整理复习汇编语言的知识点,以前在学习《Intel汇编语言程序设计 - 第五版》时没有很认真的整理笔记,主要因为当时是以学习理解为目的没有整理的很详细,这次是我第三次阅读此书,每一次阅读都会有新的收获,这次复习,我想把书中的重点,再一次做一个归纳与总结(注:16位汇编部分跳过),并且继续尝试写一些有趣的案例,这些案例中所涉及的指令都是逆向中的重点,一些不重要的我就直接省略了,一来提高自己,二来分享知识,转载请加出处,敲代码备注挺难受的。
该笔记重点复习字符串操作指令的一些使用技巧,以及浮点数运算相关内容,浮点数运算也是非常重要的知识点,在分析大型游戏时经常会碰到针对浮点数的运算指令,例如枪械换弹动作,人物跳跃时的状态,都属于浮点数运算范围,也就一定会用到浮点数寄存器栈,浮点指令集主要可分为,传送指令,算数指令,比较指令,超越指令,常量加载指令等。
再次强调:该笔记主要学习的是汇编语言,不是研究编译特性的,不会涉及到编译器的优化与代码还原。
字符串操作指令
移动串指令: MOVSB、MOVSW、MOVSD ;从 ESI -> EDI; 执行后, ESI 与 EDI 的地址移动相应的单位
比较串指令: CMPSB、CMPSW、CMPSD ;比较 ESI、EDI; 执行后, ESI 与 EDI 的地址移动相应的单位
扫描串指令: SCASB、SCASW、SCASD ;依据 AL/AX/EAX 中的数据扫描 EDI 指向的数据, 执行后 EDI 自动变化
储存串指令: STOSB、STOSW、STOSD ;将 AL/AX/EAX 中的数据储存到 EDI 给出的地址, 执行后 EDI 自动变化
载入串指令: LODSB、LODSW、LODSD ;将 ESI 指向的数据载入到 AL/AX/EAX, 执行后 ESI 自动变化
移动串指令: 移动串指令包括MOVSB、MOVSW、MOVSD原理为从ESI到EDI中,执行后将ESI地址里面的内容移动到EDI指向的内存空间中,该指令常用于对特定字符串的复制操作.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
; 逐字节拷贝
SrcString BYTE "hello lyshark",0h ; 源字符串
SrcStringLen EQU $ - SrcString - 1 ; 计算出原始字符串长度
DstString BYTE SrcStringLen dup(?),0h ; 目标内存地址
szFmt BYTE '字符串: %s 长度: %d ',0dh,0ah,0
; 四字节拷贝
ddSource DWORD 10h,20h,30h ; 定义三个四字节数据
ddDest DWORD lengthof ddSource dup(?) ; 得到目标地址
.code
main PROC
; 第一种情况: 实现逐字节拷贝
cld ; 清除方向标志
mov esi,offset SrcString ; 取源字符串内存地址
mov edi,offset DstString ; 取目标字符串内存地址
mov ecx,SrcStringLen ; 指定循环次数,为原字符串长度
rep movsb ; 逐字节复制,直到ecx=0为止
lea eax,dword ptr ds:[DstString]
mov ebx,sizeof DstString
invoke crt_printf,addr szFmt,eax,ebx
; 第二种情况: 实现4字节拷贝
lea esi,dword ptr ds:[ddSource]
lea edi,dword ptr ds:[ddDest]
cld
rep movsd
; 使用loop循环逐字节复制
lea esi,dword ptr ds:[SrcString]
lea edi,dword ptr ds:[DstString]
mov ecx,SrcStringLen
cld ; 设置方向为正向复制
@@: movsb ; 每次复制一个字节
dec ecx ; 循环递减
jnz @B ; 如果ecx不为0则循环
lea eax,dword ptr ds:[DstString]
mov ebx,sizeof DstString
invoke crt_printf,addr szFmt,eax,ebx
invoke ExitProcess,0
main ENDP
END main
比较串指令: 比较串指令包括CMPSB、CMPSW、CMPSD比较ESI、EDI执行后将ESI指向的内存操作数同EDI指向的内存操作数相比较,其主要从ESI指向内容减去EDI的内容来影响标志位.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
; 逐字节比较
SrcString BYTE "hello lyshark",0h
DstStringA BYTE "hello world",0h
.const
szFmt BYTE '字符串: %s',0dh,0ah,0
YES BYTE "相等",0
NO BYTE "不相等",0
.code
main PROC
; 实现字符串对比,相等/不相等输出
lea esi,dword ptr ds:[SrcString]
lea edi,dword ptr ds:[DstStringA]
mov ecx,lengthof SrcString
cld
repe cmpsb
je L1
jmp L2
L1: lea eax,YES
invoke crt_printf,addr szFmt,eax
jmp lop_end
L2: lea eax,NO
invoke crt_printf,addr szFmt,eax
jmp lop_end
lop_end:
int 3
invoke ExitProcess,0
main ENDP
END main
CMPSW 是对比一个字类型的数组,只有当数组中的数据完全一致的情况下才会返回真,否则为假.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array1 WORD 1,2,3,4,5 ; 必须全部相等才会清空ebx
Array2 WORD 1,3,5,7,9
.const
szFmt BYTE '数组: %s',0dh,0ah,0
YES BYTE "相等",0
NO BYTE "不相等",0
.code
main PROC
lea esi,Array1
lea edi,Array2
mov ecx,lengthof Array1
cld
repe cmpsw
je L1
lea eax,NO
invoke crt_printf,addr szFmt,eax
jmp lop_end
L1: lea eax,YES
invoke crt_printf,addr szFmt,eax
jmp lop_end
lop_end:
int 3
invoke ExitProcess,0
main ENDP
END main
CMPSD则是比较双字数据,同样可用于比较数组,这里就演示一下比较单数的情况.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
var1 DWORD 1234h
var2 DWORD 5678h
.const
szFmt BYTE '两者: %s',0dh,0ah,0
YES BYTE "相等",0
NO BYTE "不相等",0
.code
main PROC
lea esi,dword ptr ds:[var1]
lea edi,dword ptr ds:[var2]
cmpsd
je L1
lea eax,dword ptr ds:[YES]
invoke crt_printf,addr szFmt,eax
jmp lop_end
L1: lea eax,dword ptr ds:[NO]
invoke crt_printf,addr szFmt,eax
jmp lop_end
lop_end:
int 3
invoke ExitProcess,0
main ENDP
END main
扫描串指令: 扫描串指令包括SCASB、SCASW、SCASD其作用是把AL/AX/EAX中的值同EDI寻址的目标内存中的数据相比较,这些指令在一个长字符串或者数组中查找一个值的时候特别有用.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
szText BYTE "ABCDEFGHIJK",0
.const
szFmt BYTE '字符F所在位置: %d',0dh,0ah,0
.code
main PROC
; 寻找单一字符找到会返回第几个字符
lea edi,dword ptr ds:[szText]
mov al,"F"
mov ecx,lengthof szText -1
cld
repne scasb ; 如果不相等则重复扫描
je L1
xor eax,eax ; 如果没找到F则清空eax
jmp lop_end
L1: sub ecx,lengthof szText -1
neg ecx ; 如果找到输出第几个字符
invoke crt_printf,addr szFmt,ecx
lop_end:
int 3
main ENDP
END main
如果我们想要对数组中某个值是否存在做判断可以使用SCASD指令,对数组进行扫描.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
