一、自定义UDAF思路及步骤
1)打开Hive官网:https://cwiki.apache.org/confluence/display/Hive

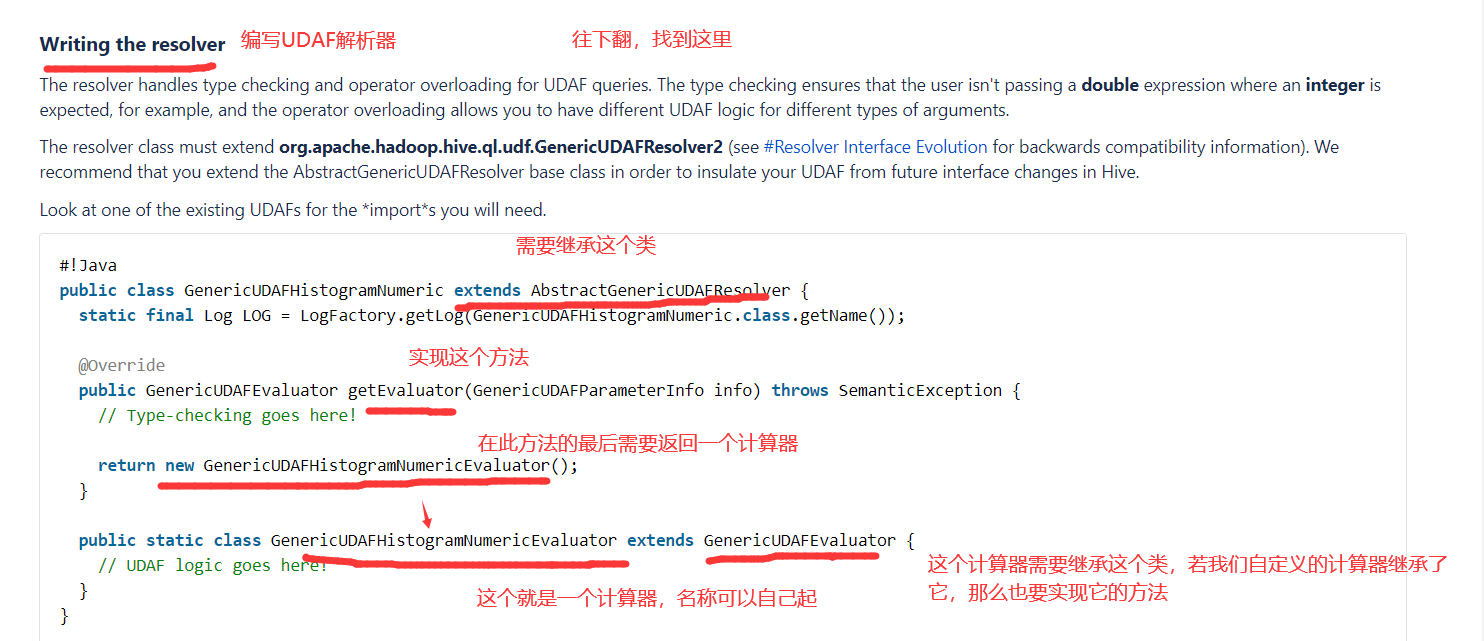
2)打开Idea,新建一个Maven工程,并添加Hive依赖
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> </dependency>
3)在此工程下新建一个MyUDAF.java
package com.yuange.hive; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.parse.SemanticException; import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver; import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator; import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo; /** * @作者:袁哥 * @时间:2021/6/26 18:47 */ public class MyUDAF extends AbstractGenericUDAFResolver { @Override public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException { return new MyUDAFEvaluator(); //返回自定义计算器 } //静态内部类,名称随意取 public static class MyUDAFEvaluator extends GenericUDAFEvaluator { //自定义计算器 public AggregationBuffer getNewAggregationBuffer() throws HiveException { return null; } public void reset(AggregationBuffer agg) throws HiveException { } public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException { } public Object terminatePartial(AggregationBuffer agg) throws HiveException { return null; } public void merge(AggregationBuffer agg, Object partial) throws HiveException { } public Object terminate(AggregationBuffer agg) throws HiveException { return null; } // UDAF logic goes here! } }
4)我们此时继续查看Hive官网


5)回到Idea中
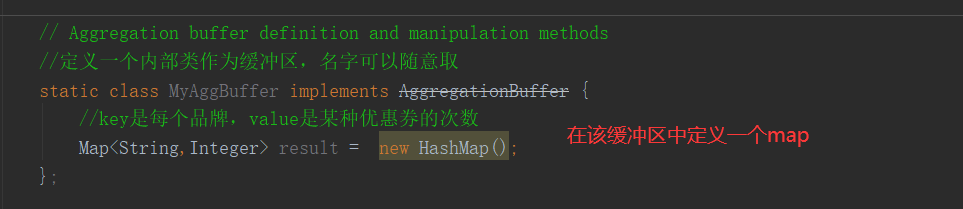


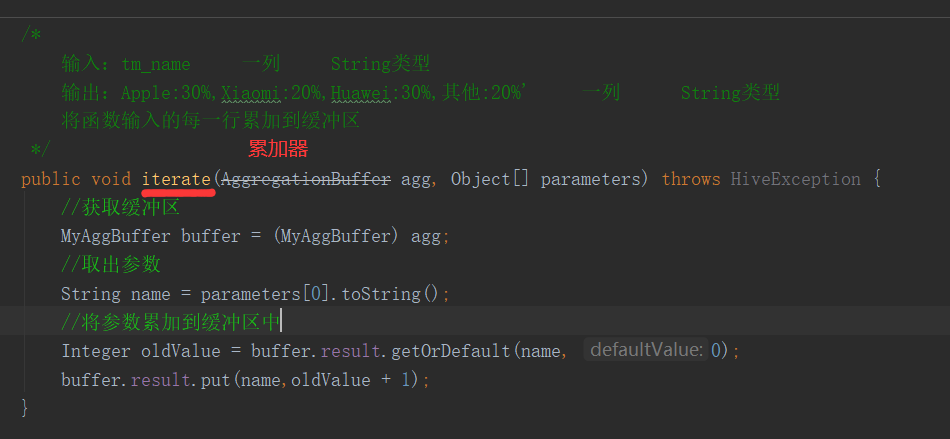
6)紧接着,我们先编写 terminate()方法的具体内容
//返回最终的结果:将Map<品牌,用券次数> 转化为 Apple:30%,Xiaomi:20%,Huawei:30%,其他:20% public Object terminate(AggregationBuffer agg) throws HiveException { //从缓冲区中获取最终的结果集合 Map<String, Integer> finalResult = ((MyAggBuffer) agg).result; //先求出所有品牌的用券次数 double sumTime = 0; for (Integer value : finalResult.values()) { sumTime += value; } //将Map中的key,按照value的大小降序排序,并取前三 ArrayList<Map.Entry<String, Integer>> entries = new ArrayList<>(finalResult.entrySet()); //将map转化为array entries.sort(new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { //默认Integer类的compareTo是升序比较,若要降序排序,则再前面加- return -o1.getValue().compareTo(o2.getValue()); } }); List<Map.Entry<String, Integer>> top3 = entries.subList(0, Math.min(3, entries.size())); //存放前三的数据:List<Map> ArrayList<String> compactStr = new ArrayList<>(); //存放前三的数据:List<String> DecimalFormat decimalFormat = new DecimalFormat("#.