OO第一单元作业小结
总体思路
因为java正则表达式在实现时利用的NFA(不确定有穷自动机),而NFA会占用大量的计算能力,稍有不慎就会爆栈(特别是遇到".*")。所以本单元作业舍弃了使用java自带的正则表达式,而是利用编译原理的设计思想,手动写DFA(确定有穷自动机)。但是,在使用编译原理的设计思想:自顶向下分析时,要注意消除左递归。因此,我每次作业都改写了文法,使之能够使用DFA。StringParser类通过解析字符串,逐步产生各种各样的Poly,Term,Factor对象,达到将字符串转化为一个表达式结构的目的。
第一次作业
1 基于度量分析自己程序结构
(1)uml类图
(2)MetricsReloaded
在分析结果中可以看到ev, iv, v这几栏,分别代指基本复杂度(Essential Complexity (ev(G))、模块设计复杂度(Module Design Complexity (iv(G)))、Cyclomatic Complexity (v(G))圈复杂度。
ev(G)基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
Iv(G)模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。

2 自己程序的Bug
未发现bug
3 发现别人程序的Bug采用的策略
(1)通过正则表达式生成随机字符串
测试数据生成器为使用Python语言编写的dataMaker.py,通过导入的exrex包,就可以随机生成符合某正则表达式的字符串。
具体使用方法为:
import exrex