MyArray DWORD 65,88,93,45,67,89,34,67,89,22
.const
szFmt BYTE '数值: %d 存在',0dh,0ah,0
.code
main PROC
lea edi,dword ptr ds:[MyArray]
mov eax,34
mov ecx,lengthof MyArray - 1
cld
repne scasd
je L1
xor eax,eax
jmp lop_end
L1: sub ecx,lengthof MyArray - 1
neg ecx
invoke crt_printf,addr szFmt,ecx,eax
lop_end:
int 3
main ENDP
END main
储存串指令: 存储指令主要包括STOSB、STOSW、STOSD起作用是把AL/AX/EAX中的数据储存到EDI给出的地址中,执行后EDI的值根据方向标志的增加或减少,该指令常用于初始化内存或堆栈.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Count DWORD 100
String BYTE 100 DUP(?),0
.code
main PROC
; 利用该指令初始化字符串
mov al,0ffh ; 初始化填充数据
lea di,byte ptr ds:[String] ; 待初始化地址
mov ecx,Count ; 初始化字节数
cld ; 初始化:方向=前方
rep stosb ; 循环填充
; 存储字符串: 使用A填充内存
lea edi,dword ptr ds:[String]
mov al,"A"
mov ecx,Count
cld
rep stosb
int 3
main ENDP
END main
载入串指令: 载入指令主要包括LODSB、LODSW、LODSD起作用是将ESI指向的内存位置向AL/AX/EAX中装载一个值,同时ESI的值根据方向标志值增加或减少,如下分别完成加法与乘法计算,并回写到内存中.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
ArrayW WORD 1,2,3,4,5,6,7,8,9,10
ArrayDW DWORD 1,2,3,4,5
ArrayMulti DWORD 10
szFmt BYTE '计算结果: %d ',0dh,0ah,0
.code
main PROC
; 利用载入命令计算数组加法
lea esi,dword ptr ds:[ArrayW]
mov ecx,lengthof ArrayW
xor edx,edx
xor eax,eax
@@: lodsw ; 将输入加载到EAX
add edx,eax
loop @B
mov eax,edx ; 最后将相加结果放入eax
invoke crt_printf,addr szFmt,eax
; 利用载入命令(LODSD)与存储命令(STOSD)完成乘法运算
mov esi,offset ArrayDW ; 源指针
mov edi,esi ; 目的指针
cld ; 方向=向前
mov ecx,lengthof ArrayDW ; 循环计数器
L1: lodsd ; 加载[esi]至EAX
mul ArrayMulti ; 将EAX乘以10
stosd ; 将结果从EAX存储至[EDI]
loop L1
; 循环读取数据(存在问题)
mov esi,offset ArrayDW ; 获取基地址
mov ecx,lengthof ArrayDW ; 获取长度
xor eax,eax
@@: lodsd
invoke crt_printf,addr szFmt,eax
dec ecx
loop @B
int 3
main ENDP
END main
统计字符串: 过程StrLength()通过循环方式判断字符串结尾的0标志,来统计字符串的长度,最后将结果存储在EAX中.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
String BYTE "hello lyshark",0
szFmt BYTE '计算结果: %d ',0dh,0ah,0
.code
; 计算字符串长度
StrLength PROC USES edi,pString:PTR BYTE
mov edi,offset String ; 取出字符串的基地址
xor eax,eax ; 清空eax用作计数器
L1: cmp byte ptr [edi],0 ; 分别那[edi]的值和0作比较
je L2 ; 上一步为零则跳转得到ret
inc edi ; 否则继续执行
inc eax
jmp L1
L2: ret
StrLength endp
main PROC
invoke StrLength, addr String
invoke crt_printf,addr szFmt,eax
int 3
main ENDP
END main
字符串转换: 字符串转换是将小写转为大写,或者将大写转为小写,其原理是将二进制位第五位置1或0则可实现.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
MyString BYTE "hello lyshark",0
szFmt BYTE '结果: %s ',0dh,0ah,0
.code
main PROC
mov esi,offset MyString ; 取出字符串的偏移地址
L1: cmp byte ptr [esi],0 ; 分别拿出每一个字节,与0比较
je L2 ; 如果相等则跳转到L2
and byte ptr [esi],11011111b ; 执行按位与操作
inc esi ; 每次esi指针递增1
jmp L1 ; 重复循环
L2: lea eax,dword ptr ds:[MyString]
invoke crt_printf,addr szFmt,eax
ret
main ENDP
END main
字符串拷贝: 使用两个指针分别指向两处区域,然后通过变址寻址的方式实现对特定字符串的拷贝.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
source BYTE "hello lyshark welcome",0h
target BYTE SIZEOF source DUP(0),0h ; 取源地址数据大小
szFmt BYTE '结果: %s ',0dh,0ah,0
.code
main PROC
; 实现正向拷贝字符串
mov esi,0 ; 使用变址寄存器
mov ecx,sizeof source ; 循环计数器
L1:
mov al,byte ptr ds:[source + esi] ; 从源地址中取一个字符
mov byte ptr ds:[target + esi],al ; 将该字符存储在目标地址中
inc esi ; 递增,将指针移动到下一个字符
loop L1
lea eax,dword ptr ds:[target]
invoke crt_printf,addr szFmt,eax
; 实现反向拷贝字符串
mov esi,sizeof source
mov ecx,sizeof source
mov ebx,0
L2:
mov al,byte ptr ds:[source + esi]
mov byte ptr ds:[target + esi],al
dec esi
inc ebx
loop L2
lea eax,dword ptr ds:[target]
invoke crt_printf,addr szFmt,eax
push 0
call ExitProcess
main ENDP
END main
浮点数操作指令集(重点)
浮点数的计算是不依赖于CPU的,运算单元是从80486处理器开始才被集成到CPU中的,该运算单元被称为FPU浮点运算模块,FPU不使用CPU中的通用寄存器,其有自己的一套寄存器,被称为浮点数寄存器栈,FPU将浮点数从内存中加载到寄存器栈中,完成计算后在回写到内存中.
FPU有8个可独立寻址的80位寄存器,分别名为R0-R7他们以堆栈的形式组织在一起,栈顶由FPU状态字中的一个名为TOP的域组成,对寄存器的引用都是相对于栈顶而言的,栈顶通常也被叫做ST(0),最后一个栈底则被记作ST(7)其实用方式与堆栈完全一致.

浮点数运算通常会使用一些更长的数据类型,如下就是MASM汇编器定义的常用数据类型.
.data
var1 QWORD 10.1 ; 64位整数
var2 TBYTE 10.1 ; 80位(10字节)整数
var3 REAL4 10.2 ; 32位(4字节)短实数
var4 REAL8 10.8 ; 64位(8字节)长实数
var5 REAL10 10.10 ; 80位(10字节)扩展实数
此外浮点数对于指令的命名规范也遵循一定的格式,浮点数指令总是以F开头,而指令的第二个字母则表示操作位数,例如:B表示二十进制操作数,I表示二进制整数操作,如果没有指定则默认则是针对实数的操作fld等.
FLD/FSTP 操作指令: 这两个指令是最基本的浮点操作指令,其中的FLD入栈指令,后面的FSTP则是将浮点数弹出堆栈.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
var1 QWORD 10.0
var2 QWORD 20.0
var3 QWORD 30.0
var4 QWORD 40.0
result QWORD ?