##%"); //格式化器 double top3_percent = 0.0; //前三品牌的比例的累加结果,目的是求‘其他’(pple:30%,Xiaomi:20%,Huawei:30%,其他:20%) //遍历 List<Map>,将其转化为 List<String> 类型 for (Map.Entry<String, Integer> entry : top3) { double current_per = entry.getValue() / sumTime; //当前品牌的比例 top3_percent += current_per; //拼接数据为String类型,并放入List集合中 compactStr.add(entry.getKey() + ":" + decimalFormat.format(current_per)); } if (entries.size() > 3){ //若品牌数大于3,会有‘其他’:Apple:30%,Xiaomi:20%,Huawei:30%,其他:20% compactStr.add("其他:" + decimalFormat.format(1 - top3_percent)); } //将每个品牌对应的字符串,组合为最终的结果返回 return StringUtils.join(compactStr,','); }
7)编写完成后测试一下 terminate()方法,运行之后发现出现中文乱码,加个参数就行
public static void main(String[] args) throws HiveException { HashMap<String, Integer> map = new HashMap<>(); map.put("小米",10); map.put("小米1",15); map.put("iphone",2); map.put("huawei",9); map.put("oppo",9); MyUDAFEvaluator.MyAggBuffer myAggBuffer = new MyUDAFEvaluator.MyAggBuffer(); myAggBuffer.result = map; System.out.println(new MyUDAFEvaluator().terminate(myAggBuffer)); }


8)回到Hive官网,查看getEvaluator方法是如何检查参数的
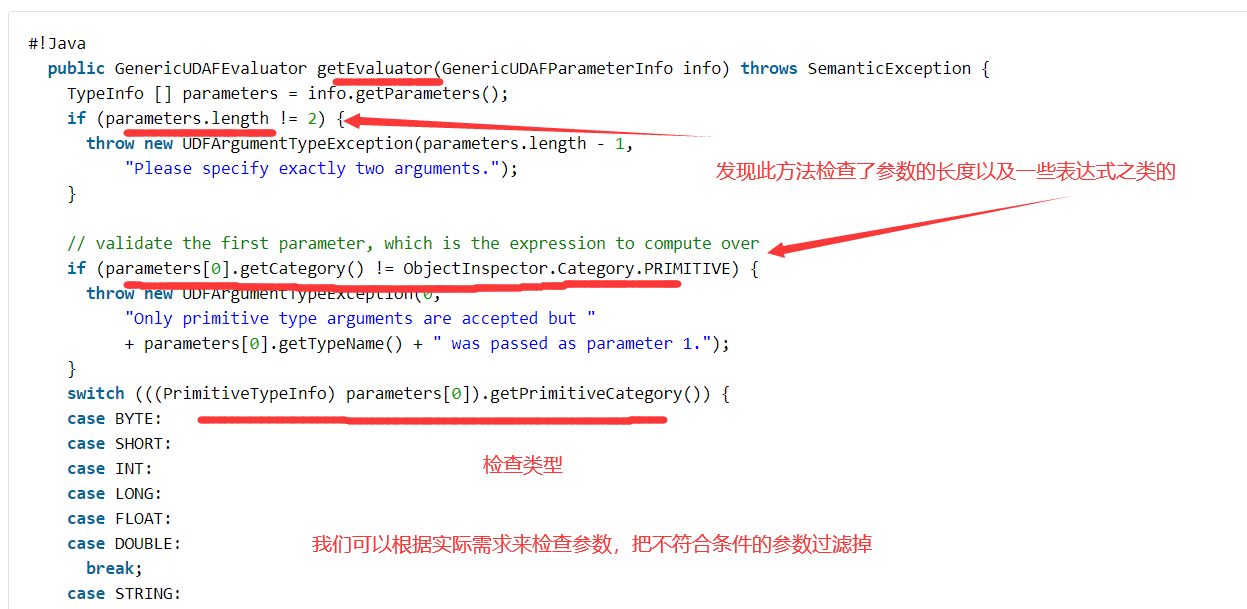
9)回到Idea中,找到 getEvaluator()方法,编写它
@Override public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException { //类型检查器 ObjectInspector[] parameterObjectInspectors = info.getParameterObjectInspectors(); //检查参数个数 if (parameterObjectInspectors.length != 1) { throw new UDFArgumentException("只能传入一个参数!"); } //检查参数类型是否为String if (parameterObjectInspectors[0].getCategory() != ObjectInspector.Category.PRIMITIVE) { throw new UDFArgumentException("传入的参数类型必须是基本数据类型!"); } if( ((PrimitiveObjectInspector) parameterObjectInspectors[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){ throw new UDFArgumentException("传入的参数类型必须是String类型!"); } return new MyUDAFEvaluator(); //返回自定义计算器 }
10)编写完成后,返回Hive官网,找到 terminatePartial() 方法的介绍与说明
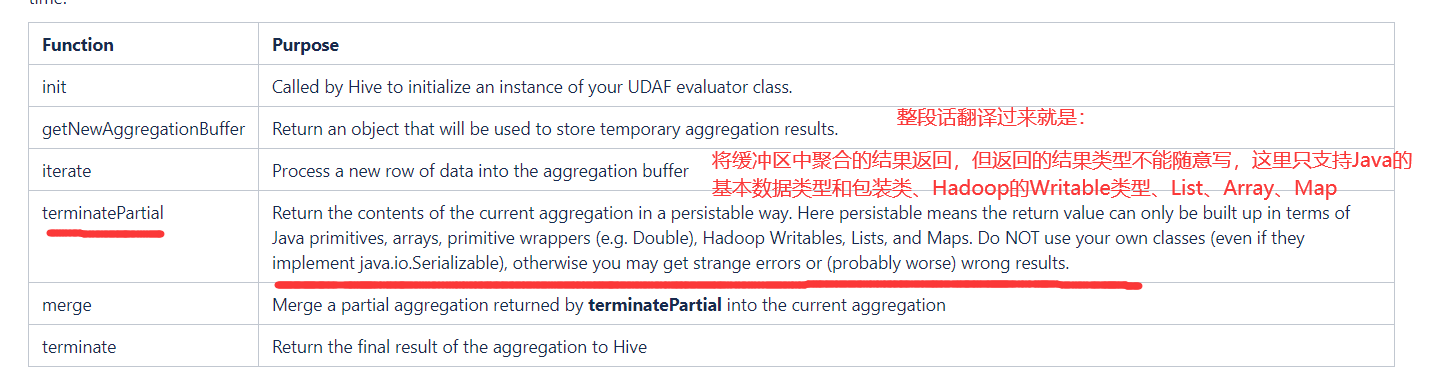
11)返回Idea中,编写 terminatePartial() 方法
