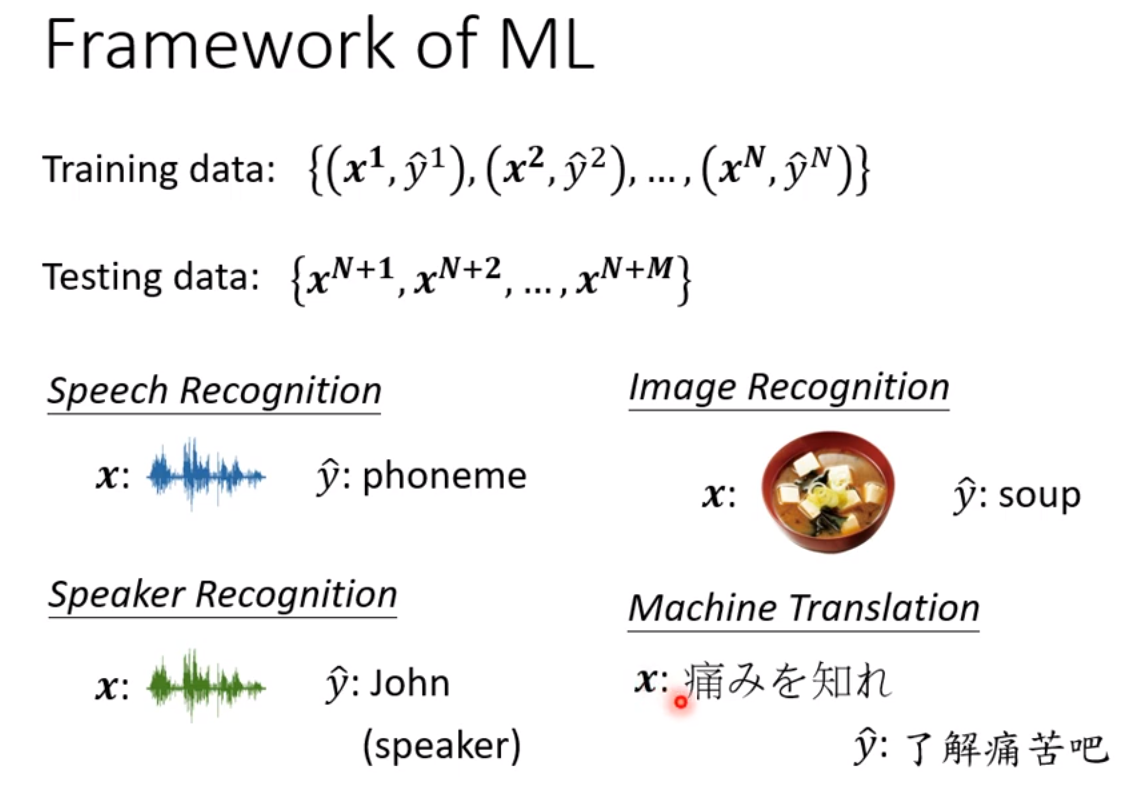
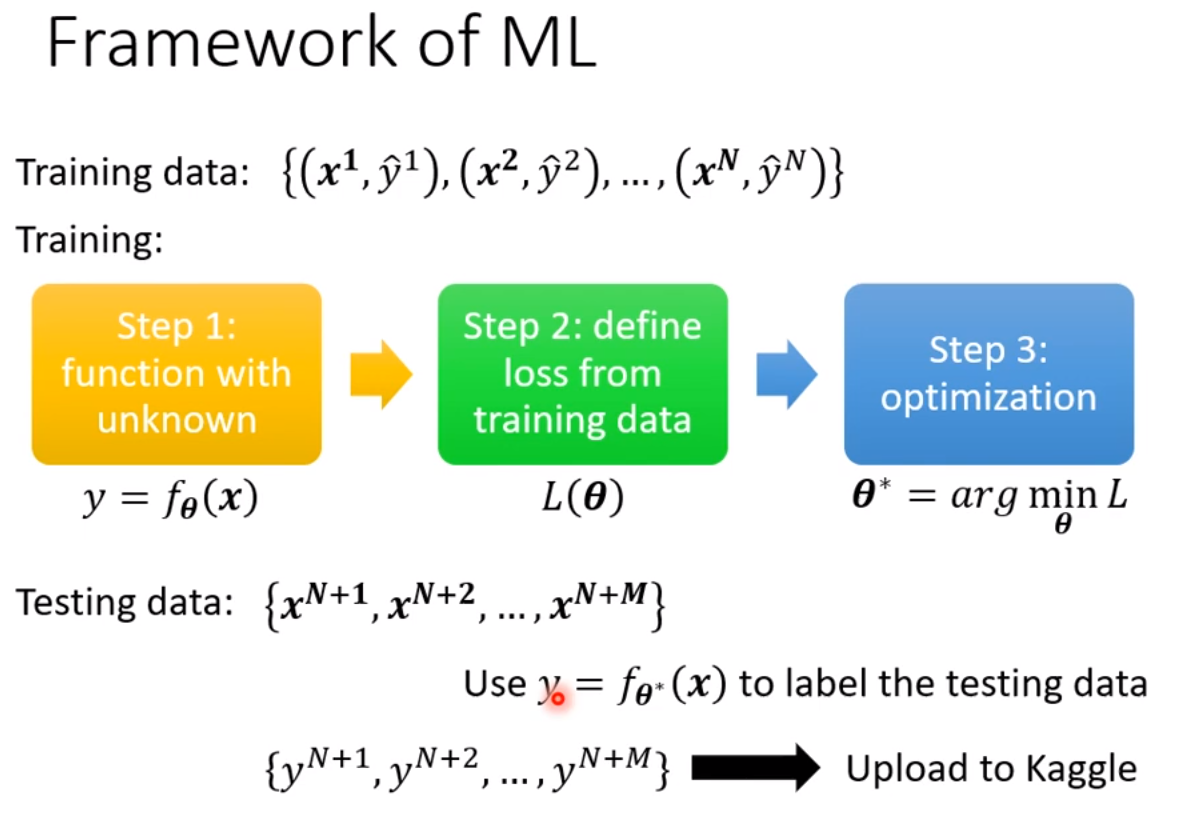
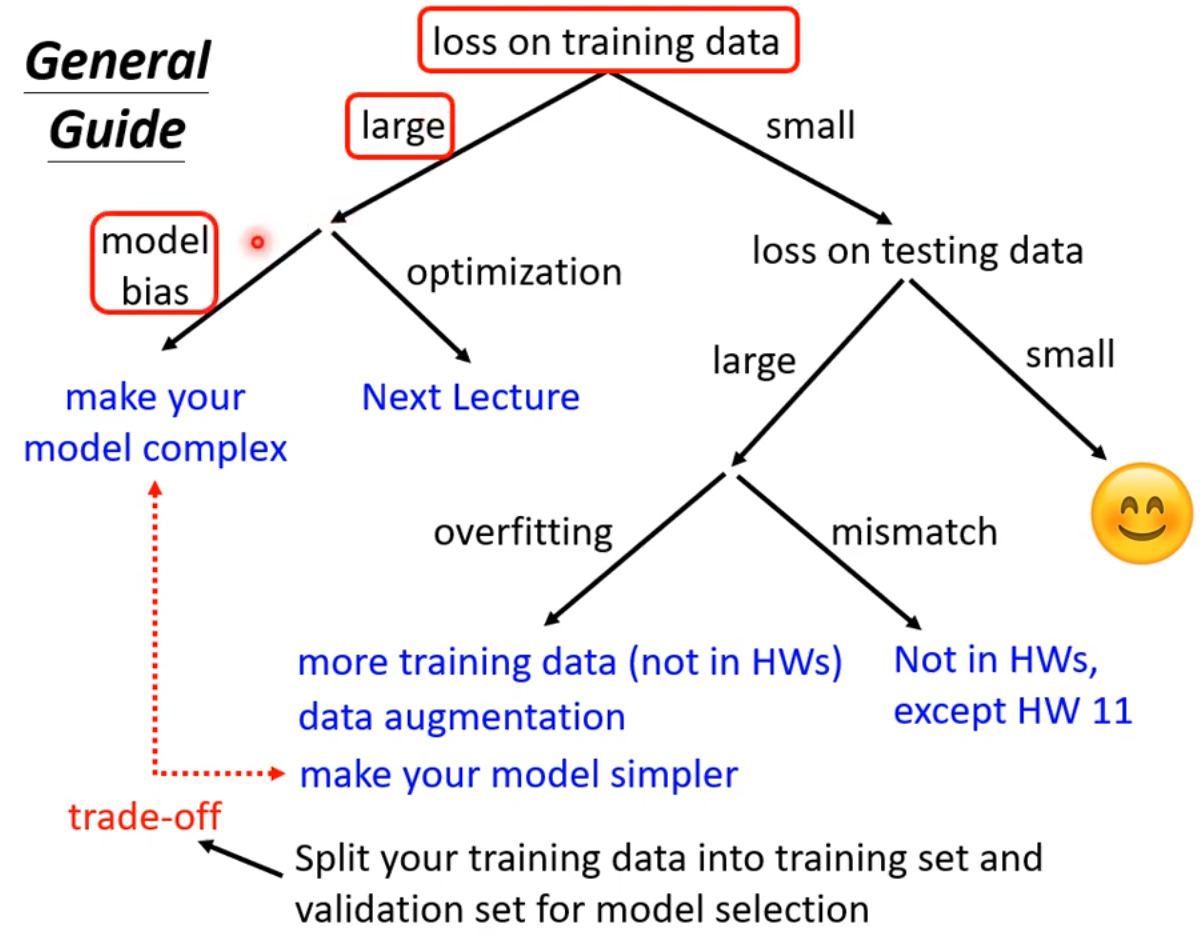

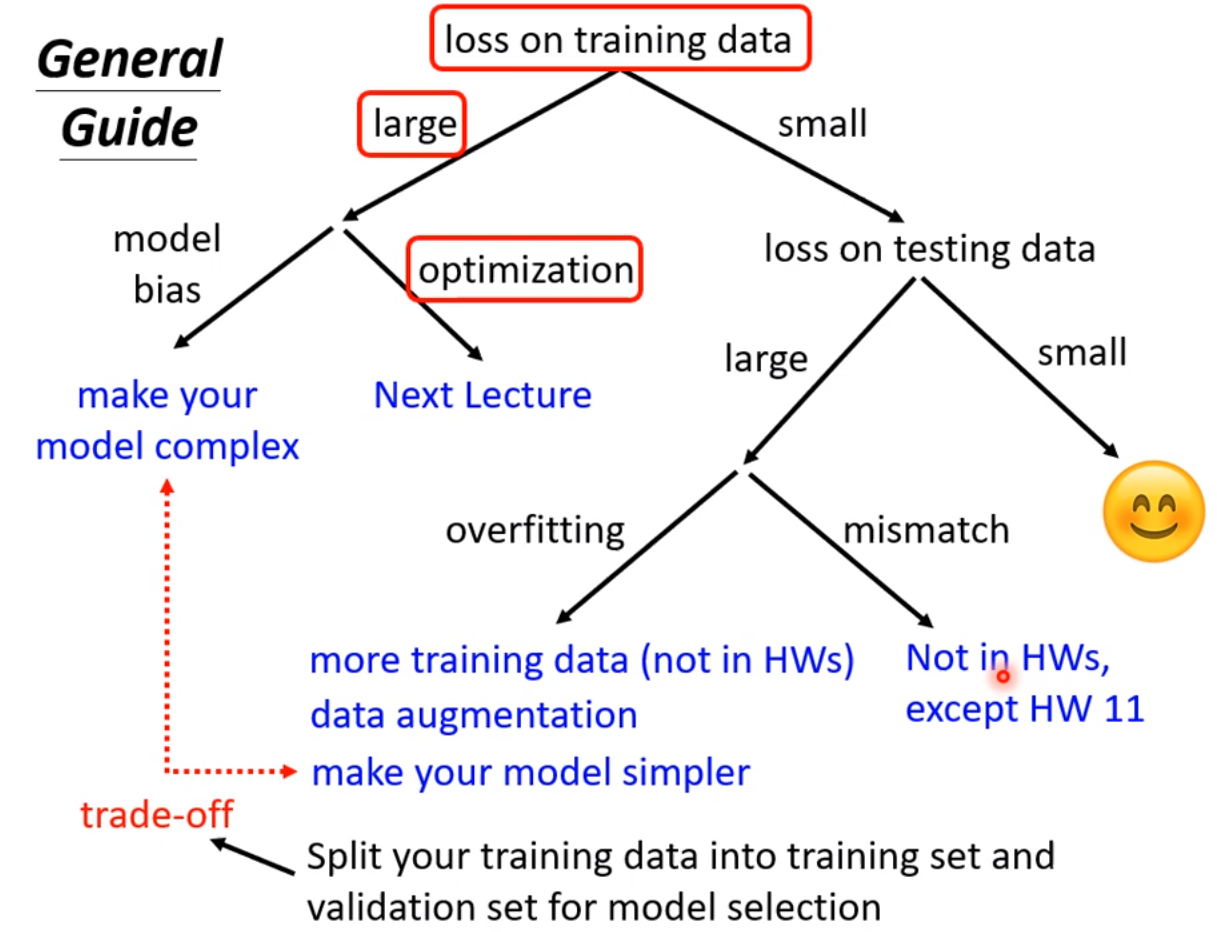