.code
main PROC
; 初始化浮点单元
finit
; 依次将数据入栈
fld qword ptr ds:[var1]
fld qword ptr ds:[var2]
fld qword ptr ds:[var3]
fld qword ptr ds:[var4]
; 获取当前ST(0)栈帧元素
fst qword ptr ds:[result]
; 从栈中弹出元素
fstp qword ptr ds:[result]
fstp qword ptr ds:[result]
fstp qword ptr ds:[result]
fstp qword ptr ds:[result]
int 3
main ENDP
END main
压栈时会自动向下填充,而出栈时则相反,不但要出栈,还会将地址回绕到底部,覆盖掉底部的数据。

当压栈参数超出了最大承载范围,就会覆盖掉正常的数据,导致错误。
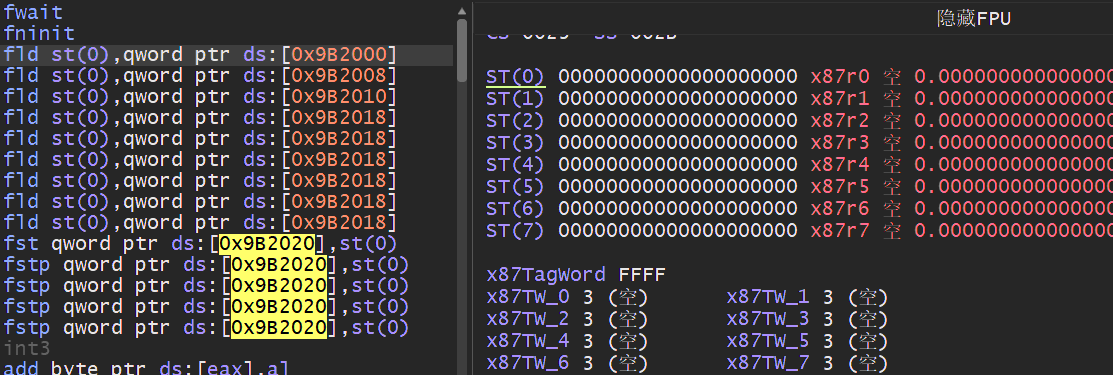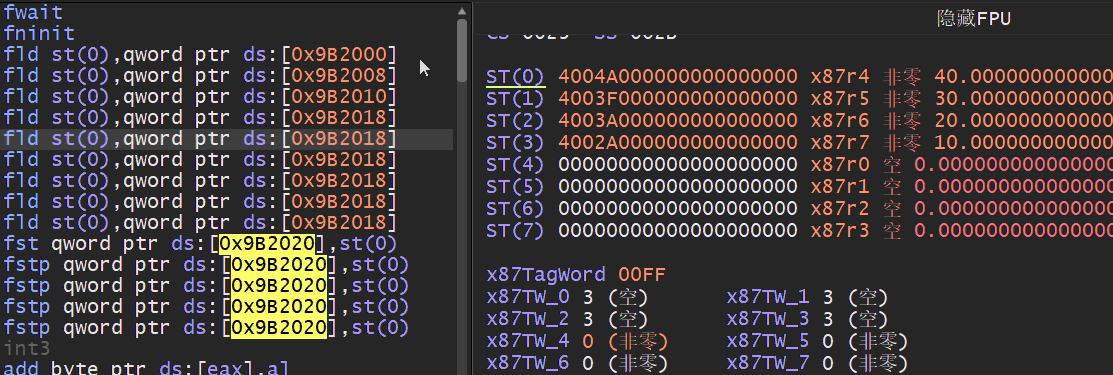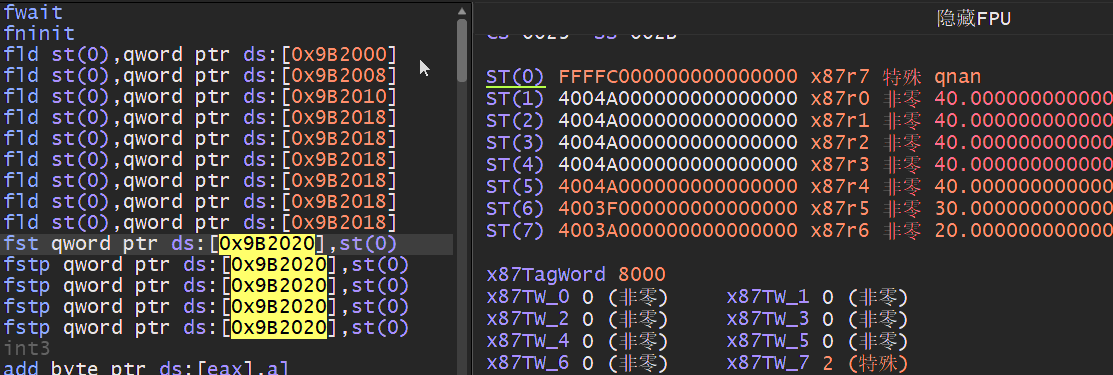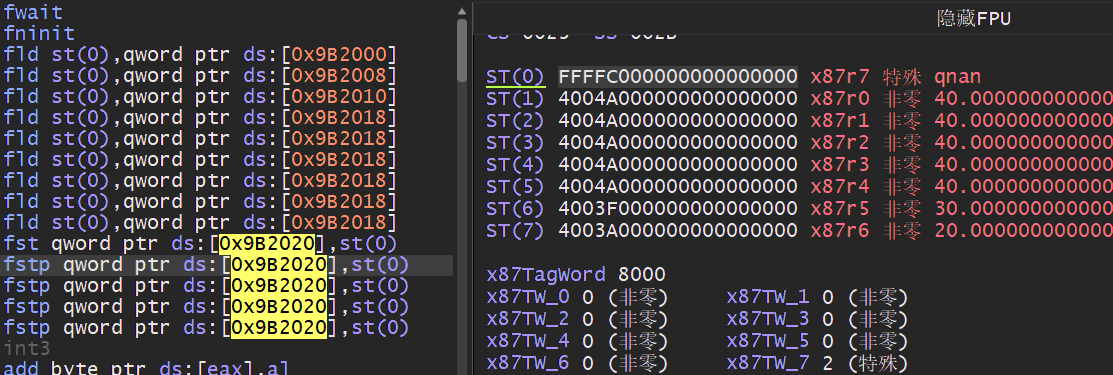
压栈同样支持变址寻址的方式,如下我们可以通过循环将一个数组压入浮点数寄存器,其中使用FLD指令时压入一个浮点实数,而FILD则是将实数转换为双精度浮点数后压入堆栈.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array QWORD 10.0,20.0,30.0,40.0,50.0
Count DWORD ?
Result QWORD ?
.code
main PROC
; 初始化浮点单元
finit
mov dword ptr ds:[Count],0
jmp L1
L2: mov eax,dword ptr ds:[Count]
add eax,1
mov dword ptr ds:[Count],eax
L1: mov eax,dword ptr ds:[Count]
cmp eax,5
jge lop_end
; 使用此方式压栈
fld qword ptr ds:[Array + eax * 8] ; 压入浮点实数
fild qword ptr ds:[Array + eax * 8] ; 压入双精度浮点数
jmp L2
lop_end:
int 3
main ENDP
END main
浮点交换指令: 浮点交换有两个指令需要特别注意,第一个是FCHS该指令把ST(0)中的值的符号变反,FABS指令则是取ST(0)中值的绝对值,这两条指令无传递操作数.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array QWORD 10.0,20.0,30.0,40.0,50.0
Result QWORD ?
szFmt BYTE 'ST寄存器: %f ',0dh,0ah,0
.code
main PROC
; 初始化压栈
finit
fld qword ptr ds:[Array]
fld qword ptr ds:[Array + 8]
fld qword ptr ds:[Array + 16]
fld qword ptr ds:[Array + 24]
fld qword ptr ds:[Array + 32]
; 对ST(0)数据取反 (不影响浮点堆栈)
fchs ; 对ST(0)取反
fchs ; 再次取反
fst qword ptr ds:[Result] ; 取ST(0)赋值到Result
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 循环将数组取反后回写如Array中
mov ecx,5
S1:
fchs
fstp qword ptr ds:[Array + ecx * 8]
loop S1
; 读入Array中的数据到ST寄存器
mov ecx,5
S2:
fld qword ptr ds:[Array + ecx * 8]
loop S2
; 通过FABS取绝对值,并反写会Array中
mov ecx,5
S3:
fabs ; 取ST(0)的绝对值
fstp qword ptr ds:[Array + ecx * 8] ; 反写
loop S3
int 3
main ENDP
END main
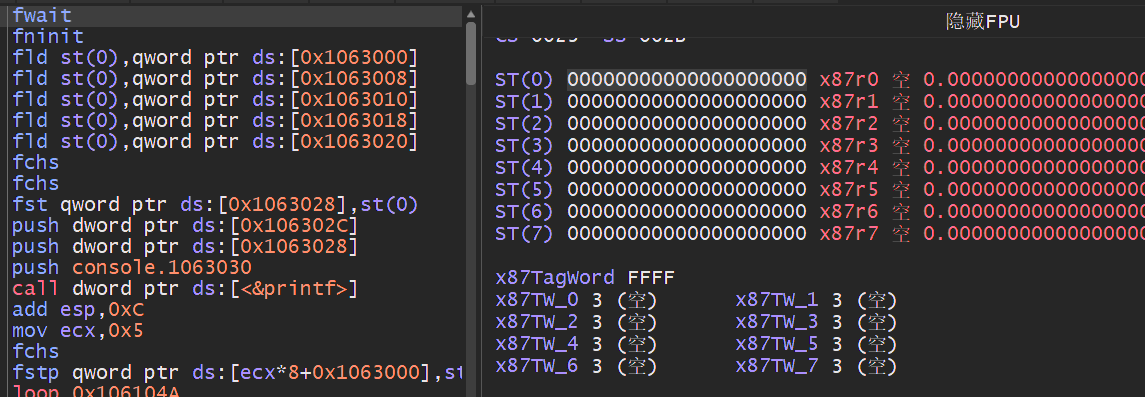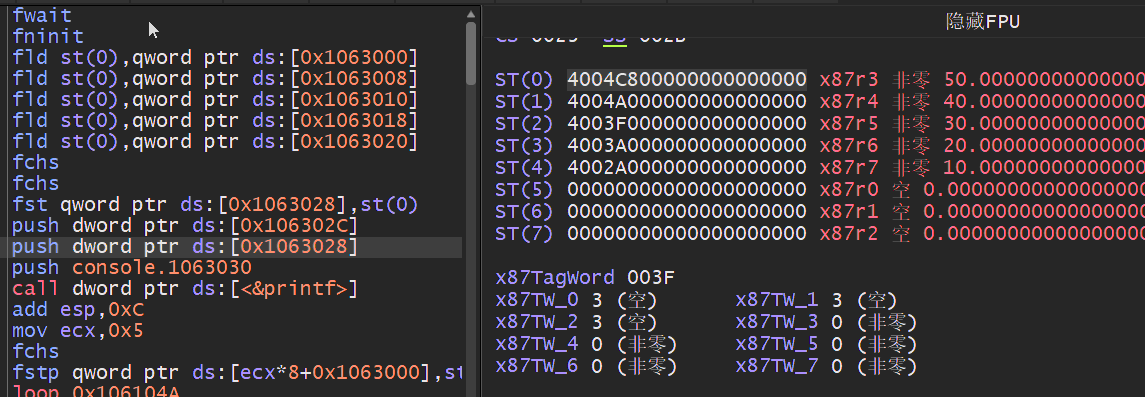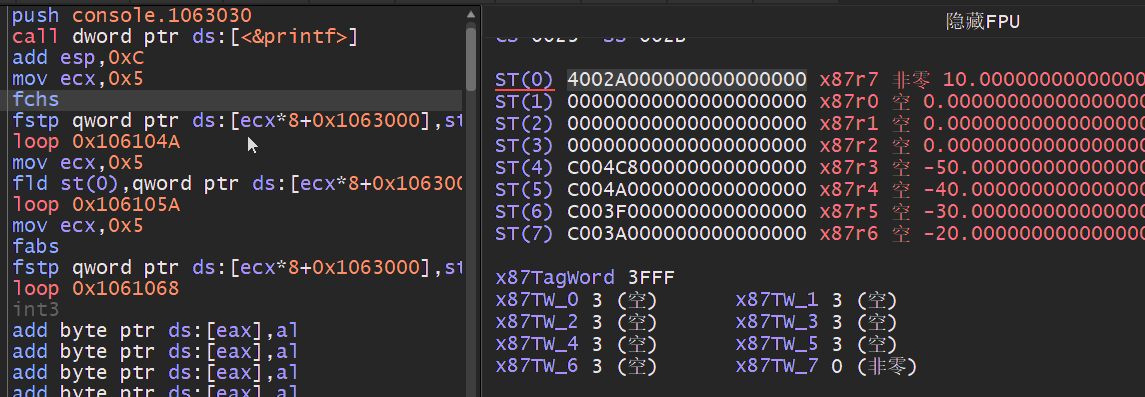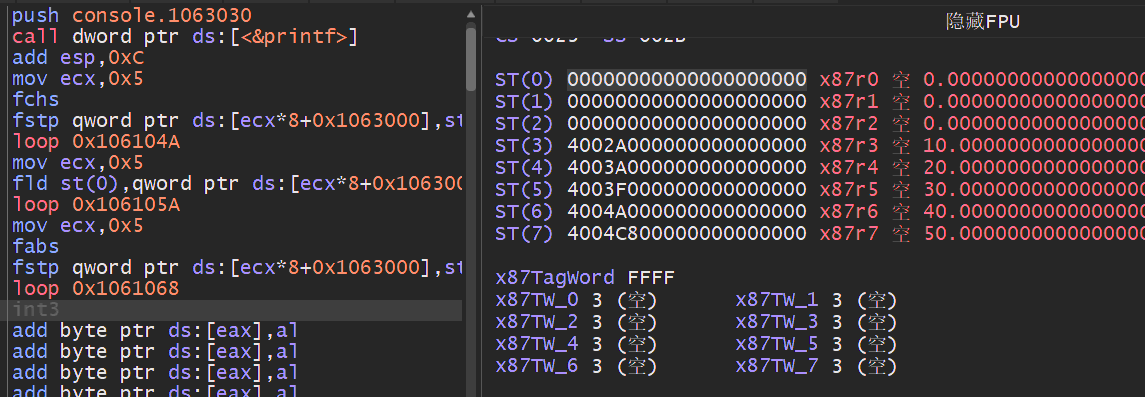
浮点加法指令: 浮点数加法,该加法分为FADD/FADDP/FIADD分别针对不同的场景,此外还会区分无操作数模式,寄存器操作数,内存操作数,整数相加等.
第一种无操作数模式,执行FADD时,ST(0)寄存器和ST(1)寄存器相加后,结果临时存储在ST(1)中,然后将ST(0)弹出堆栈,最终结果就会存储在栈顶部,使用FST指令即可取出来.
