可以用 pandas 来读写excel文件。
示例如下
import pandas as pd from pandas import DataFrame #例如在桌面上有一个 "test.xlsx" 文件,现在将它导入到data中 data=pd.read_excel(r'c:UsersLiugengxinDesktop est.xlsx') # r 表示路径 #或者 path=r'c:UsersLiugengxinDesktop est.xlsx' data=pd.read_excel(path) print(data) #输出data #到这里 就可以成功将test文件导入到data中了
运行结果与test文件中的一样。

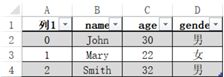
接下来可以对test文件进行写操作。
#接着上面6行代码往下写 #把gender中的'男'用'0'替换女用'1'替换 data['gender'][data['gender']=='男']='0' data['gender'][data['gender']=='女']='1' DataFram(data).to_excel(r'c:UsersLiugengxinDesktop est_end.xlsx') #这里我们把它写到一个test_end文件中 这个文件不需要先前就存在,如果不存在 程序会自动创建
程序运行后就能在桌面上发现一个test_end.xlsx文件 打开可以发现文件的内容正是我们预期的

也可以用xld包的方法来读取文件
path = r'c:UsersLiugengxinDesktop est.xlsx' def xlrd_read_data(path): table = xlrd.open_workbook(path).sheets()[0] #这样数据就读到table中了,若要转成矩阵还要逐行读取 row = table.nrows # 行数 col = table.ncols # 列数 datamatrix = np.zeros((row, col))#生成一个nrows行ncols列,且元素均为0的初始矩阵 for x in range(col): cols = np.matrix(table.col_values(x)) # 把list转换为矩阵进行矩阵操作 datamatrix[:, x] = cols # 按列把数据存进矩阵中 return datamatrix
也可以直接用open方法打开一个txt文件读取每一行,将每一行的单词用空格隔开添加到list列表中,可以用来处理离散型数据。
import string f = open(r"C:UsersLiugengxinDesktop1.txt") lines = f.readlines()#读取全部内容 for i in range(0,lines.__len__(),1): #(开始/左边界, 结束/右边界, 步长) list = [] ## 空列表, 将第i行数据存入list中 for word in lines[i].split(): word=word.strip(string.whitespace) #以空格为分隔符 list.append(word); print(list)
运行结果与文件中的一样
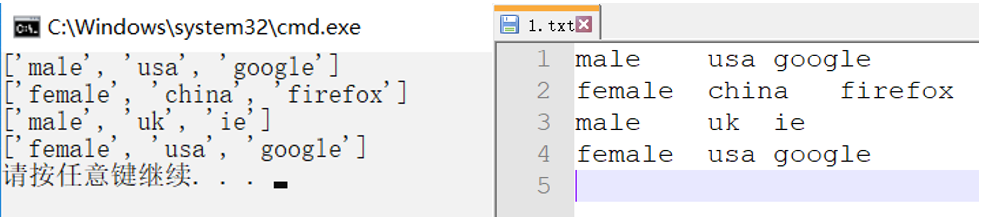
我们还可以修改一下代码把每个小list加到一个大List后面,如下可以写成一个函数List_Train就是一个大列表。(但是不能转成二维的)
def Data_To_List(path): f=open(path) lines=f.readlines() List=[] for i in range(0,lines.__len__(),1): list=[] for word in lines[i].split(): word=word.strip(string.whitespace) list.append(word) List.append(list) return List List_Train=Data_To_List(r"C:UsersLiugengxinDesktop课程数据科学大作业离散数据.txt") print(List_Train)
运行结果