dataString = exrexx.getone(rexString)
(2)使用被测试程序计算输出结果
在bat脚本中写入以下语句:
type input.txt | java -classpath %class_path% MainClass > output.txt
(3)使用sympy计算正确求导结果
(4)使用sympy带入值计算正确求导结果和被测试程序输出结果
(5)比较正确值和输出值
在bat脚本中写入以下语句:
fc correct.txt myOutput.txt
第二次作业
1 基于度量分析自己程序结构
(1)uml类图
(2)MetricsReloaded
StringParser类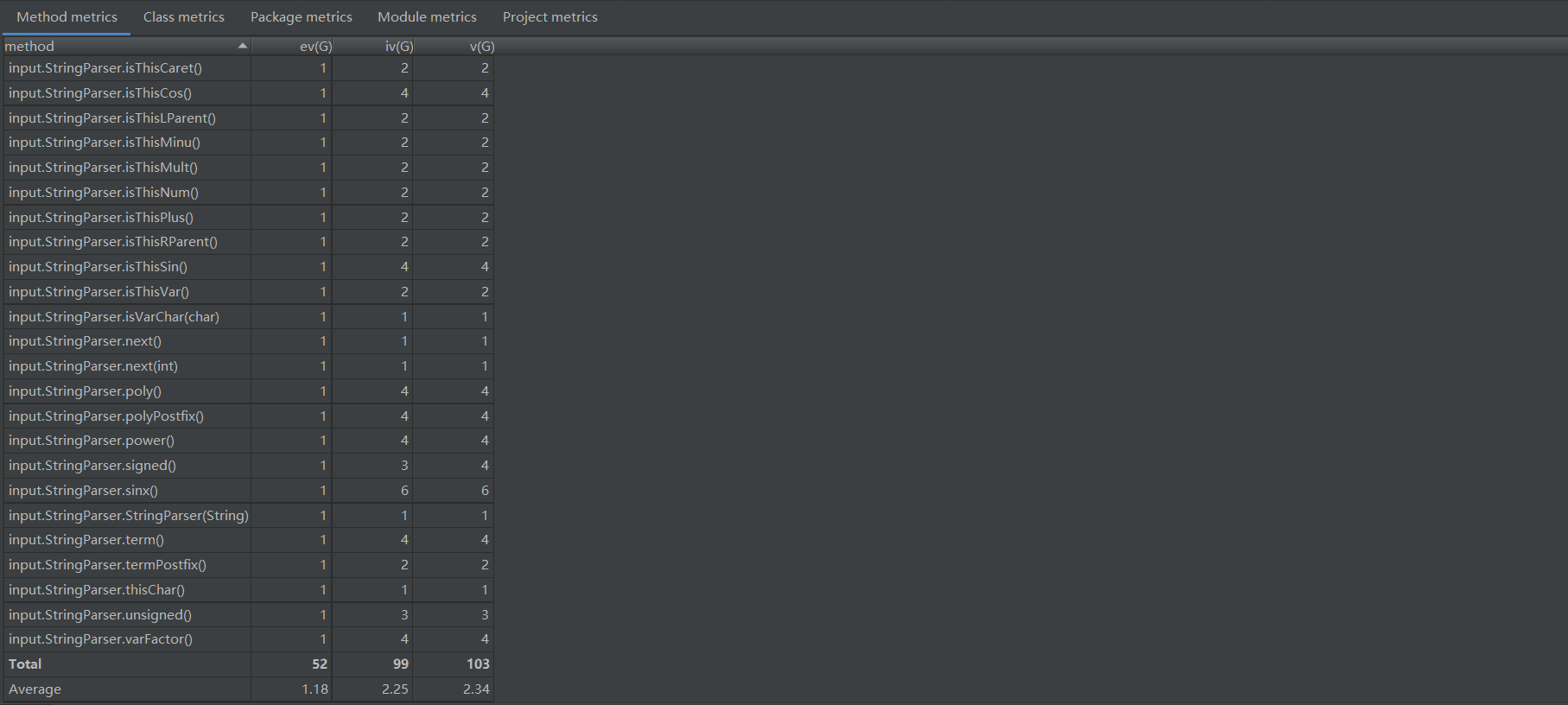
Poly类
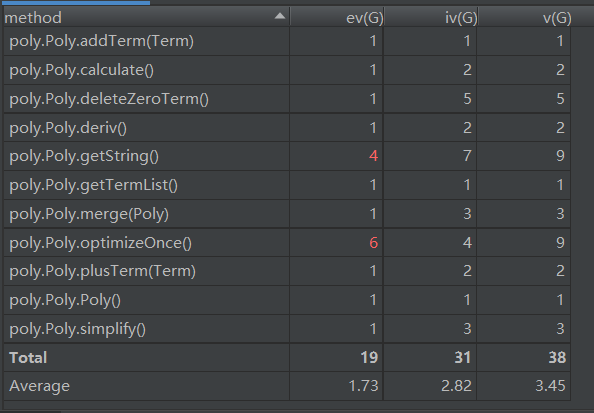
Term类
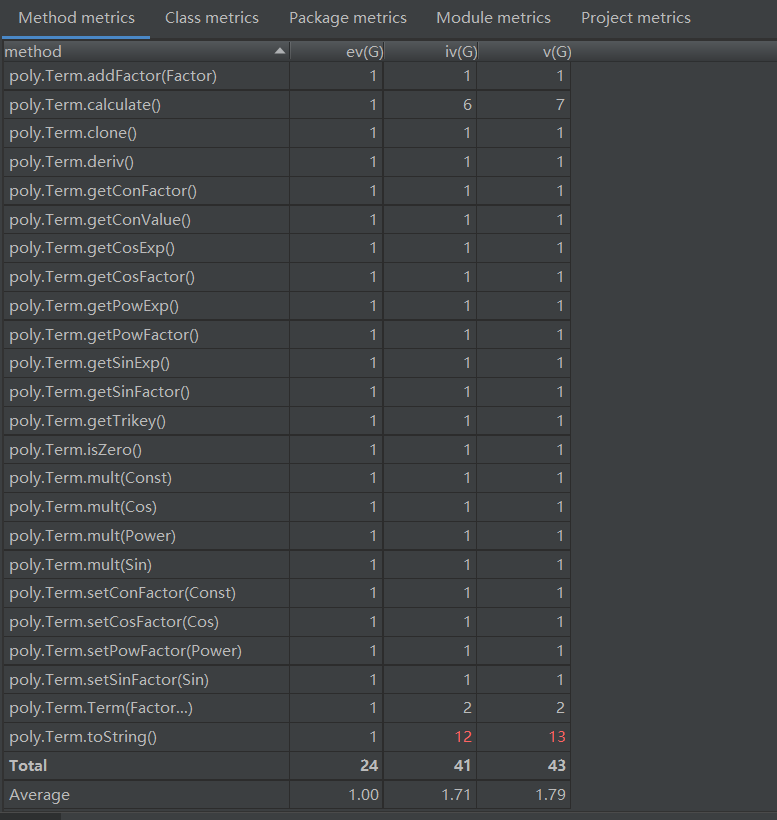
由此可见,代码的复杂度主要出现在优化和转化字符串方面。其实,可以单独为优化和字符串转化单独建立一个类,这样可以减少这个类的复杂度。
2 自己程序的Bug
bug在于在进行优化时,由于采取的是四元组的存储方式,hashmap的存储结构。以a*x^b*sin(x)^c*cos(x)^d中的系数<a,b,c,d>为四元组,<b,c,d>三元组为键值。在合并某两项时,直接把这两项从hashmap中删去即可,但是他们的和不能直接放入hashmap中,而是要先判断是否已有和的键值,如果有就必须将已有的项与这个和相加再放入hashmap中。我没有判断直接放进去了,导致了bug。