第二种则是两个浮点寄存器相加,最后的结果会存储在源操作数ST(0)中.
第三种则是内存操作数,就是ST寄存器与内存相加.
第四种是与整数相加,默认会将整数扩展为双精度,然后在于ST(0)相加.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array QWORD 10.0,20.0,30.0,40.0,50.0
IntA DWORD 10
Result QWORD ?
szFmt BYTE 'ST寄存器: %f ',0dh,0ah,0
.code
main PROC
finit
fld qword ptr ds:[Array]
fld qword ptr ds:[Array + 8]
fld qword ptr ds:[Array + 16]
fld qword ptr ds:[Array + 24]
fld qword ptr ds:[Array + 32]
; 第一种:无操作数 fadd = faddp
;fadd
;faddp
; 第二种:两个浮点寄存器相加
fadd st(0),st(1) ; st(0) = st(0) + st(1)
fst qword ptr ds:[Result] ; 取出结果
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fadd st(0),st(2) ; st(0) = st(0) + st(2)
fst qword ptr ds:[Result] ; 取出结果
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第三种:寄存器与内存相加
fadd qword ptr ds:[Array] ; st(0) = st(0) + Array
fst qword ptr ds:[Result] ; 取出结果
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fadd real8 ptr ds:[Array + 8]
fst qword ptr ds:[Result] ; 取出结果
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第四种:与整数相加
fiadd dword ptr ds:[IntA]
fst qword ptr ds:[Result] ; 取出结果
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
int 3
main ENDP
END main
浮点减法指令: 浮点数减法,该加法分为FSUB/FSUBP/FISUB该指令从目的操作数中减去原操作数,把差存储在目的操作数中,目的操作数必须是ST寄存器,源操作数可以是寄存器或内存,运算的过程与加法指令完全一致.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array QWORD 10.0,20.0,30.0,40.0,50.0
IntQWORD QWORD 20
Result QWORD ?
szFmt BYTE 'ST寄存器: %f ',0dh,0ah,0
.code
main PROC
finit
fld qword ptr ds:[Array]
fld qword ptr ds:[Array + 8]
fld qword ptr ds:[Array + 16]
fld qword ptr ds:[Array + 24]
fld qword ptr ds:[Array + 32]
; 第一种:无操作数减法
;fsub
;fsubp ; st(0) = st(0) - st(1)
; 第二种:两个浮点数寄存器相减
fsub st(0),st(1) ; st(0) = st(0) - st(1)
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第三种:寄存器与内存相减
fsub qword ptr ds:[Array] ; st(0) = st(0) - Array
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第四种:与整数相减
fisub dword ptr ds:[IntQWORD] ; st(0) = st(0) - IntQWORD
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
int 3
main ENDP
END main
浮点乘除法指令: 浮点数乘法指令有FMUL/FMULP/FIMUL,浮点数除法则包括FDIV/FDIVP/FIDIV这三种,其主要的使用手法与前面的加减法保持一致,下面是乘除法的总结.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array QWORD 10.0,20.0,30.0,40.0,50.0
IntQWORD QWORD 20
Result QWORD ?