public Object terminatePartial(AggregationBuffer agg) throws HiveException { return ((MyAggBuffer)agg).result; //将缓冲区中的Map集合(result)返回 }
12)再查看

13)回到 Idea中,编写 init() 方法,并使用查看源码的方式来确定 init 如何使用
@Override public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException { return super.init(m, parameters); }

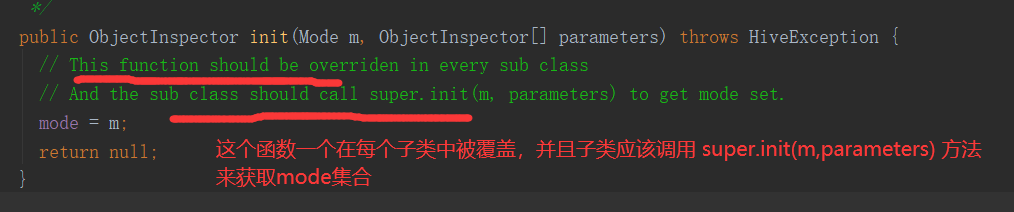


14)了解 init 的使用之后,再次编写它
//声明一个Map类型的对象检查器,以便merge方法使用 private StandardMapObjectInspector mapObjectInspector; @Override public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException { //子类必须调用,才能获取到Mode super.init(m, parameters); //从parameters中获取Map类型的对象检查器 if (m == Mode.FINAL || m == Mode.PARTIAL2){ mapObjectInspector = (StandardMapObjectInspector)parameters[0]; } //声明缓冲区中聚合的数据类型和返回的最终结果的数据类型 if (m == Mode.PARTIAL1 || m == Mode.PARTIAL2){ return ObjectInspectorFactory.getStandardMapObjectInspector( PrimitiveObjectInspectorFactory.javaStringObjectInspector, PrimitiveObjectInspectorFactory.javaIntObjectInspector); }else { return PrimitiveObjectInspectorFactory.javaStringObjectInspector; } }
15)找到 merge() 方法,编写它
//使用meger方法所处阶段的类型检查器,将Object partial 装换为 Map类型,并将其合并到缓冲区 public void merge(AggregationBuffer agg, Object partial) throws HiveException { //获取第一个缓冲区中的Map Map<String, Integer> map1 = ((MyAggBuffer) agg).result; //从Object partial中获取第二个Map Map<?, ?> map2 = mapObjectInspector.getMap(partial); //获取类型检查器(key和value) PrimitiveObjectInspector mapKeyObjectInspector = (PrimitiveObjectInspector) mapObjectInspector.getMapKeyObjectInspector(); PrimitiveObjectInspector mapValueObjectInspector = (PrimitiveObjectInspector) mapObjectInspector.getMapValueObjectInspector(); //遍历Map2,将map2合并到map1中 for (Map.Entry<?, ?> entry : map2.entrySet()) { //取出entry中的key和value String key = PrimitiveObjectInspectorUtils.getString(entry.getKey(), mapKeyObjectInspector); int value = PrimitiveObjectInspectorUtils.getInt(entry.getValue, mapValueObjectInspector); map1.put(key,map1.getOrDefault(key,0) + value); } }
二、打包
1)完整代码如下
