事务:事务是包含一组数据库操作的逻辑工作单元,用于保证数据的一致性和可恢复性。
事务的分类:
1.自动提交事务:在sqlserver中,每条sql语句都被看作是一个事务,当执行完成后,数据库引擎都会自动执行提交事务或回滚事务。
2.显示事务:使用begin transaction语句标识事务的开始,使用commit或rollback语句标识事务的结束。
3.隐式事务
4.批处理级事务
事务保存点 save transaction 语句
保存点定义了事务中的一个位置,可以在rollback的时候讲数据回滚到保存点的位置,从而实现部分回滚事务的功能,避免不必要的系统资源损耗。
例:
begin transaction test save transaction a insert into shop values('111'); rollback transaction a insert into shop values('222'); commit transaction test
嵌套事务
sqlserver支持嵌套事务
事务的隔离级别
read uncommitted:指定语句可以读取已由其他事物修改但尚未提交的行,在这种事务隔离级别下,语句可以读取到未提交的修改,这种读取叫做脏读,是限制最少的级别。
read committed:指定语句不能读取其他事物正在修改但尚未提交的行,这可以避免脏读,sqlserver的默认选项。
repeatable read:指定语句不能读取其他事物正在修改但尚未提交的行,而且其他事物也不能修改当前事务在提交前所读取的数据。
snapshot:指定事务在开始时,就获得了已经提交数据的快照,因此当前事务只能看到在事务开始之前对数据所做的修改。
serializable:提供最高级别的事务隔离。当事务处在这个级别时,一个查询只能看到事务开始之前提交的数据,而无法看到脏数据或事务执行中其他并行事务所修改的数据。在此级别下,事务就好像被一个一个地串行执行,而不是并发执行多个事务。
set transaction isolation level { read uncommitted | read committed | repeatable read | snapshot | serializable }
锁的分类
按系统角度分为:共享锁、独占锁(排他锁)、更新锁、意向锁、架构锁、大容量更新锁。
从并发控制手段上分为:乐观锁、悲观锁。
https://www.cnblogs.com/rasion/archive/2010/03/29/1699600.html
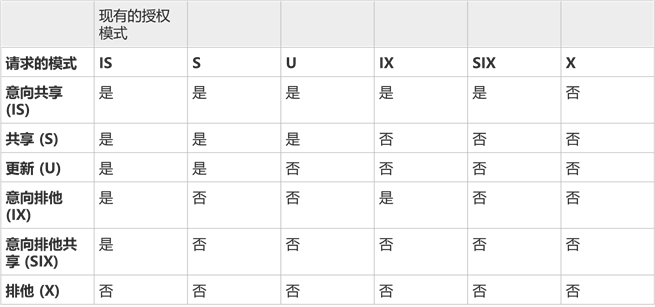
锁的兼容性
锁的粒度和结构层次
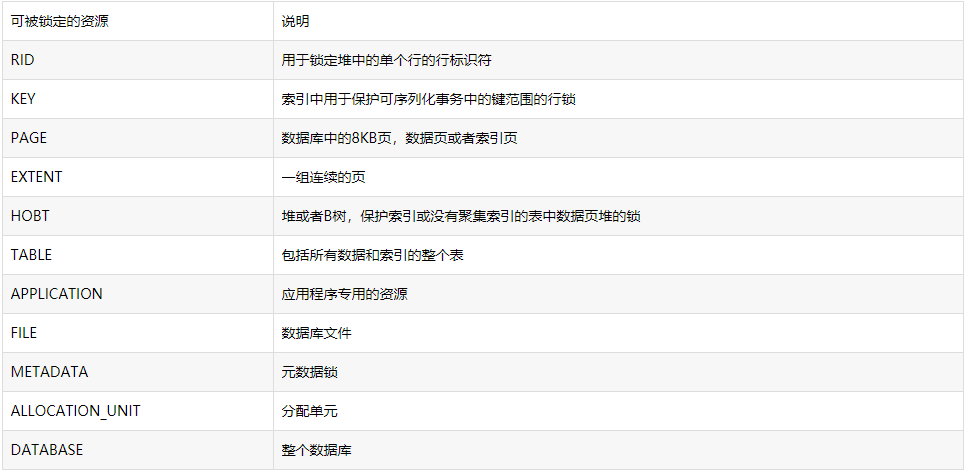
数据库引擎具有多粒度锁定,允许一个事务锁定不同类型的资源。锁定在较小的粒度(例如行)可以提高并发度,但开销大,因为锁定的范围越小,需要的锁就越多(锁定了许多行,就需要持有更多的锁);锁定在较大的粒度(例如表)会降低并发度,但是消耗较低, 因为锁定的范围大,需要的锁就越小(锁定了表,限制了其他事物对表的访问)。
数据库引擎通常必须获取多粒度级别上的锁才能完整地保护资源。这种多粒度级别上的锁称为锁层次结构
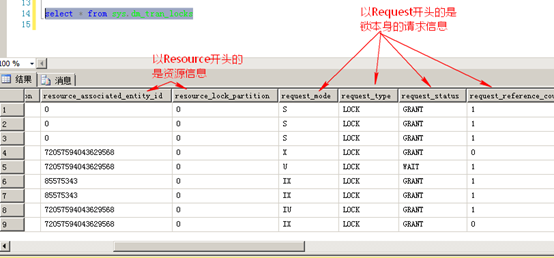
查看锁的活动情况
1.使用sqlserver时间探查器
2.使用windows管理工具->性能 ,系统监视器
3.系统视图:sys.dm_tran_locks
死锁产生的原因以及如何避免
https://www.cnblogs.com/wangweitr/p/7158023.html
参考:《sqlserver性能监测与优化》