szFmt BYTE 'ST寄存器: %f ',0dh,0ah,0
.code
InitFLD PROC
finit
fld qword ptr ds:[Array]
fld qword ptr ds:[Array + 8]
fld qword ptr ds:[Array + 16]
fld qword ptr ds:[Array + 24]
fld qword ptr ds:[Array + 32]
ret
InitFLD endp
main PROC
invoke InitFLD
; 第一种:无操作数乘法与除法
fmul
fmulp ; st(0) = st(0) * st(1)
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fdiv
fdivp ; st(0) = st(0) / st(1)
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第二种:两个浮点数寄存器之间的乘法与除法
invoke InitFLD
fmul st(0),st(4) ; st(0) = st(0) * st(4)
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fdiv st(0),st(2) ; st(0) = st(0) / st(2)
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第三种:寄存器与内存之间的乘法与除法
invoke InitFLD
fmul qword ptr ds:[Array + 8] ; st(0) = st(0) * [Array + 8]
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fdiv qword ptr ds:[Array + 16] ; st(0) = st(0) / [Array + 16]
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
; 第四种:与整数之间的乘法与除法
invoke InitFLD
fimul dword ptr ds:[IntQWORD] ; st(0) = st(0) * IntQWORD
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
fidiv dword ptr ds:[IntQWORD] ; st(0) = st(0) / IntQWORD
fst qword ptr ds:[Result]
invoke crt_printf,addr szFmt,qword ptr ds:[Result]
int 3
main ENDP
END main
浮点数比较指令: 浮点数比较指令包括FCOM/FCOMP/FCOMPP这三个指令都是比较ST(0)和源操作数,源操作数可以是内存操作数或FPU寄存器,FCOM和FCOMP格式基本一致,唯一区别在于FCOMP在执行对比后还要从堆栈中弹出元素,FCOMP和FCOMPP也基本一致,最后都是要从堆栈中弹出元素.
比较指令的重点就是比较条件码的状态,FPU中包括三个条件状态,分别是C3(零标志),C2(奇偶标志),C0(进位标志),我们可以使用FNSTSW指令将这些状态字送入AX寄存器中,然后通过SAHF指令把AH赋值到EFLAGS标志中,一旦标志状态被送入EFLAGS寄存器,那么就可以使用标准的标志位对跳转指令进行影响了,例如以下代码的汇编案例.
double x = 1.2; double y = 3.0; int n = 0;
if(x<y)
{
n=1;
}
; ----------------------------------------------------
; C语言伪代码的汇编指令如下
; ----------------------------------------------------
.data
x REAL8 1.2
y REAL8 3.0
n DWORD 0
.code
main PROC
fld x ; st(0) = x
fcomp y ; cmp x,y ; pop x
fnstsw ax ; 取出状态值送入AX
sahf ; 将状态字送入EFLAGS
jnb L1 ; x < y 小于
mov n,1 ; 满足则将n置1
L1: xor eax,eax ; 否则清空寄存器
int 3
main ENDP
END main
对于前面的案例来说,由于浮点数运算比整数运算在开销上会更大一些,因此Intel新版处理器新增加了FCOMI指令,专门用于比较两个浮点数的值,并自动设置零标志,基偶标志,和进位标志,唯一的缺点是其不支持内存操作数,针对上方案例的修改如下.
.data
x REAL8 1.2
y REAL8 3.0
n DWORD 0
.code
main PROC
fld y
fld x
fcomi st(0),st(1)
jnb L1 ; st(0) not st(1) ?
mov n,1
L1: xor eax,eax
int 3
main ENDP
END main
对于浮点数的比较来说,例如比较X与Y是否相等,如果比较X==y?则可能会出现近似值的情况,导致无法计算出正确结果,正确的做法是取其差值的绝对值,并和用户自定义的小的正数相比较,小的正整数作为两个值相等时其差值的临界值.
.data
epsilon REAL8 1.0E-12
var2 REAL8 0.0
var3 REAL8 1.001E-13
.code
main PROC
fld epsilon
fld var2
fsub var3
fabs
fcomi st(0),st(1) ; cmp epsilon,var2
ja skip
xor ebx,ebx ; 相等则清空ebx
skip:
int 3 ; 不相等则结束
main ENDP
END main
浮点表达式: 通过浮点数计算表达式valD = -valA + (valB * valC)其计算过程,首先加载ValA并取反,加载valB至ST(0),这时-ValA保存在ST(1)中,valC和ST(0)相乘,乘基保存在ST(0)中,最后ST(0)与ST(1)相加后存入ValD中.
.data
valA REAL8 1.5
valB REAL8 2.5
valC REAL8 3.0
valD REAL8 ?
.code
main PROC
fld valA ; 加载valA
fchs ; 取反-valA
fld valB ; 加载valB = st(0)
fmul valC ; st(0) = st(0) * valC
fadd ; st(0) = st(0) + st(1)
fstp valD ; valD = st(0)
main ENDP
END main
通过循环计算一个双精度数组中所有元素的总和.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.data
MyArray REAL8 10.0,20.0,30.0,40.0,50.0
.code
main PROC
mov esi,0 ; 设置因子
fldz ; st(0)清空
mov ecx,5 ; 设置数组数
L1: fld MyArray[esi] ; 压入栈
fadd ; st(0) = st(0) + MyArray[esi]
add esi,TYPE REAL8 ; esi += 8
loop L1
main ENDP
END main
求ValA与ValB两数的平方根,FSQRT指令计算ST(0)的平方根并把结果存储在ST(0)中,如下是计算平方根方法.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.data
valA REAL8 25.0
valB REAL8 39.0
.code
main PROC
fld valA
fsqrt ; st(0) = sqrt(valA)
fld valB ; push valB
fsqrt ; st(0) = sqrt(valB)
fadd ; add st(0),st(1)
main ENDP
END main
接着看一下计算数组的点积面,例如(Array[0] * Array[1]) + (Array[2] * Array[3])这种计算就叫做点积面计算.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.data
Array REAL4 6.0,3.0,5.0,7.0
.code
main PROC
fld Array
fmul [Array + 4]
fld [Array + 8]
fmul [Array + 12]
fadd
main ENDP
END main
有时候我们需要混合计算,也就是整数与双精度浮点数进行运算,此时在执行运算前会将整数自动提升为浮点数,例如下面的两个案例,第一个是整数与浮点数相加时,整数自动提升为浮点数,第二个则需要调用FIST指令对Z向上裁剪保留整数部分.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.data
N DWORD 20
X REAL8 3.5
Z REAL8 ?
.code
main PROC
; 计算 int N = 20; double X = 3.5; double Z = N + X;
fild N ; 加载整数到ST(0)
fadd X ; ST(0) = ST(0) + X
fstp Z ; 存储到Z中
; 计算 int N = 20; double X = 3.5; int Z=(int)(N+X)
fild N
fadd X
fist E ; 将浮点数裁剪,只保留整数部分
main ENDP
END main
过程与结构体(扩展知识点)
过程的实现离不开堆栈的应用,堆栈是一种后进先出(LIFO)的数据结构,最后压入栈的值总是最先被弹出,而新数值在执行压栈时总是被压入到栈的最顶端,栈主要功能是暂时存放数据和地址,通常用来保护断点和现场.
栈是由CPU管理的线性内存数组,它使用两个寄存器(SS和ESP)来保存栈的状态.SS寄存器存放段选择符,而ESP寄存器的值通常是指向特定位置的一个32位偏移值,我们很少需要直接操作ESP寄存器,相反的ESP寄存器总是由CALL,RET,PUSH,POP等这类指令间接性的修改.
CPU系统提供了两个特殊的寄存器用于标识位于系统栈顶端的栈帧.
ESP 栈指针寄存器: 栈指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶.
EBP 基址指针寄存器: 基址指针寄存器,其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部.
在通常情况下ESP是可变的,随着栈的生成而逐渐变小,而EBP寄存器是固定的,只有当函数的调用后,发生入栈操作而改变.
执行PUSH压栈时,堆栈指针自动减4,再将压栈的值复制到堆栈指针所指向的内存地址.
执行POP出栈时,从栈顶移走一个值并将其复制给内存或寄存器,然后再将堆栈指针自动加4.
执行CALL调用时,CPU会用堆栈保存当前被调用过程的返回地址,直到遇到RET指令再将其弹出.