package com.yuange.hive; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.parse.SemanticException; import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver; import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator; import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.StandardMapObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils; import java.text.DecimalFormat; import java.util.*; /** * @作者:袁哥 * @时间:2021/6/26 18:47 */ public class MyUDAF extends AbstractGenericUDAFResolver { @Override public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException { //类型检查器 ObjectInspector[] parameterObjectInspectors = info.getParameterObjectInspectors(); //检查参数个数 if (parameterObjectInspectors.length != 1) { throw new UDFArgumentException("只能传入一个参数!"); } //检查参数类型是否为String if (parameterObjectInspectors[0].getCategory() != ObjectInspector.Category.PRIMITIVE) { throw new UDFArgumentException("传入的参数类型必须是基本数据类型!"); } if( ((PrimitiveObjectInspector) parameterObjectInspectors[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){ throw new UDFArgumentException("传入的参数类型必须是String类型!"); } return new MyUDAFEvaluator(); //返回自定义计算器 } //静态内部类,名称随意取 public static class MyUDAFEvaluator extends GenericUDAFEvaluator { //自定义计算器 //声明一个Map类型的对象检查器,以便merge方法使用 private StandardMapObjectInspector mapObjectInspector; @Override public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException { //子类必须调用,才能获取到Mode super.init(m, parameters); //从parameters中获取Map类型的对象检查器 if (m == Mode.FINAL || m == Mode.PARTIAL2){ mapObjectInspector = (StandardMapObjectInspector)parameters[0]; } //声明缓冲区中聚合的数据类型和返回的最终结果的数据类型 if (m == Mode.PARTIAL1 || m == Mode.PARTIAL2){ return ObjectInspectorFactory.getStandardMapObjectInspector( PrimitiveObjectInspectorFactory.javaStringObjectInspector, PrimitiveObjectInspectorFactory.javaIntObjectInspector); }else { return PrimitiveObjectInspectorFactory.javaStringObjectInspector; } } public AggregationBuffer getNewAggregationBuffer() throws HiveException { return new MyAggBuffer(); //初始化缓冲区 } //清空缓冲区的数据 public void reset(AggregationBuffer agg) throws HiveException { ((MyAggBuffer) agg).result.clear(); } /* 输入:tm_name 一列 String类型 输出:Apple:30%,Xiaomi:20%,Huawei:30%,其他:20% 一列 String类型 将函数输入的每一行累加到缓冲区 */ public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException { //获取缓冲区 MyAggBuffer buffer = (MyAggBuffer) agg; //取出参数 