3 发现别人程序的Bug采用的策略
自动化测试与上次一致
第三次作业
1 基于度量分析自己程序结构
(1)uml类图
(2)MetricsReloaded
StringParser类

Poly类
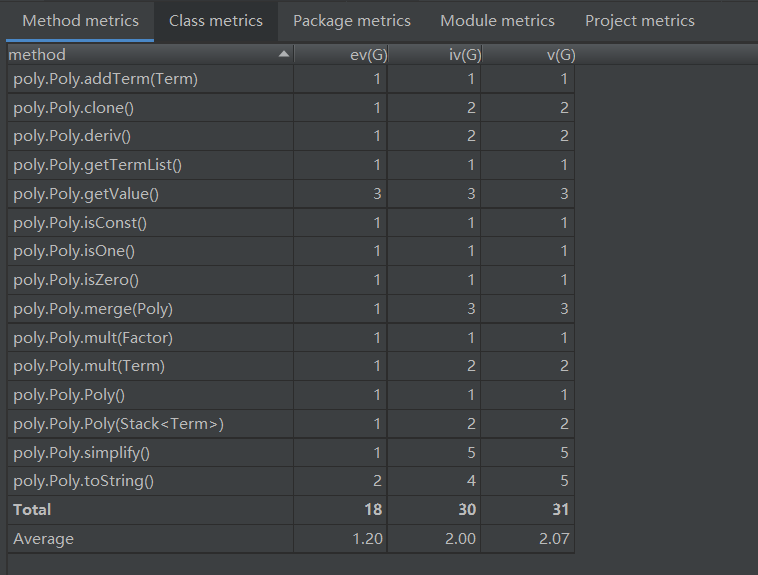
Term类
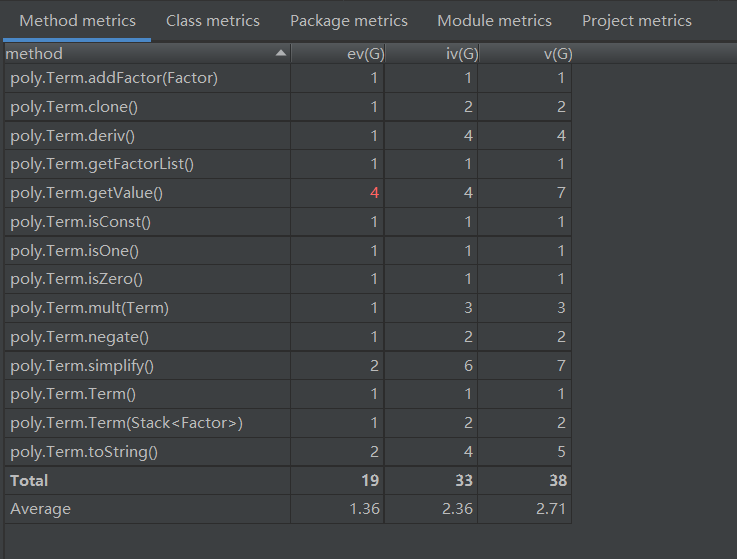
2 自己程序的Bug
自己程序的bug在于误认为在执行了某个方法后,已经不会出现空的项(也就是不含任何因子),但实际上没有完全消除。
3 发现别人程序的Bug采用的策略
(1)自动化测试与上次一致
(2)针对边界数据手动写测试样例
(2)加上对被测试代码的观察,针对性hack
应用对象创建模式来重构
如果重构,会使用工厂模式来实现生成对象的逻辑与字符串解析的逻辑相分离。
心得体会
经过了第一单元的三次作业的磨练,我明白了一个可扩展性的设计是非常重要的。第一次作业时,没有想到要为以后进行迭代,增加设计,所以程序写的比较过程化,不利于扩展。因此,第二次作业不得不重构,这样大大浪费了时间。第二次作业就比较注意结构化设计了,注重程序的高内聚低耦合。因此第三次作业在直接可以在第二次作业的基础上进行改进而无需重构。
关于工厂模式
在我看来,工厂模式是面向对象的设计方法里比较能体现出OO特性的设计模式了。因为工厂模式会使得代码更加模块化,各司其职,每个模块都无需关心其他模块是如何工作的,只需利用其接口就可以很好的完成任务。这能使代码具有高内聚、低耦合的特性。关于在课上提出的如果工厂类的构造函数的参数不定数目,不定类型时,我觉得可以将所有参数转化为一个字符串,通过对传入的字符串进行解析即可。