PUSH/POP 入栈出栈: 执行PUSH指令时,首先减小ESP的值,然后把源操作数复制到堆栈上,执行POP指令则是先将数据弹出到目的操作数中,然后在执行ESP值增加4,如下案例,分别将数组中的元素压入栈,并且通过POP将元素反弹出来.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
Array DWORD 1,2,3,4,5,6,7,8,9,10
szFmt BYTE '%d ',0dh,0ah,0
.code
main PROC
; 使用Push指令将数组正向入栈
mov eax,0
mov ecx,10
S1:
push dword ptr ds:[Array + eax * 4]
inc eax
loop S1
; 使用pop指令将数组反向弹出
mov ecx,10
S2:
push ecx ; 保护ecx
pop ebx ; 将Array数组元素弹出到ebx
invoke crt_printf,addr szFmt,ebx
pop ecx ; 弹出ecx
loop S2
int 3
main ENDP
END main
由于堆栈是先进后出的结构,所以我们可以利用这一特性,首先循环将字符串压入堆栈,然后再从堆栈中反向弹出来,这样就可以实现字符串的反转操作了,实现代码如下:
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
MyString BYTE "hello lyshark",0
NameSize DWORD ($ - MyString) - 1
szFmt BYTE '%s',0dh,0ah,0
.code
main PROC
; 正向压入字符串
mov ecx,dword ptr ds:[NameSize]
mov esi,0
S1: movzx eax,byte ptr ds:[MyString + esi]
push eax
inc esi
loop S1
; 反向弹出字符串
mov ecx,dword ptr ds:[NameSize]
mov esi,0
S2: pop eax
mov byte ptr ds:[MyString + esi],al
inc esi
loop S2
invoke crt_printf,addr szFmt,addr MyString
int 3
main ENDP
END main
PROC/ENDP 伪指令: 该指令可用于创建过程化流程,过程使用PROC和ENDP伪指令来声明,下面我们通过使用过程创建ArraySum方法,实现对整数数组求和操作,默认规范将返回值存储在EAX中,直接打印出来就好.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
MyArray DWORD 1,2,3,4,5,6,7,8,9,10
Sum DWORD ?
szFmt BYTE '%d',0dh,0ah,0
.code
; 数组求和过程
ArraySum PROC
push esi ; 保存ESI,ECX
push ecx
xor eax,eax
S1: add eax,dword ptr ds:[esi] ; 取值并相加
add esi,4 ; 递增数组指针
loop S1
pop ecx ; 恢复ESI,ECX
pop esi
ret
ArraySum endp
main PROC
lea esi,dword ptr ds:[MyArray] ; 取出数组基址
mov ecx,lengthof MyArray ; 取出元素数目
call ArraySum ; 调用方法
mov dword ptr ds:[Sum],eax ; 得到结果
invoke crt_printf,addr szFmt,Sum
int 3
main ENDP
END main
接着来实现一个获取随机数的案例,具体原理就是获取随机种子,使用除法运算取出溢出数据作为随机数使用,特殊常量地址343FDh每次访问也会产出一个随机的数据.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
seed DWORD 1
szFmt BYTE '随机数: %d',0dh,0ah,0
.code
; 生成 0 - FFFFFFFFh 的随机种子
Random32 PROC
push edx
mov eax, 343FDh
imul seed
add eax, 269EC3h
mov seed, eax
ror eax,8
pop edx
ret
Random32 endp
; 生成随机数
RandomRange PROC
push ebx
push edx
mov ebx,eax
call Random32
mov edx,0
div ebx
mov eax,edx
pop edx
pop ebx
ret
RandomRange endp
main PROC
; 调用后取出随机数
call RandomRange
invoke crt_printf,addr szFmt,eax
int 3
main ENDP
END main
局部变量与堆栈传参: 局部变量是在程序运行时,由系统动态的在栈上开辟的,在内存中通常在基址指针(EBP)之下,尽管在汇编时不能给定默认值,但可以在运行时初始化,如下一段伪代码:
void MySub()
{
int var1 = 10;
int var2 = 20;
}
上面的一段代码经过C编译后,会变成如下,其中EBP-4必须是4的倍数,因为默认就是4字节存储,如果去掉了mov esp,ebp,那么当执行pop ebp时将会得到EBP等于10,执行RET指令会导致控制转移到内存地址10处执行,从而程序会崩溃.
MySub PROC
push ebp ; 将EBP存储在栈中
mov ebp,esp ; 堆栈框架的基址
sub esp,8 ; 创建局部变量空间(分配2个局部变量)
mov DWORD PTR [ebp-8],10 ; var1 = 10
mov DWORD PTR [ebp-4],20 ; var2 = 20
mov esp,ebp ; 从堆栈上删除局部变量
pop ebp ; 恢复EBP指针
ret 8 ; 返回,清理堆栈
MySub ENDP
为了使代码更容易阅读,可以在上面的代码的基础上给每个变量的引用地址都定义一个符号,并在代码中使用这些符号.
var1_local EQU DWORD PTR [ebp-8] ; 添加符号1
var2_local EQU DWORD PTR [ebp-4] ; 添加符号2
MySub PROC
push ebp
mov ebp,esp
sub esp,8
mov var1_local,10
mov var2_local,20
mov esp,ebp
pop ebp
ret 8
MySub ENDP
接着我们来写一个案例,首先C语言伪代码如下,其中的MakeArray()函数内部是动态生成的一个MyString数组,然后通过循环填充为星号,最后使用POP弹出,并输出结果,观察后尝试用汇编实现.
void makeArray()
{
char MyString[30];
for(int i=0;i<30;i++)
{
myString[i] = "*";
}
}
call makeArray()
汇编代码如下,唯一需要注意的地方就是出栈是平栈参数,例如我们使用了影响堆栈操作的指令,则平栈要手动校验并修复.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
szFmt BYTE '出栈数据: %x ',0dh,0ah,0
.code
makeArray PROC
push ebp
mov ebp,esp
; 开辟局部数组
sub esp,32 ; MyString基地址位于 [ebp - 30]
lea esi,[ebp - 30] ; 加载MyString的地址
; 填充数据
mov ecx,30 ; 循环计数
S1: mov byte ptr ds:[esi],'*' ; 填充为*
inc esi ; 每次递增一个字节
loop S1
; 弹出2个元素并输出,出栈数据
pop eax
invoke crt_printf,addr szFmt,eax
pop eax
invoke crt_printf,addr szFmt,eax
; 以下平栈,由于我们手动弹出了2个数据
; 则平栈 32 - (2 * 4) = 24
add esp,24 ; 平栈
mov esp,ebp
pop ebp ; 恢复EBP
ret
makeArray endp
main PROC
call makeArray
invoke ExitProcess,0
main ENDP
END main
接着来看一下堆栈传参中平栈方的区别,平栈方可以是调用者平栈也可以由被调用者平,如下案例分别演示了两种平栈方式.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
szFmt BYTE '数据: %d ',0dh,0ah,0
.code
; 第一种方式:被调用者平栈
MyProcA PROC
push ebp
mov ebp,esp
xor eax,eax
mov eax,dword ptr ss:[ebp + 16] ; 获取第一个参数
mov ebx,dword ptr ss:[ebp + 12] ; 获取第二个参数
mov ecx,dword ptr ss:[ebp + 8] ; 获取第三个参数
add eax,ebx
add eax,ebx
add eax,ecx
mov esp,ebp
pop ebp
ret 12 ; 此处ret12可平栈,也可使用 add ebp,12
MyProcA endp
; 第二种方式:调用者平栈
MyProcB PROC
push ebp
mov ebp,esp
mov eax,dword ptr ss:[ebp + 8]
add eax,10
mov esp,ebp
pop ebp
ret
MyProcB endp
main PROC
; 第一种被调用者MyProcA平栈 3*4 = 12
push 1
push 2
push 3
call MyProcA
invoke crt_printf,addr szFmt,eax
; 第二种方式:调用者平栈
push 10
call MyProcB
add esp,4
invoke crt_printf,addr szFmt,eax
int 3
main ENDP
END main
如果使用PROC定义过程,则传递参数是可以使用push的方式实现堆栈传参,如下所示.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
szFmt BYTE '计算参数: %d ',0dh,0ah,0
.code
my_proc PROC x:DWORD,y:DWORD,z:DWORD ; 定义过程局部参数
LOCAL @sum:DWORD ; 定义局部变量存放总和
mov eax,dword ptr ds:[x]
mov ebx,dword ptr ds:[y] ; 分别获取到局部参数
mov ecx,dword ptr ds:[z]
add eax,ebx
add eax,ecx ; 相加后放入eax
mov @sum,eax
ret
my_proc endp
main PROC
LOCAL @ret_sum:DWORD
push 10
push 20
push 30 ; 传递参数
call my_proc
mov @ret_sum,eax ; 获取结果并打印
invoke crt_printf,addr szFmt,@ret_sum
int 3
main ENDP
END main
局部变量操作符: 上方的代码中我们在申请局部变量时都是通过手动计算的,在汇编中可以使用LOCAL伪指令来实现自动计算局部变量空间,以及最后的平栈,极大的提高了开发效率.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.code
main PROC
; 定义局部变量,自动压栈/平栈
LOCAL var_byte:BYTE,var_word:WORD,var_dword:DWORD
LOCAL var_array[3]:DWORD
; 填充局部变量
mov byte ptr ds:[var_byte],1
mov word ptr ds:[var_word],2
mov dword ptr ds:[var_dword],3
; 填充数组方式1
lea esi,dword ptr ds:[var_array]
mov dword ptr ds:[esi],10
mov dword ptr ds:[esi + 4],20
mov dword ptr ds:[esi + 8],30
; 填充数组方式2
mov var_array[0],100
mov var_array[1],200
mov var_array[2],300
invoke ExitProcess,0
main ENDP
END main
USES/ENTER 伪指令: 指令USES的作用是当我们需要压栈保存指定寄存器时,可以使用此关键字,汇编器会自动为我们保存寄存器中参数,ENTER指令则是预定义保留局部变量的指令.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
.code
; USES 自动压入 eax,ebx,ecx,edx
my_proc PROC USES eax ebx ecx edx x:DWORD,y:DWORD
enter 8,0 ; 自动保留8字节堆栈空间
add eax,ebx
leave
my_proc endp
main PROC
mov eax,10
mov ebx,20
call my_proc
int 3
main ENDP
END main
堆栈传参(递归阶乘): 通过EAX寄存器传递一个数值,然后使用Factorial过程递归调用自身,实现对该数阶乘的计算.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
.data
szFmt BYTE '数据: %d ',0dh,0ah,0
.code
Factorial PROC
push ebp
mov ebp,esp
mov eax,dword ptr ss:[ebp + 8] ; 取出参数
cmp eax,0 ; eax > 0 ?