String name = parameters[0].toString(); //将参数累加到缓冲区中 Integer oldValue = buffer.result.getOrDefault(name, 0); buffer.result.put(name,oldValue + 1); } public Object terminatePartial(AggregationBuffer agg) throws HiveException { return ((MyAggBuffer)agg).result; //将缓冲区中的Map集合(result)返回 } //使用meger方法所处阶段的类型检查器,将Object partial 装换为 Map类型,并将其合并到缓冲区 public void merge(AggregationBuffer agg, Object partial) throws HiveException { //获取第一个缓冲区中的Map Map<String, Integer> map1 = ((MyAggBuffer) agg).result; //从Object partial中获取第二个Map Map<?, ?> map2 = mapObjectInspector.getMap(partial); //获取类型检查器(key和value) PrimitiveObjectInspector mapKeyObjectInspector = (PrimitiveObjectInspector) mapObjectInspector.getMapKeyObjectInspector(); PrimitiveObjectInspector mapValueObjectInspector = (PrimitiveObjectInspector) mapObjectInspector.getMapValueObjectInspector(); //遍历Map2,将map2合并到map1中 for (Map.Entry<?, ?> entry : map2.entrySet()) { //取出entry中的key和value String key = PrimitiveObjectInspectorUtils.getString(entry.getKey(), mapKeyObjectInspector); int value = PrimitiveObjectInspectorUtils.getInt(entry.getValue(), mapValueObjectInspector); map1.put(key,map1.getOrDefault(key,0) + value); } } //返回最终的结果:将Map<品牌,用券次数> 转化为 Apple:30%,Xiaomi:20%,Huawei:30%,其他:20% public Object terminate(AggregationBuffer agg) throws HiveException { //从缓冲区中获取最终的结果集合 Map<String, Integer> finalResult = ((MyAggBuffer) agg).result; //先求出所有品牌的用券次数 double sumTime = 0; for (Integer value : finalResult.values()) { sumTime += value; } //将Map中的key,按照value的大小降序排序,并取前三 ArrayList<Map.Entry<String, Integer>> entries = new ArrayList<>(finalResult.entrySet()); //将map转化为array entries.sort(new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { //默认Integer类的compareTo是升序比较,若要降序排序,则再前面加- return -o1.getValue().compareTo(o2.getValue()); } }); List<Map.Entry<String, Integer>> top3 = entries.subList(0, Math.min(3, entries.size())); //存放前三的数据:List<Map> ArrayList<String> compactStr = new ArrayList<>(); //存放前三的数据:List<String> DecimalFormat decimalFormat = new DecimalFormat("#.