母流所有输入接收到 barrier n 为止。否则,它会混合属于快照 n 的记录和属于快照 n + 1 的记录。
2)接收到 barrier n 的流(数字流)暂时被搁置。从这些流接收的记录入输入缓冲区, 不会被处理。
3)图一中的 Checkpoint barrier n之后的数据 123已结到达了算子, 存入到输入缓冲区没有被处理, 只有等到字母流的Checkpoint barrier n到达之后才会开始处理.
4)一旦最后所有输入流都接收到 barrier n,Operator 就会把缓冲区中 pending 的输出数据发出去,然后把 CheckPoint barrier n 接着往下游发送。这里还会对自身进行快照。
至少一次语义: barrier不对齐
前面介绍了barrier对齐, 如果barrier不对齐会怎么样? 会重复消费, 就是至少一次语义.
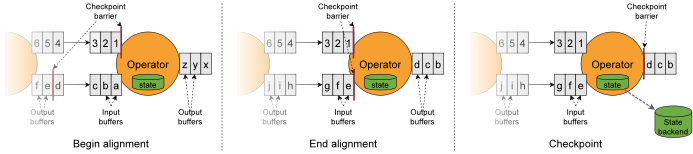
假设不对齐, 在字母流的Checkpoint barrier n到达前, 已经处理了1 2 3. 等字母流Checkpoint barrier n到达之后, 会做Checkpoint n. 假设这个时候程序异常错误了, 则重新启动的时候会Checkpoint n之后的数据重新计算. 1 2 3 会被再次被计算, 所以123出现了重复计算.
7.9.3 Savepoint原理
1)Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
2)原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点
3)Flink不会自动创建保存点,因此用户(或外部调度程序)必须明确地触发创建操作
4)保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等
7.9.4 checkpoint和savepoint的区别
|
Savepoint |
Checkpoint |
|
Savepoint是由命令触发, 由用户创建和删除 |
Checkpoint被保存在用户指定的外部路径中, flink自动触发 |
|
保存点存储在标准格式存储中,并且可以升级作业版本并可以更改其配置。 |
当作业失败或被取消时,将保留外部存储的检查点。 |
|
用户必须提供用于还原作业状态的保存点的路径。 |
用户必须提供用于还原作业状态的检查点的路径。 如果是flink的自动重启, 则flink会自动找到最后一个完整的状态 |
7.9.5 Kafka+Flink+Kafka 实现端到端严格一次
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?
1)内部 —— 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证部的状态一致性
2)source —— kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
3)sink —— kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的checkpoint机制我们已经有了了解,那source和sink具体又是怎样运行的呢?接下来我们逐步做一个分析。
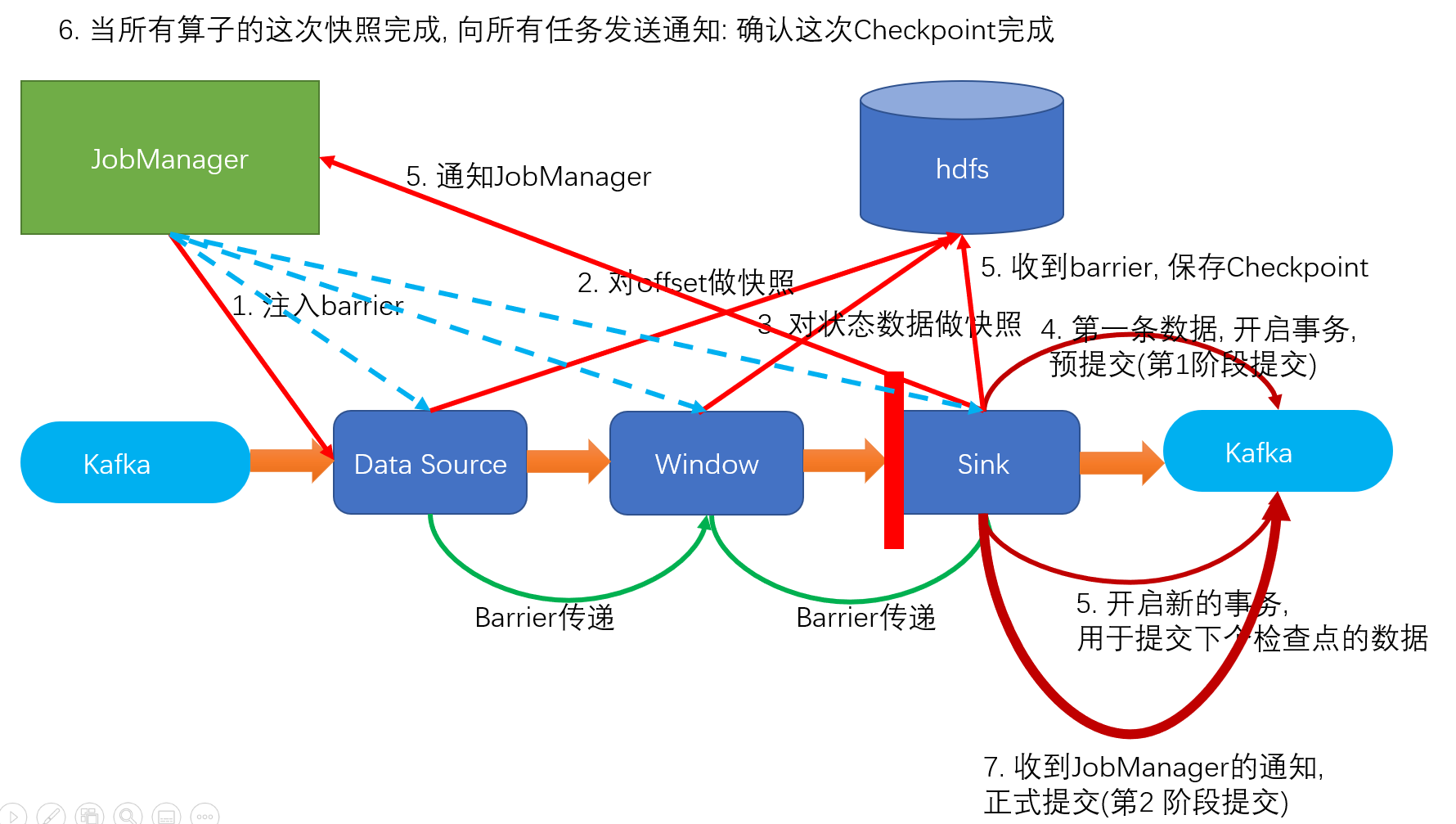
具体的两阶段提交步骤总结如下:
1)某个checkpoint的第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”(第一阶段提交)
2)jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子状态后端会进行相应进行checkpoint,并通知 jobmanagerr
3)sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
4)jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
5)sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据(第二阶段提交)
6)外部kafka关闭事务,提交的数据可以正常消费了
7.9.6 在代码中测试Checkpoint
