后面会介绍gcc获得源文件依赖的方法,gcc这个功能就是为make而存在的。我们采用gcc的-MM选项结合sed命令。使用sed进行替换的目的是为了在目标名前加上“objs/”前缀。gcc的-E选项,预处理。在生成依赖关系时,其实并不需要gcc编译源文件,只要预处理就可以获得依赖关系了。通过-E选项,可以避免生成依赖关系时gcc发出警告,以及提高依赖关系的生成效率。
现在,已经找到自动生成依赖关系的方法了,那么如何将其整合到我们complicated项目的Makefile中呢?自动生成的依赖信息不能直接出现在Makefile中,因为不能动态地改变Makefile中的内容,此时我们需要通过创建依赖关系文件的方式。假设依赖关系的文件以“.dep”结尾,因此我们新创建一个deps文件,用来存放依赖关系文件信息。
Makefile如下:
.PHONY: all clean MKDIR = mkdir RM = rm RMFLAGS = -rf CC=gcc DIR_OBJS=objs DIR_EXES=exes DIR_DEPS=deps DIRS =$(DIR_OBJS) $(DIR_EXES) $(DIR_DEPS) EXE=complicated EXE:=$(addprefix $(DIR_EXES)/,$(EXE)) SRCS=$(wildcard *.c) OBJS=$(SRCS:.c=.o) OBJS:=$(addprefix $(DIR_OBJS)/,$(OBJS)) DEPS=$(SRCS:.c=.dep) DEPS:=$(addprefix $(DIR_DEPS)/,$(DEPS)) all:$(DIRS) $(DEPS) $(EXE) $(DIRS): $(MKDIR) $@ $(EXE):$(OBJS) $(CC) -o $@ $^ $(DIR_OBJS)/%.o:%.c $(CC) -o $@ -c $^ $(DIR_DEPS)/%.dep:%.c @echo "Creating $@ ..." @set -e; $(RM) $(RMFLAGS) $@.tmp; $(CC) -E -MM $^ >$@.tmp; sed 's,(.*).o[:]*,objs/1.o:,g' <$@.tmp >$@; $(RM) $(RMFLAGS) $@.tmp clean: $(RM) $(RMFLAGS) $(DIRS)
(这个Makefile废了不少力气才想明白。。。)
和之前的complicated项目的Makefile相比:
1,增加了deps文件夹。
2,删除了目标文件创建规则中的foo.h依赖,并将规则中的自动变量从$<变回了$^。
3,增加了DEPS变量用于存放依赖文件。
4,为all目标增加了对 $(DEPS) 的依赖。
5,增加了一个用于创建依赖关系文件的规则。在这个规则中,使用了gcc的-E和-MM选项来获取依赖关系。在生成最终的依赖关系文件之前,使用了一个由$@.tmp表示的临时文件,且在依赖文件生成以后将其删除。“set -e” 的作用是告诉shell,在生成依赖关系文件的过程中如果出现任何错误就直接退出。shell异常退出的最终表现就是make会告诉我们出错了,从而停止后续的make工作。如果不设置这一行,当构建依赖出错时,make还会继续后面的工作(并最终出错),这并不是我们希望看到的。读者可以测试故意在源文件或者头文件中植入错误并去掉 “set -e” 选项观察make的行为和加上set -e有何不同。
这里还有几个知识点需要补充。
1.对于规则中的每一条命令,make都是在一个新的shell上运行它的。
2.如果希望多个命令在同一个shell中运行,可以用“;”将这些命令连起来。
3.当命令很长时,可以用“”将一个命令书写成多行。
为了更好的理解第一点,我们做一个实验。现假设需要创建一个test目录,然后在这个test目录下再创建一个subtest子目录。编写Makefile如下:
.PHONY:all
all:
@mkdir test
@cd test
@mkdir subtest

可以看到test和subtest是同级目录并非父子目录,然后用上面提到的知识点更改Makefile:
.PHONY:all
all:
@mkdir test;
cd test;
mkdir subtest

这样就可以达到目的了。不过你可能会想,为什么这里后面的cd和最后一个mkdir不需要在前面加上@呢?那么我们加上试试呢?