##%"); //格式化器 double top3_percent = 0.0; //前三品牌的比例的累加结果,目的是求‘其他’(pple:30%,Xiaomi:20%,Huawei:30%,其他:20%) //遍历 List<Map>,将其转化为 List<String> 类型 for (Map.Entry<String, Integer> entry : top3) { double current_per = entry.getValue() / sumTime; //当前品牌的比例 top3_percent += current_per; //拼接数据为String类型,并放入List集合中 compactStr.add(entry.getKey() + ":" + decimalFormat.format(current_per)); } if (entries.size() > 3){ //若品牌数大于3,会有‘其他’:Apple:30%,Xiaomi:20%,Huawei:30%,其他:20% compactStr.add("其他:" + decimalFormat.format(1 - top3_percent)); } //将每个品牌对应的字符串,组合为最终的结果返回 return StringUtils.join(compactStr,','); } // UDAF logic goes here! // Aggregation buffer definition and manipulation methods //定义一个内部类作为缓冲区,名字可以随意取 static class MyAggBuffer implements AggregationBuffer { //key是每个品牌,value是某种优惠券的次数 Map<String,Integer> result = new HashMap(); }; } public static void main(String[] args) throws HiveException { HashMap<String, Integer> map = new HashMap<>(); map.put("小米",10); map.put("小米1",15); // map.put("iphone",2); // map.put("huawei",9); // map.put("oppo",9); MyUDAFEvaluator.MyAggBuffer myAggBuffer = new MyUDAFEvaluator.MyAggBuffer(); myAggBuffer.result = map; System.out.println(new MyUDAFEvaluator().terminate(myAggBuffer)); } }
2)使用Maven工具打包

3)将jar上传至 /opt/module/hive/auxlib 目录(之前我自定义UDTF函数时创建的目录)
4)重启hive
5)创建永久函数与开发好的 java class关联
CREATE function top3 as 'com.yuange.hive.MyUDAF';
6)查看该函数
desc function top3;
7)测试数据,将其上传至hdfs中
1 华为Mate50 华为 coupon1 2 华为Mate50 华为 coupon2 3 华为Mate50 华为 coupon1 4 华为Mate50 华为 coupon2 5 华为Mate50 华为 coupon3 6 ZTE60 ZTE coupon1 7 ZTE60 ZTE coupon2 8 ZTE60 ZTE coupon1 9 ZTE60 ZTE coupon2 10 ZTE60 ZTE coupon3 11 MI100 MI coupon3 12 MI100 MI coupon3 13 IPHONE13 苹果 coupon3 14 IPHONE13 苹果 coupon1 15 IPHONE13 苹果 coupon2 16 IPHONE13 苹果 coupon1 17 IPHONE13 苹果 coupon2 18 OPPOFind100 OPPO coupon2 19 OPPOFind100 OPPO coupon1 20 OPPOFind100 OPPO coupon2 21 VIVO30 VIVO coupon3 22 VIVO30 VIVO coupon1 23 VIVO30 VIVO coupon2
8)创建 mytest 测试表
create table mytest( `id` string comment 'id', `spu_name` string comment 'spuName', `tm_name` string comment '品牌名称', `coupon_name` string comment '优惠券名称' ) comment 'UDAF测试表' row format delimited fields terminated by '\t' location '/tmp/testUDAF/';
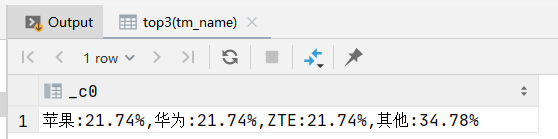
9)测试
select top3(tm_name) from mytest;