package com.yuange.flink.day06; import com.yuange.flink.day02.WaterSensor; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema; import org.apache.flink.util.Collector; import org.apache.kafka.clients.producer.ProducerRecord; import javax.annotation.Nullable; import java.nio.charset.StandardCharsets; import java.util.Properties; /** * @Author lizhenchao@atguigu.cn * @Date 2021/7/21 11:19 */ public class Flink_Checkpoint { public static void main(String[] args) throws Exception { Properties sourceProps = new Properties(); sourceProps.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); sourceProps.setProperty("group.id", "Flink_Source_Kafka"); sourceProps.setProperty("auto.offset.reset", "latest");
sourceProps.setProperty("isolation.level","read_committed"); //设置数据的隔离级别,保证数据只能消费提交的数据 Properties sinkProps = new Properties(); sinkProps.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); sinkProps.setProperty("transaction.timeout.ms", 14 * 60 * 1000 + ""); StreamExecutionEnvironment env = StreamExecutionEnvironment .createLocalEnvironmentWithWebUI(new Configuration()) .setParallelism(3); env.setStateBackend(new FsStateBackend("hdfs://hadoop162:8020/flink/checkpoints/fs")); // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(3000); // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 开启在 job 中止后仍然保留的 externalized checkpoints env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env .addSource(new FlinkKafkaConsumer<>("s1", new SimpleStringSchema(), sourceProps)) .map(value -> { String[] datas = value.split(","); return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2])); }) .keyBy(WaterSensor::getId) .process(new KeyedProcessFunction<String, WaterSensor, String>() { private ValueState<Integer> state; @Override public void open(Configuration parameters) throws Exception { state = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("state", Integer.class)); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { Integer lastVc = state.value() == null ? 