ja L1
mov eax,1 ; 否则返回1
jmp L2
L1: dec eax
push eax
call Factorial ; 调用自身
mov ebx,dword ptr ss:[ebp + 8]
mul ebx ; 取参数/相乘
L2: mov esp,ebp
pop ebp
ret 4
Factorial endp
main PROC
; 第一组
push 3
call Factorial
invoke crt_printf,addr szFmt,eax
; 第二组
push 5
call Factorial
invoke crt_printf,addr szFmt,eax
int 3
main ENDP
END main
Struct/Union 结构与联合体: 结构体就是将一组不同内存属性的变量封装成为统一的整体,结构常用于定义组合的数据类型,结构在内存中的分布也是线性的,其存储形式与数组非常相似,我们同样可以使用数组的规范化排列实现一个结构体.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
; 定义人物结构
MyPerson Struct
Fname db 20 dup(0)
fAge db 100
fSex db 20
MyPerson ends
.data
; 声明结构: 使用 <>,{}符号均可
PtrA MyPoint <10,20,30>
PtrB MyPoint {100,200,300}
; 声明结构: 使用MyPerson声明结构
UserA MyPerson <'lyshark',24,1>
.code
main PROC
; 获取结构中的数据
lea esi,dword ptr ds:[PtrA]
mov eax,(MyPoint ptr ds:[esi]).pos_x
mov ebx,(MyPoint ptr ds:[esi]).pos_y
mov ecx,(MyPoint ptr ds:[esi]).pos_z
; 向结构中写入数据
lea esi,dword ptr ds:[PtrB]
mov (MyPoint ptr ds:[esi]).pos_x,10
mov (MyPoint ptr ds:[esi]).pos_y,20
mov (MyPoint ptr ds:[esi]).pos_z,30
; 直接获取结构中的数据
mov eax,dword ptr ds:[UserA.Fname]
mov ebx,dword ptr ds:[UserA.fAge]
int 3
main ENDP
END main
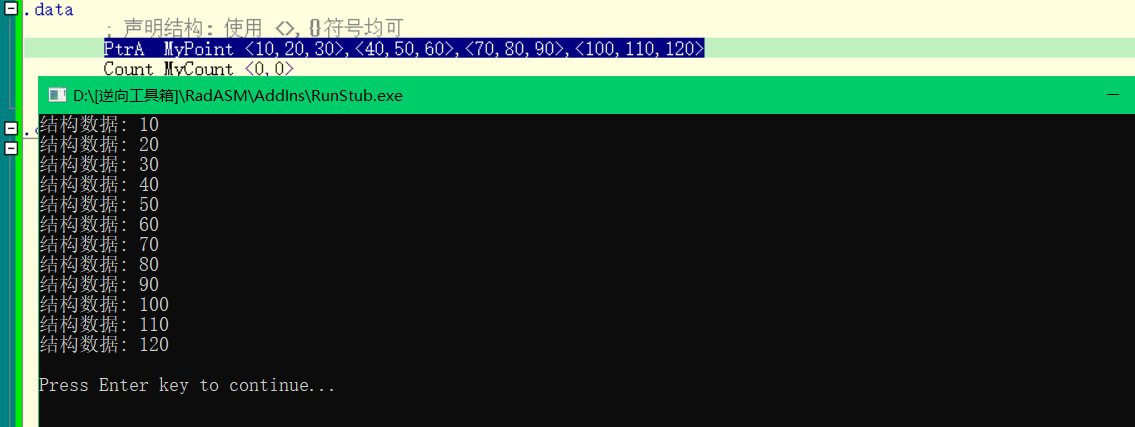
结构数组的构造与寻址,第一次总结,存在问题的,寻址是否可以这样 mov eax,dword ptr ds:[PtrA + esi + ecx * 4]
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
.data
; 声明结构: 使用 <>,{}符号均可
PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>
szFmt BYTE '结构数据: %d',0dh,0ah,0
.code
main PROC
; 获取结构中的数据
lea esi,dword ptr ds:[PtrA]
mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构X
mov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X
; 循环遍历结构中的所有值
mov esi,0 ; 遍历每个结构
mov ecx,4 ; 循环4个大结构
S1:
push ecx
mov ecx,3
S2:
mov eax,dword ptr ds:[PtrA + esi + ecx * 4]
invoke crt_printf,addr szFmt,eax
pop ecx
loop S2
add esi,12
loop S1
int 3
main ENDP
END main
输出数组的第二种方式
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
; 定义循环结构
MyCount Struct
count_x DWORD ?
count_y DWORD ?
MyCount ends
.data
; 声明结构: 使用 <>,{}符号均可
PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>
Count MyCount <0,0>
szFmt BYTE '结构数据: %d',0dh,0ah,0
.code
main PROC
; 获取结构中的数据
lea esi,dword ptr ds:[PtrA]
mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构X
mov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X
; while 循环输出结构的每个首元素元素
mov (MyCount ptr ds:[Count]).count_x,0
S1: cmp (MyCount ptr ds:[Count]).count_x,48 ; 12 * 4 = 48
jge lop_end
mov ecx,(MyCount ptr ds:[Count]).count_x
mov eax,dword ptr ds:[PtrA + ecx] ; 寻找首元素
invoke crt_printf,addr szFmt,eax
mov eax,(MyCount ptr ds:[Count]).count_x
add eax,12 ; 每次递增12
mov (MyCount ptr ds:[Count]).count_x,eax
jmp S1
; while 煦暖输出整个PtrA结构中的成员
mov (MyCount ptr ds:[Count]).count_x,0 ; 初始化 count_x
S2: cmp (MyCount ptr ds:[Count]).count_x,48 ; 设置循环次数 12 * 4 = 48
jge lop_end
; mov ecx,(MyCount ptr ds:[Count]).count_x
; mov eax,dword ptr ds:[PtrA + ecx] ; 寻找首元素
; invoke crt_printf,addr szFmt,eax
mov (MyCount ptr ds:[Count]).count_y,0
S4: cmp (MyCount ptr ds:[Count]).count_y,12 ; 内层循环 3 * 4 = 12
jge S3
mov ebx,(MyCount ptr ds:[Count]).count_x
add ecx,(MyCount ptr ds:[Count]).count_y
mov eax,dword ptr ds:[PtrA + ecx]
invoke crt_printf,addr szFmt,eax
mov eax,(MyCount ptr ds:[Count]).count_y
add eax,4 ; 每次递增4字节
mov (MyCount ptr ds:[Count]).count_y,eax
jmp S4
S3: mov eax,(MyCount ptr ds:[Count]).count_x
add eax,12 ; 每次递增12
mov (MyCount ptr ds:[Count]).count_x,eax
jmp S1
lop_end:
int 3
main ENDP
END main
在上面的基础上继续递增,每次递增将两者的偏移相加,获得比例因子,嵌套双层循环实现寻址打印.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
; 定义循环结构
MyCount Struct
count_x DWORD ?
count_y DWORD ?
