一,介绍
flume Apache出的一款日志采集工具,本篇文章将和大家分享交流一下flume的基本功能,架构。使用三个例子来介绍flume的安装配置以及日志采集功能。
学习一项新的技术或者新的工具,离不开它的官网(http://flume.apache.org/)
flume的基础架构
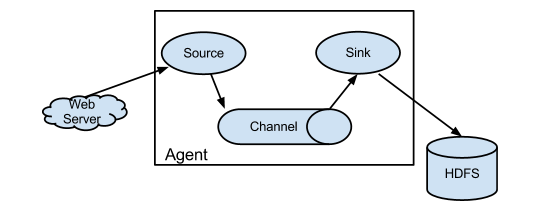
WebServer:代表数据的产生的源头(不仅仅WebServer,其它产生数据的来源均可,可以是一个文件,一个数据库等等),如果把data flow 比喻成水流的话,那么WebServer或者其它产生数据的东东就相当于一个水龙头。
Source:相当于接水的漏斗。
Channel:相当于管道,好吧它就是管道。
Sink:相当于一个分流器,它指定水流向哪里。
Agent:负责把 漏斗(Source),管道(Channel),Sink(分流器)组装起来。
HDFS:代表数据的目的地(可以是HDFS,也可以是一个文件等等存放或者展示数据的东东)。
二,安装
1,下载
flume下载地址:可以是官网下载(http://flume.apache.org/download.html)
我使用的是cdh5 地址:http://archive.cloudera.com/cdh5/cdh/5/

2,安装配置
安装配置flume之前必须保证有jdk环境(jdk8以上)

将jdk, flume的安装包放在你指定的路径下比如我的路径:/usr/local/app
在此路径下分别执行:tar -zxvf jdk-8u161-linux-x64.tar.gz, tar -zxvf flume-ng-1.6.0-cdh5.7.0.tar.gz
将会产生如下文件夹:
jdk1.8.0_161
apache-flume-1.6.0-cdh5.7.0-bin
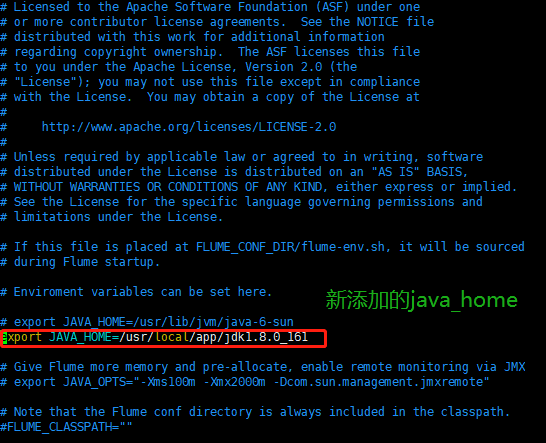
配置flume的flume-env.sh文件
进入flume的conf路径下

执行 cp flume-env.sh.template flume-env.sh

编辑 flume-env.sh 文件 vim flume-env.sh
在此文件中添加你的java home(jdk所在的位置)
配置环境变量(有好几种方法,我使用的是编辑 .bashrc文件)
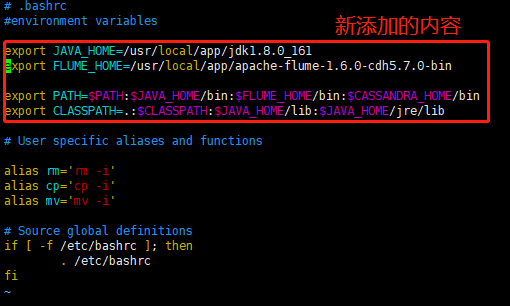
编辑完之后保存
之后执行 source .bashrc

安装结果验证:
java -version

flume-ng -version

三,基本功能实例
例1:
需求:从指定网络端口采集数据输出到控制台
使用flume的关键是写配置文件
进入到flume的conf路径下:执行vim example.conf(我随便起的文件名,你可以自定义)

写入如下内容:

#Name the components on this agent
a1.sources = r1 #a1 就是agent的name, r1是source的name
a1.sinks = k1 #k1是sink的name
a1.channels = c1 #c1是channel的name
#Describe/Configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop00 #hadoop00是我本机的hostname,这里使用你的hostname
a1.sources.r1.port = 44444
#Describe the sink
a1.sinks.k1.type = logger
#Use a channel which buffers events in memory
a1.channels.c1.type = memory
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/example.conf -Dflume.root.logger=INFO,console
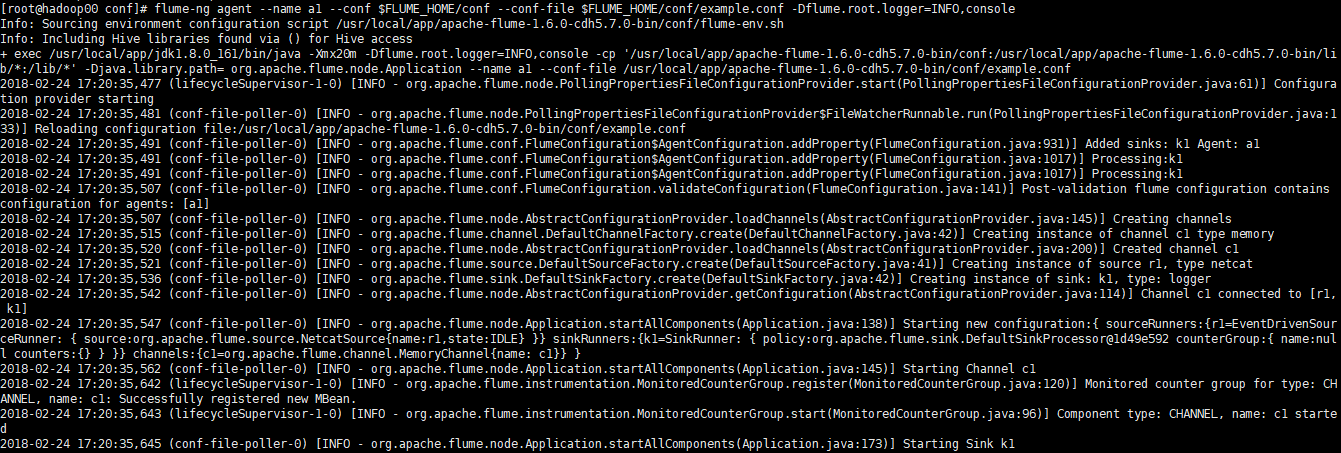
测试
重新开启一个终端输入 telnet hadoop00 44444
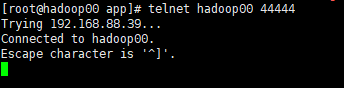
输入任意字符
hello
world
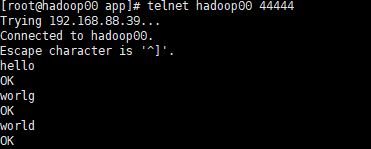
在agent窗口查看

例2:
需求:监控一个文件实时采集新增的数据输出到控制台
Agent选型: exec source + memory channel + logger sink
步骤:
1,创建配置文件:
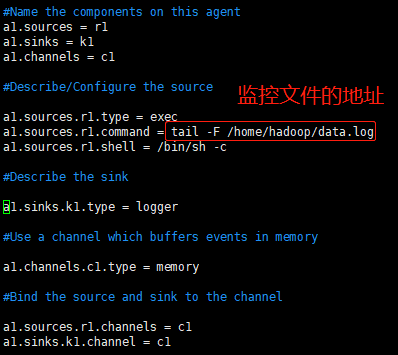
2,启动agent
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/example1.conf -Dflume.root.logger=INFO,console
3,重新开启一个终端,在文件data.log中输入内容

data.log开始是一个空文件
输入内容 echo hello world >> data.log

监控成功:

例3:
需求:将A服务器上的日志实时采集到B服务器
技术选型:

机器A ip:192.168.88.36, hostname:hadoop00 机器B ip:192.168.88.73, hostname:hadoop01
配置文件:
hadoop00:

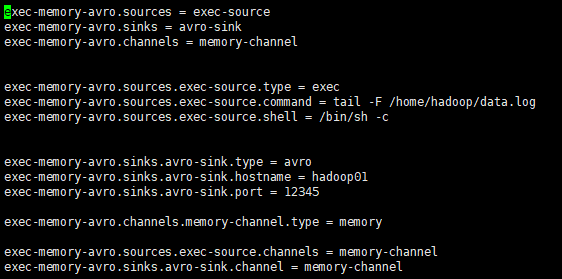
hadoop01:

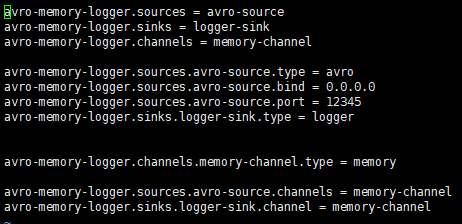
首先启动监控端B机器的agent:
flume-ng agent --name avro-memory-logger --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
再启动日志产生端A机器的agent:
flume-ng agent --name exec-memory-avro --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
测试:

在B机器agent查看:

OK,以上就是目前和大家分享的内容,有问题或者建议,请随时留言,谢谢。