0 : state.value(); if (Math.abs(value.getVc() - lastVc) >= 10) { out.collect(value.getId() + " 红色警报!!!"); throw new RuntimeException("自己抛的"); } state.update(value.getVc()); } }) .addSink(new FlinkKafkaProducer<String>( "default", new KafkaSerializationSchema<String>() { @Override public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) { return new ProducerRecord<>("s2", element.getBytes(StandardCharsets.UTF_8)); } }, sinkProps, FlinkKafkaProducer.Semantic.EXACTLY_ONCE )); env.execute(); } }
1)启动hadoop
hadoop.sh start
2)启动Zookeeper
zk start
3)启动Kafka
kafka.sh start
4)测试
#启动生产者
producer s2
#启动消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop162:9092 --topic s2 --isolation-level read_committed
5)从checkpoint恢复数据
(1)代码准备
package com.yuange.flink.day06; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema; import org.apache.flink.util.Collector; import org.apache.kafka.clients.producer.ProducerRecord; import javax.annotation.Nullable; import java.nio.charset.StandardCharsets; import java.util.Properties; public class Flink_Checkpoint_Two { public static void main(String[] args) throws Exception { System.setProperty("HADOOP_USER_NAME", "atguigu"); Properties sourceProps = new Properties(); sourceProps.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); sourceProps.setProperty("group.id", "Flink_Checkpoint_Two"); sourceProps.setProperty("auto.offset.reset", "latest");
sourceProps.setProperty("isolation.level","read_committed"); //设置数据的隔离级别,保证不能消费Kafka中未提交的数据 Properties sinkProps = new Properties(); sinkProps.setProperty("bootstrap.servers", "hadoop162:9092,hadoop163:9092,hadoop164:9092"); sinkProps.setProperty("transaction.timeout.ms", 14 * 60 * 1000 + ""); StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment() .setParallelism(3); env.setStateBackend(new FsStateBackend("hdfs://hadoop162:8020/flink/checkpoints/fs")); // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(3000); // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 开启在 job 中止后仍然保留的 externalized checkpoints env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env .addSource(new FlinkKafkaConsumer<>("s1", new