MyCount ends
.data
; 声明结构: 使用 <>,{}符号均可
PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>
Count MyCount <0,0>
szFmt BYTE '结构数据: %d',0dh,0ah,0
.code
main PROC
; 获取结构中的数据
lea esi,dword ptr ds:[PtrA]
mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构X
mov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X
; while 循环输出结构的每个首元素元素
mov (MyCount ptr ds:[Count]).count_x,0
S1: cmp (MyCount ptr ds:[Count]).count_x,48 ; 12 * 4 = 48
jge lop_end
mov (MyCount ptr ds:[Count]).count_y,0
S3: cmp (MyCount ptr ds:[Count]).count_y,12
jge S2
mov eax,(MyCount ptr ds:[Count]).count_x
add eax,(MyCount ptr ds:[Count]).count_y
invoke crt_printf,addr szFmt,eax
mov eax,(MyCount ptr ds:[Count]).count_y
add eax,4
mov (MyCount ptr ds:[Count]).count_y,eax
jmp S3
S2: mov eax,(MyCount ptr ds:[Count]).count_x
add eax,12 ; 每次递增12
mov (MyCount ptr ds:[Count]).count_x,eax
jmp S1
lop_end:
int 3
main ENDP
END main
最终可以完成寻址,输出这个结构数组中的所有数据了
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
; 定义循环结构
MyCount Struct
count_x DWORD ?
count_y DWORD ?
MyCount ends
.data
; 声明结构: 使用 <>,{}符号均可
PtrA MyPoint <10,20,30>,<40,50,60>,<70,80,90>,<100,110,120>
Count MyCount <0,0>
szFmt BYTE '结构数据: %d',0dh,0ah,0
.code
main PROC
; 获取结构中的数据
lea esi,dword ptr ds:[PtrA]
mov eax,(MyPoint ptr ds:[esi]).pos_x ; 获取第一个结构X
mov eax,(MyPoint ptr ds:[esi + 12]).pos_x ; 获取第二个结构X
; while 循环输出结构的每个首元素元素
mov (MyCount ptr ds:[Count]).count_x,0
S1: cmp (MyCount ptr ds:[Count]).count_x,48 ; 12 * 4 = 48
jge lop_end
mov (MyCount ptr ds:[Count]).count_y,0
S3: cmp (MyCount ptr ds:[Count]).count_y,12 ; 3 * 4 = 12
jge S2
mov eax,(MyCount ptr ds:[Count]).count_x
add eax,(MyCount ptr ds:[Count]).count_y ; 相加得到比例因子
mov eax,dword ptr ds:[PtrA + eax] ; 使用相对变址寻址
invoke crt_printf,addr szFmt,eax
mov eax,(MyCount ptr ds:[Count]).count_y
add eax,4 ; 每次递增4
mov (MyCount ptr ds:[Count]).count_y,eax
jmp S3
S2: mov eax,(MyCount ptr ds:[Count]).count_x
add eax,12 ; 每次递增12
mov (MyCount ptr ds:[Count]).count_x,eax
jmp S1
lop_end:
int 3
main ENDP
END main
结构体同样支持内嵌的方式,如下Rect指针中内嵌两个MyPoint分别指向左子域和右子域,这里顺便定义一个MyUnion联合体把,其使用规范与结构体完全一致,只不过联合体只能存储一个数据.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
; 定义坐标结构
MyPoint Struct
pos_x DWORD ?
pos_y DWORD ?
pos_z DWORD ?
MyPoint ends
; 定义左右结构
Rect Struct
Left MyPoint <>
Right MyPoint <>
Rect ends
; 定义联合体
MyUnion Union
my_dword DWORD ?
my_word WORD ?
my_byte BYTE ?
MyUnion ends
.data
PointA Rect <>
PointB Rect {<10,20,30>,<100,200,300>}
test_union MyUnion {1122h}
szFmt BYTE '结构数据: %d',0dh,0ah,0
.code
main PROC
; 嵌套结构的赋值
mov dword ptr ds:[PointA.Left.pos_x],100
mov dword ptr ds:[PointA.Left.pos_y],200
mov dword ptr ds:[PointA.Right.pos_x],100
mov dword ptr ds:[PointA.Right.pos_y],200
; 通过地址定位
lea esi,dword ptr ds:[PointB]
mov eax,dword ptr ds:[PointB] ; 定位第一个MyPoint
mov eax,dword ptr ds:[PointB + 12] ; 定位第二个内嵌MyPoint
; 联合体的使用
mov eax,dword ptr ds:[test_union.my_dword]
mov ax,word ptr ds:[test_union.my_word]
mov al,byte ptr ds:[test_union.my_byte]
main ENDP
END main
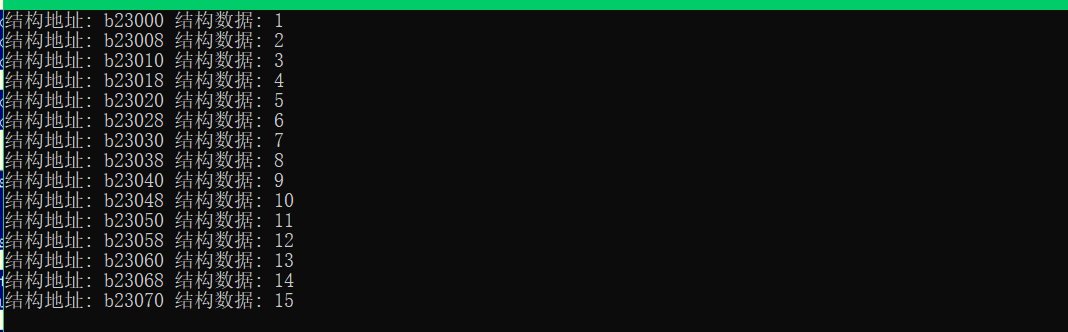
结构体定义链表: 首先定义一个ListNode用于存储链表结构的数据域与指针域,接着使用TotalNodeCount定义链表节点数量,最后使用REPEAT伪指令开辟ListNode对象的多个实例,其中的NodeData域包含一个1-15的数据,后面的($ + Counter * sizeof ListNode)则是指向下一个链表的头指针,先来看一下其内存分布.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
ListNode Struct
NodeData DWORD ?
NextPtr DWORD ?
ListNode ends
TotalNodeCount = 15
NULL = 0
Counter = 0
.data
LinkList LABEL PTR ListNode
REPEAT TotalNodeCount
Counter = Counter + 1
ListNode <Counter,($ + Counter * sizeof ListNode)>
ENDM
ListNode<0,0>
.code
main PROC
mov esi,offset LinkList
main ENDP
END main

接着来完善实现对链表结构的遍历。
结构体定义链表: 首先定义一个ListNode用于存储链表结构的数据域与指针域,接着使用TotalNodeCount定义链表节点数量,最后使用REPEAT伪指令开辟ListNode对象的多个实例,其中的NodeData域包含一个1-15的数据,后面的($ + Counter * sizeof ListNode)则是指向下一个链表的头指针,先来看一下其内存分布.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include kernel32.inc
includelib kernel32.lib
include msvcrt.inc
includelib msvcrt.lib
ListNode Struct
NodeData DWORD ?
NextPtr DWORD ?
ListNode ends
TotalNodeCount = 15
Counter = 0
.data
LinkList LABEL PTR ListNode
REPEAT TotalNodeCount
Counter = Counter + 1
ListNode <Counter,($ + Counter * sizeof ListNode)>
ENDM
ListNode<0,0>
szFmt BYTE '结构地址: %x 结构数据: %d',0dh,0ah,0
.code
main PROC
mov esi,offset LinkList
; 判断下一个节点是否为<0,0>
L1: mov eax,(ListNode PTR [esi]).NextPtr
cmp eax,0
je lop_end
; 显示节点数据
mov eax,(ListNode PTR [esi]).NodeData
invoke crt_printf,addr szFmt,esi,eax
; 获取到下一个节点的指针
mov esi,(ListNode PTR [esi]).NextPtr
jmp L1
lop_end:
int 3
main ENDP
END main