Types of CQRS
By Vladimir Khorikov
CQRS is a pretty defined concept. Often, people say that you either follow CQRS or not, meaning that it is some kind of a binary choice. In this article, I’d like to show that there is some wriggle room in this notion and how different types of CQRS can look like.
Type 0: no CQRS
With this type, you don’t have any CQRS whatsoever. That means you have a domain model and you use your domain classes for both serving commands and executing queries.
Let’s say you have a Customer class:
public class Customer
{
public int Id { get; private set; }
public string Name { get; private set; }
public IReadOnlyList<Order> Orders { get; private set; }
public void AddOrder(Order order)
{
/* … */
}
/* Other methods */
}
With the type 0 of CQRS you end up with CustomerRepository class looking like this:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<Customer> Search(string name) { /* … */ }
}
Search method here is a query. It is used for fetching customers’ data from database and returning it to a client (a UI layer or a separate application accessing your server through some API). Note that this method returns a list of domain objects.
The advantage of such approach is obvious: it has no code overhead. In other words, you have a single model that you use for both commands and queries and don’t have to duplicate the code at all.
The disadvantage here is that this single model is not optimized for read operations. If you need to show a list of customers in UI, you usually don’t want to display their orders. Instead, you most likely prefer to show only a brief information such as id, name and the number of orders.
The use of a domain class for transferring customers’ data from the database to UI leads to loading all their orders into memory and thus introduces a heavy overhead because UI needs the order count field only, not the orders themselves.
This type of CQRS is good for small applications with little or no performance requirements. For other types of applications, we need to move further.
Type 1: separated class structure
With this type of CQRS, you have your class structure separated for read and write operations. That means you create a set of DTOs to transfer the data you fetch from the database.
The DTO for Customer can look like this:
public class CustomerDto
{
public int Id { get; set; }
public string Name { get; set; }
public int OrderCount { get; set; }
}
The Search method now returns a list of DTOs instead of a list of domain objects:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<CustomerDto> Search(string name) { /* … */ }
}
The Search method can use either an ORM or plain ADO.NET to get the data needed. This should be determined by performance requirements in each particular case. There’s no need to fall back to ADO.NET if a method’s performance is good enough.
DTOs introduce some duplication as we need to come up with the same concept twice: once for commands in a form of a domain class and once more for queries in a form of a DTO. But at the same time, they allow us to create clean and explicit data structures that perfectly align with our needs for read operations as they only contain data clients need to display. And the more explicit we are with our code, the better.
I would say that this type of CQRS is sufficient for most of enterprise applications as it gives a pretty good balance between code complexity and performance. Also, with this approach, we have some flexibility in terms of what tool to use for queries. If the performance of a method is not critical, we can use ORM and save developers’ time; otherwise, we may fall back to ADO.NET (or some lightweight ORM like Dapper) and write complex and optimized queries on our own.
If we want to continue separating our read and write models, we need to move further.
Type 2: separated model
This type of CQRS proposes using separated models and sets of API for serving read and write requests.
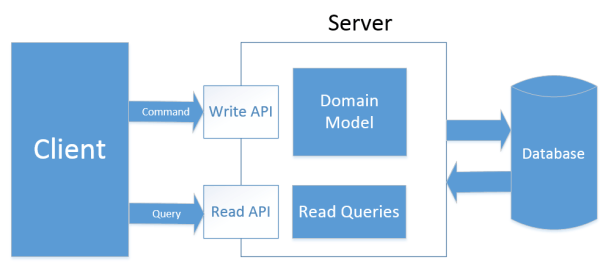
Type 2 of CQRS
That means that, in addition to DTOs, we extract all the read logic out of our model. Repository now contains only methods that regard to commands:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
}
And the search logic resides in a separate class:
public class SearchCustomerQueryHandler
{
public IReadOnlyList<CustomerDto> Execute(SearchCustomerQuery query)
{
/* … */
}
}
This approach introduces more overhead comparing to the previous one in terms of code required to handle the complexity, but it is a good solution if you have a heavy read workload.
In addition to the ability to write optimized queries, type 2 of CQRS allows us to easily wrap read portion of API with some caching mechanism or even move read API to another server and setup a load-balancer/failover cluster. It works great if you have a massive disparity between the workload of writes and reads in your system as it allows you to scale the read part of it drastically.
If you need even more performance of read operations, you need to move to type 3 of CQRS.
Type 3: separated storage
That is the type that considered to be the true CQRS by many. To scale read operations even further, we can create a separate data storage optimized specifically for queries we have in our system. Often, such storage might be a NoSQL database like MongoDB or a replica set with several instances of it:

Type 3 of CQRS
The synchronization goes in background mode and can take some time. Such data storages are considered to be eventually consistent.
A good example here could be indexing of customers’ data with Elastic Search. Often we don’t want to use full-text search capabilities built into SQL Server as they don’t scale much. Instead, we could use non-relational data storage optimized specifically for searching customers.
Along with the best scalability for read operations, this type of CQRS brings the highest overhead. Not only should we segregate our read and write model logically, i.e. use different classes and even assemblies for it, but we also need to introduce database-level separation.
Summary
There are different types of CQRS you can leverage in your software; there’s nothing wrong with sticking to the type #1 and not moving further to the types 2 or 3 as long as the type #1 meets your application’s requirements.
I’d like to emphasize this once more: CQRS is not a binary choice. There are some different variations between not separating reads and writes at all (type 0) and separating them completely (type 3).
There should be a balance between the degree of segregation and complexity overhead it introduces. The balance itself should be found in each concrete software application apart, often after several iterations. I strongly believe that CQRS itself should not be implemented “just because we can”; it should only be brought to the table to meet concrete requirements, namely, to scale read operations of the application.
http://enterprisecraftsmanship.com/2015/04/20/types-of-cqrs/