深层神经网络的参数学习主要通过梯度下降法来寻找一组可以最小化结构风险的参数。在具体实现中,梯度下降法可以分为:批量梯度下降、随机梯度下降和小批量梯度下降三种形式。
而对于这三种梯度下降的方法,又可以从调整学习率、调整负梯度两个方向来进行改进,比如RMSprop,Momentum和Adam。
这里介绍比较常用的小批量梯度下降,以及自适应调整学习率和梯度方向优化的两种算法。
一、小批量梯度下降(MBGD)
批量梯度下降(Batch Gradient Descent,BGD)是每次都用训练数据集中所有的样本去计算梯度,而随机梯度下降(Stochastic Gradient Descent,SGD)则每次都用一个样本去计算梯度,而小批量梯度下降(Mini Batch Gradient Descent,MBGD)则介于二者之间,是深度学习中通常采用的做法。
批量梯度下降的缺点是,在训练深层神经网络时,训练数据集的规模一般比较大,如果每次迭代都计算整个训练集上的梯度,这需要消耗非常大的计算资源。此外,大规模训练集中的数据通常比较冗余,也没有必要使用整个训练集计算梯度。
随机梯度下降的缺点是,噪音比较多,更新过于频繁,会造成损失函数的严重震荡;而且并不是每次迭代都向着整体最优方向迈进,虽然训练速度快,但是准确性下降,并不是全局最优。
那么小批量梯度下降的做法是,令f(x, θ)表示一个深层神经网络,θ为网络参数,在使用小批量梯度下降进行优化时,每次选取K个训练样本{(x1, y1), (x2, y2), ..., (xK, yK)}。则第t次迭代时损失函数关于参数θ的偏导数为:
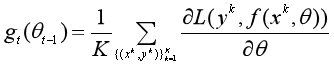
其中L(•)是可微分的损失函数,K称为批量大小(batch size)。则按照如下公式来更新梯度:
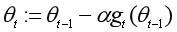
为了更有效地训练深层神经网络,在标准的小批量梯度下降方法的基础上,可以从以下两个方面进行改进:学习率衰减和梯度方向优化。这两种改进优化方法也同样可以用于批量梯度下降算法和随机梯度下降算法上。
但是小批量梯度下降也有两个比较突出的问题:
1、 对所有的参数更新使用同样的学习率
对于稀疏数据或者特征,有时我们可能想对出现频率低的特征更新快一些,对于常出现的特征更新慢一些。
2、不能保证很好的收敛性
学习率如果选择太大,收敛速度会很慢,而如果太大,损失函数会在极小值处震荡或偏离。对于非凸函数,还可能陷入局部极小值或者鞍点处。
二、学习率衰减
从梯度下降算法的经验上看,学习率在一开始要保持比较大些来保证收敛速度,在收敛到最小点附近要小点以避免来回震荡。因此,比较直接的学习率调整可以通过学习率衰减的方式来实现。
而学习率衰减又分为:
(1)固定衰减率的调整学习率方法:逆时衰减、指数衰减、自然指数衰减。
(2)自适应地调整学习率的方法:AdaGrad、RMSprop,AdaDelta。
1、固定衰减率的学习率调整方法
假设初始化学习率为α0,在第t次迭代时的学习率为αt,固定衰减率的方法设置为按迭代次数衰减。
比如逆时衰减:

指数衰减:
![]()
自然指数衰减:
![]()
其中β为衰减率,一般取值为0.96。
2、自适应调整学习率的方法
在标准的梯度下降方法中,每个参数在每次迭代时都使用相同的学习率。而自适应调整学习率的方法是根据不同参数的收敛情况分别设置学习率,因为每个参数的的维度上收敛速度都不相同。
(1)AdaGrad算法
AdaGrad(Adaptive Gradient)算法是借鉴L2正则化的思想,每次迭代时自适应地调整每个参数的学习率。在第t次迭代时,先计算每个参数梯度平方的累计值:
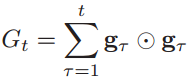
gΤ表示第Τ次迭代时的梯度,梯度平方是按元素进行乘积。AdaGrad算法的参数更新值为:
![]()
其中α为初始的学习率,ε是为保持数值稳定而设置的非常小的常数。在AdaGrad算法中,如果某个参数的偏导数累计非常大,其学习率相对比较小;相反则比较大;但整体上随着迭代次数增加,学习率逐渐缩小。
(2)RMSprop算法
RMSprop(Root Mean Square prop )算法可以在某些情况下避免AdaGrad算法中学习率不断单调下降以至于过早衰减的缺点。
RMSprop算法首先计算每次迭代梯度gt平方的指数衰减移动平均:
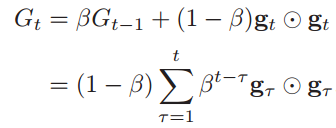
其中β为衰减率,一般取值为0.9。RMSprop算法的参数更新差值为:
![]()
RMSprop算法和AdaGrad算法的区别在于Gt的计算由累积的方式变成了指数衰减移动平均。在迭代中,每个参数的学习率不是呈衰减趋势,而是可以变小也可以变大。
(3)AdaDelta算法
AdaDelta算法也是AdaGrad算法的一个改进。和RMSprop算法类似,AdaDelta算法通过梯度平方的指数衰减移动平均来调整学习率,而它的创新在于引入了每次参数更新之差Δθ的平方的指数衰减权移动平均。
在第t次迭代时,首先计算一个参数更新差Δθt的指数衰减权移动平均:
![]()
则AdaDelta算法的参数更新差为:
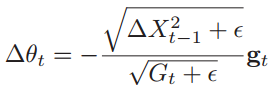
其中Gt的计算方法和RMSprop算法一样,ΔX2t-1是参数更新差Δθt的指数衰减权移动平均。
AdaDelta算法将RMSprop算法中的初始学习率α改为了动态计算的![]() ,在一定程度上平抑了学习率的波动。
,在一定程度上平抑了学习率的波动。
三、梯度方向优化
除了调整学习率之外,还可以通过使用最近几轮迭代的平均梯度来替代当前时刻的梯度,来作为当前参数更新的方向。在小批量梯度下降中,如果每次选取样本的数量比较小,那么损失会呈现震荡下降的形态。有效缓解梯度下降中震荡的方式是通过用梯度的移动平均来代替每次的实际梯度,并提高优化速度,这就是动量法。
1、动量法
在物理中,一个物体的动量是指这个物体在它运动方向上保持运动的趋势,是物体的质量和速度的乘积。动量法(Momentum Method)是用之前积累动量来代替真正的梯度,每次迭代的梯度可以看做是加速度。
动量法在第 t次迭代时,计算负梯度的加权移动平均作为参数的更新方向:
![]()
其中ρ为动量因子,通常设为0.9,α是学习率。
这样,每个参数的实际更新差值取决于最近一段时间内梯度的加权平均值。当某个参数在最近一段时间内的梯度方向不一致时,其真实的参数更新幅度变小;相反,当在最近一段时间内的梯度方向都一致时,其真实的参数更新幅度变大,起到加速作用。一般而言,在迭代初期,梯度方法都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方法会不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性 。
2、Nesterov加速梯度
Nesterov加速梯度(Nesterov Accelerated Gradient,NAG),是一种对动量法的改进。在动量法中,实际的参数更新方向Δθt为上一步的参数更新方向Δθt-1和当前的梯度-gt的叠加。而NAG的改进在于,把当前的梯度-gt(θt-1),修正为损失函数在(θt-1+ρΔθt-1)上的负梯度:-gt(θt-1+ρΔθt-1)。
则参数更新的方向为:
![]()
3、Adam算法
Adam算法(Adaptive Moment Estimation,自适应动量估计)可以看作是动量法和 RMSprop 的结合,不但使用动量作为参数更新方向,而且可以自适应地调整学习率。
Adam 算法一方面计算梯度平方 gt2的指数加权平均(和 RMSprop 类似),用于自适应地调整学习率,另一方面计算梯度gt的指数加权平均(与动量法类似),作为参数调整方向。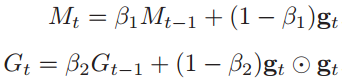
其中β1 和β2 分别为两个移动平均的衰减率,通常取值为β1 = 0.9, β2 = 0.99 。
Mt可以看作是梯度的均值(一阶矩), Gt可以看作是梯度的未减去均值的方差,假设M0= 0, G0= 0,那么在迭代初期Mt和Gt 的值会比真实的均值和方差要小。特别是当β1 和β2 都接近于1时,偏差会很大。因此,需要对偏差进行修正。
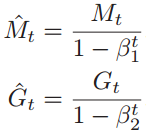
Adam算法的参数更新值为:

其中学习率α通常设为0.001,并且也可以按照迭代次数t进行衰减,比如:
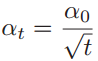
4、梯度截断法
在深层神经网络中,除了梯度消失外,梯度爆炸是影响学习效率的主要因素。在基于梯度下降的优化过程中,如果梯度突然增大,用非常大的梯度进行参数更新,反而会导致其远离最优点。
为了避免这种情况,当梯度大于一定阈值时,就对梯度进行截断,称为梯度截断(gradient clipping)。
梯度截断具体的做法就是,把梯度的模限定在一个区间内,当梯度的模小于或者大于这个区间时就进行截断。一般截断的方式有两种:
(1)按值截断
在第t次迭代时,梯度为gt,给定一个区间[a,b],如果一个参数的梯度小于a时,就将其设为a;如果大于b时,就将其设为b。
![]()
(2)按模截断
按模截断是将梯度的模截断到一个给定的截断阈值b。

截断阈值 b 是一个超参数,也可以根据一段时间内的平均梯度来自动调整 。
四、如何选择合适的优化算法
如果数据是稀疏的,在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法,即 AdaDrad, AdaDelta, RMSprop, Adam。
RMSprop, AdaDelta, Adam 在很多情况下的效果是相似的,Adam 就是在 RMSprop 的基础上加了动量法,随着梯度变得稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
五、总结
优化方法大体上可以分为两类:一是调整学习率,使得优化更稳定;二是调整梯度方向,优化训练速度。常见的优化算法整理如下:

参考资料:
1、邱锡鹏:《神经网络与深度学习》
2、https://www.cnblogs.com/guoyaohua/p/8542554.html