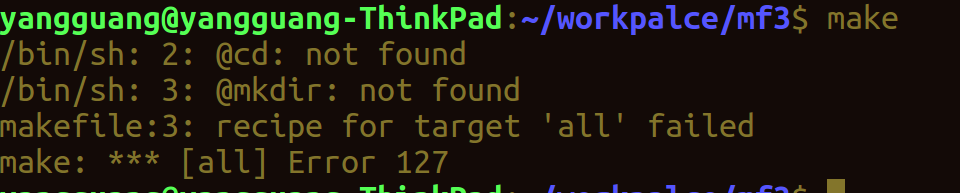
如果使用了分号“ ;”,表示命令在同一个shell中运行,而且使用“ ”链接一条命令,既然是一条命令,自然不能够识别后面的@cd或者@mkdir,因为最开始的mkdir使用@,让终端不显示执行的指令,后面的cd和mkdir是在前面操作的情况下进行的 ,此时,直接使用命令即可。
还有一个需要注意的地方:
如同
sed 's,(.*).o[:]*,objs/1.o:,g' <$@.tmp >$@;
3.命令与选项
sed命令告诉sed如何处理由地址指定的各输入行,如果没有指定地址则处理所有的输入行。
此处sed引用此博客, 参考链接:http://www.cnblogs.com/edwardlost/archive/2010/09/17/1829145.html
3.1 sed命令
| 命令 | 功能 |
| a |
在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“”续行 |
| c | 用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用""续行 |
| i | 在当前行之前插入文本。多行时除最后一行外,每行末尾需用""续行 |
| d | 删除行 |
| h | 把模式空间里的内容复制到暂存缓冲区 |
| H | 把模式空间里的内容追加到暂存缓冲区 |
| g | 把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容 |
| G | 把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面 |
| l | 列出非打印字符 |
| p | 打印行 |
| n | 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理 |
| q | 结束或退出sed |
| r | 从文件中读取输入行 |
| ! | 对所选行以外的所有行应用命令 |
| s | 用一个字符串替换另一个 |
| g | 在行内进行全局替换 |
| w | 将所选的行写入文件 |
| x | 交换暂存缓冲区与模式空间的内容 |
| y | 将字符替换为另一字符(不能对正则表达式使用y命令) |
3.2 sed选项
| 选项 | 功能 |
| -e | 进行多项编辑,即对输入行应用多条sed命令时使用 |
| -n | 取消默认的输出 |
| -f | 指定sed脚本的文件名 |
4.退出状态
5.正则表达式元字符
| 元字符 | 功能 | 示例 |
| ^ | 行首定位符 | /^my/ 匹配所有以my开头的行 |
| $ | 行尾定位符 | /my$/ 匹配所有以my结尾的行 |
| . | 匹配除换行符以外的单个字符 | /m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行 |
| * | 匹配零个或多个前导字符 | /my*/ 匹配包含字母m,后跟零个或多个y字母的行 |
| [] | 匹配指定字符组内的任一字符 | /[Mm]y/ 匹配包含My或my的行 |
| [^] | 匹配不在指定字符组内的任一字符 | /[^Mm]y/ 匹配包含y,但y之前的那个字符不是M或m的行 |
| .... | 保存已匹配的字符 | 1,20s/youyouself/1r/ 标记元字符之间的模式,并将其保存为标签1,之后可以使用1来引用它。最多可以定义9个标签,从左边开始编号,最左边的是第一个。此例中,对第1到第20行进行处理,you被保存为标签1,如果发现youself,则替换为your。 |
| & | 保存查找串以便在替换串中引用 | s/my/**&**/ 符号&代表查找串。my将被替换为**my** |
| < | 词首定位符 | /<my/ 匹配包含以my开头的单词的行 |
| > | 词尾定位符 | /my>/ 匹配包含以my结尾的单词的行 |
| x{m} | 连续m个x | /9{5}/ 匹配包含连续5个9的行 |
| x{m,} | 至少m个x | /9{5,}/ 匹配包含至少连续5个9的行 |
| x{m,n} | 至少m个,但不超过n个x | /9{5,7}/ 匹配包含连续5到7个9的行 |
1.并不是只有 / 可作为模式分割符,很多符合如 , ; 都可以,尤其是模式中有 / 时使用其他分割符更方便,这里这个复杂例子使用逗号,做模式分隔符;
sed 's,(.*).o[:]*,objs/1.o:,g' <$@.tmp >$@;
现在来分解这个复杂表达式,首先,sed s表示我们想用一个字符串替换另一个字符串,这也是我们使用sed的原因,它的s命令就
可以达到这个效果。
's,(.*).o[:]*,objs/1.o:,g'第一次分解,此时需要知道,单引号是一对的,即s前面的'和g后面的'是一个整体单引号,
这也是sed命令的基础,至于单引号和双引号有什么区别,可百度谷歌或者必应。(但是我之前测试的单引号和双引号并不是我搜索所显示的那样,后面再试试吧)
继续分解,s,中s是替换字符串的意思,这个在上面的表格中可以查询到,逗号,表示模式分隔符,在这种有/出现的字符串中,我们选择了逗号,作为分隔符号。
所以下一次分解应该倒下一个逗号处,
(.*).o[:]*,
这里首先看 .* 它表示匹配任意字符,( )是一个整体,也是通过上面的表格得到的,然后转义字符和.o在一起,把.的作用(匹配除换行符的单个字符)变成普通的.(就是一个字符.),那么这一句话就是
操作字符串所有有.o的且在.0后面(可以有空格)匹配:的零个或多个字符串。
objs/1.o:,g
这里要解释的是1.o 这里用了转义字符加上1,这表示什么呢?尤其是这个1,表示的就是前面第一个字符串,这是组
的概念,如何知道是第几组呢?前面第一个用( )这个括起来的就是第一组,用转义字符1表示,依次类推。g在sed中表示行内全局替换
这样,我们做一个假设例子来说明。
abc.o : 用这个代表(.*).o[:]*
然后objs/1.o:,g之后呢,abc.o :变成了 objs/abc.o: 这里相当于给前面的通用匹配加上了objs/前缀,并且把:和.o之前的空格去掉了
最后这个<$@.tmp >$@;这不属于sed的内容了,属于linux和Makefile的东西,$@.tmp重定向输入给前面的sed替换操作,
$@代表目标在Makefile中,$@.tmp是前面的Makefile生成的,<重定向,看方向是输入,
就是把$@.tmp重定向输入给sed,经过sed替换之后,再输出重定向 > 到$@,这个是目标。
这样再回过头去看之前那个Makefile就可以看懂了。