SimpleStringSchema(), sourceProps)) .flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { for (String word : value.split(" ")) { out.collect(Tuple2.of(word, 1L)); } } }) .keyBy(t -> t.f0) .sum(1) .map(t -> t.f0 + "_" + t.f1) .addSink(new FlinkKafkaProducer<String>( "default", new KafkaSerializationSchema<String>() { @Override public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) { return new ProducerRecord<>("s2", element.getBytes(StandardCharsets.UTF_8)); } }, sinkProps, FlinkKafkaProducer.Semantic.EXACTLY_ONCE )); env.execute(); } }
(2)打包上传至 /opt/module/flink-yarn
(3)启动Flink-Session
/opt/module/flink-yarn/bin/yarn-session.sh -d
(4)运行Jar包
/opt/module/flink-yarn/bin/flink run -d -c com.yuange.flink.day06.Flink_Checkpoint_Two /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
(5)启动生产者
producer s1
(6)启动消费者
consume s2
(7)生产数据测试,先输入5个a,然后进入http://hadoop163:8088/cluster 将任务 kill 掉,以模拟程序异常停止

(8)然后继续在生产者端生产两个a
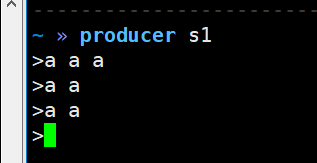
(9)紧接着去HDFS上找到最后备份的那条数据,将路径复制下来

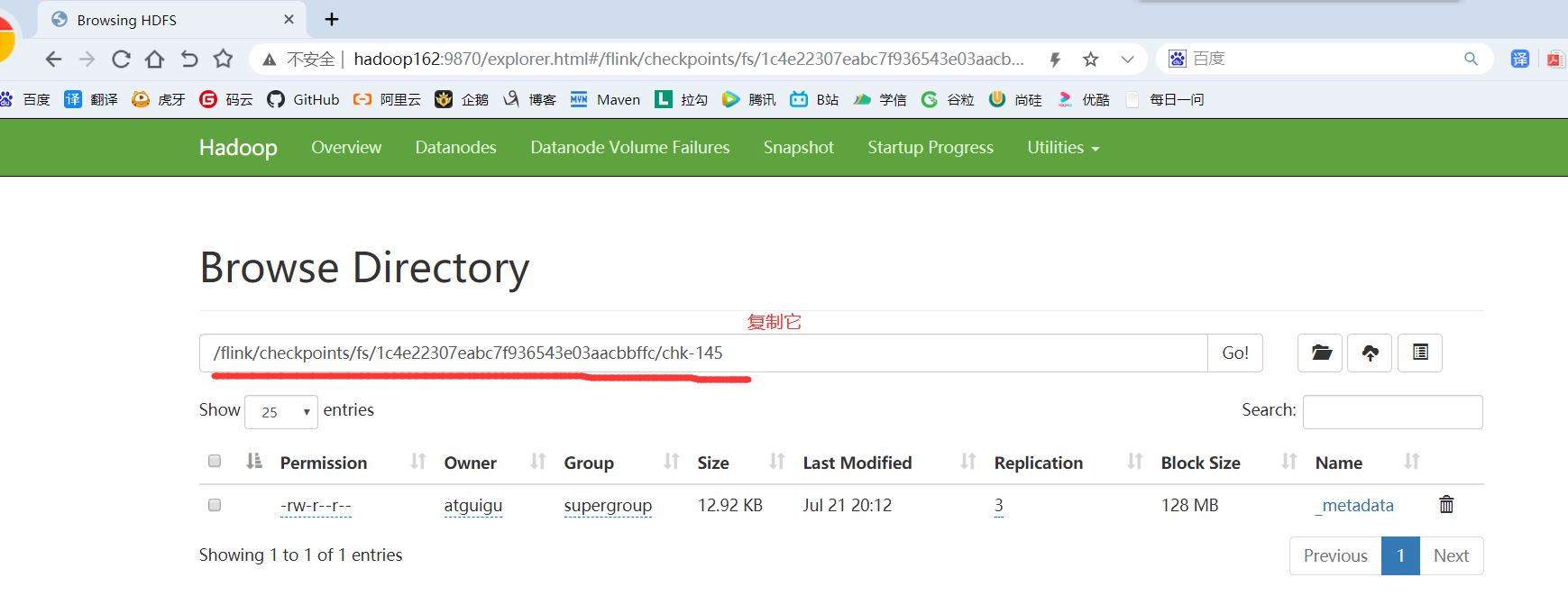
(10)重启程序以恢复数据
/opt/module/flink-yarn/bin/flink run -s hdfs://hadoop162:8020/flink/checkpoints/fs/1c4e22307eabc7f936543e03aacbbffc/chk-145 -d -c com.yuange.flink.day06.Flink_Checkpoint_Two /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.jar
(11)如果你的Flink-Session也停止了,请再次启动,否则恢复数据时会报错
/opt/module/flink-yarn/bin/yarn-session.sh -d
(12)稍等片刻后,我们发现在程序停止之后我们生产的两个a也被消费到了
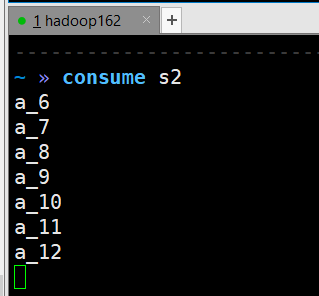 6)手动savepoint
6)手动savepoint
bin/flink savepoint jobid hdfs://hadoop162:8020/XXX
7)从savepoint恢复数据
(1)找到前面运行的JobId:http://hadoop163:8088/
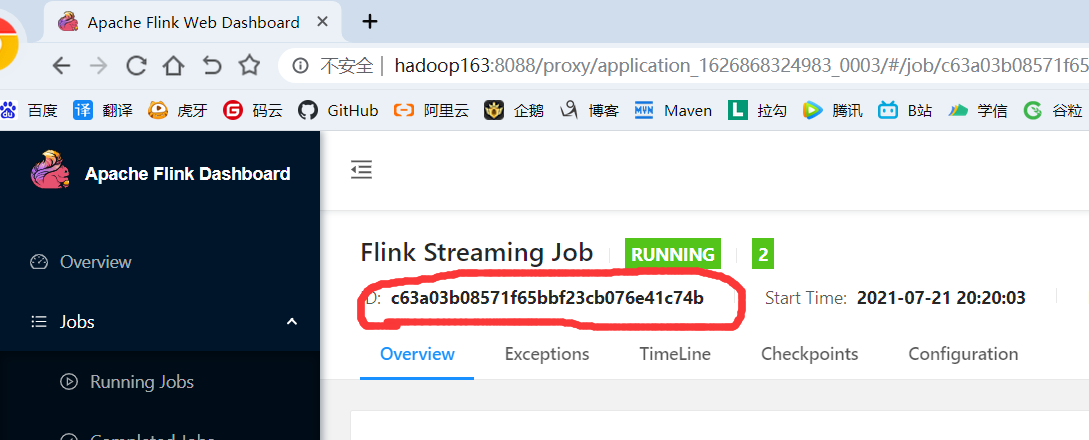
(2)设置savepoint
/opt/module/flink-yarn/bin/flink savepoint c63a03b08571f65bbf23cb076e41c74b hdfs://hadoop162:8020/savepoint-yuange
(3)查看HDFS,发现目录已经创建

(4)我们停止运行的程序
(5)停止之后,我们生产一个a
(6)然后我们使用savepoint恢复数据
/opt/module/flink-yarn/bin/flink run -s hdfs://hadoop162:8020/savepoint-yuange/savepoint-c63a03-72f8f7d02c42 -d -c com.yuange.flink.day06.Flink_Checkpoint_Two /opt/module/flink-yarn/FlinkTest-1.0-SNAPSHOT.ja
(7)骚等片刻后我们发现数据以及恢复:a_13