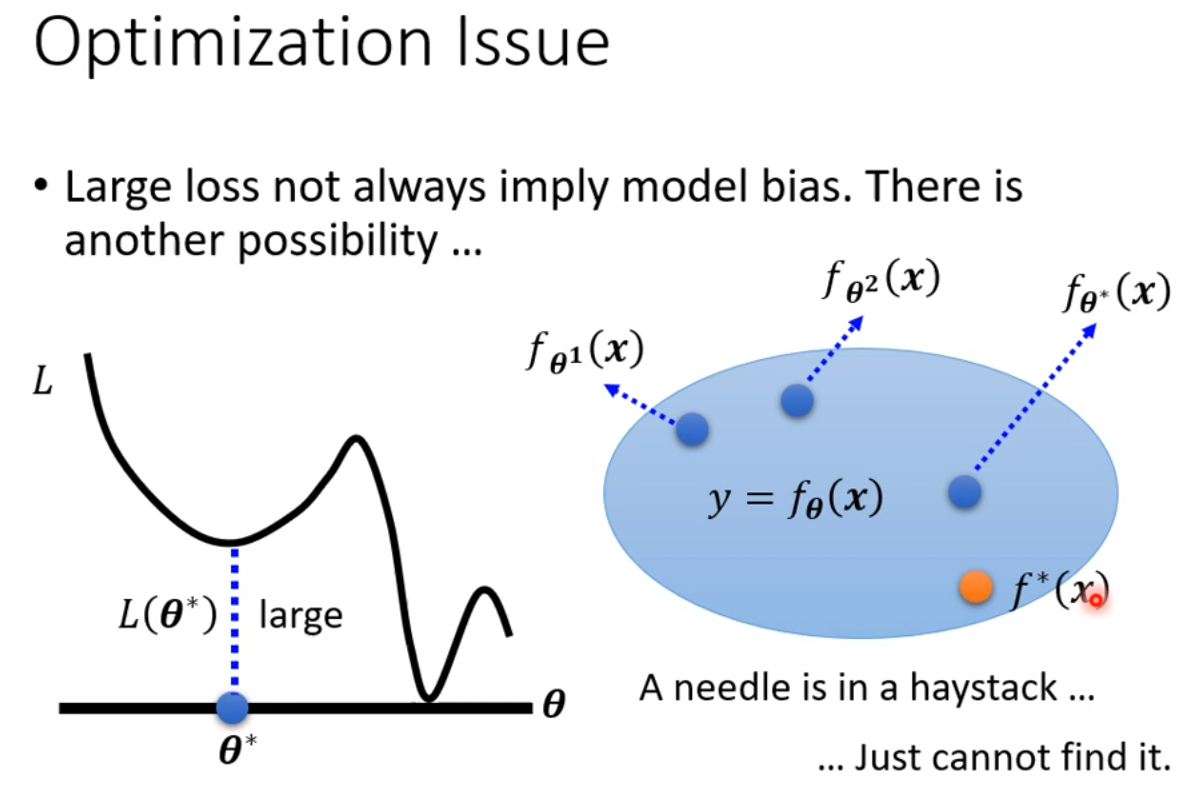


56层只要把前20层参数河这个20层的参数一样,后面36层就什么都不做,只复制前一层的输出就好;所以56层一定可以做大20层的network做的事情;56层比20层的弹性更大,多以没有道理做的没有20层的好。所以此处不是overfitting,也不是model bias,因为56层network弹性是够的,问题是optimization不给力,做的不够好。当你不确定你的优化是否做好使,建议是当你遇到你没有做过的问题,也许你可以先跑一些比较小的或比较浅的network model或比较简单的model,甚至可以用一些不是deep learning的方法,比如linear model,SVM,这些可能是比较容易做optimize,比较不会有optimization失败的问题,这些model会竭尽全力的在他们的能力范围内找一组最好的参数,比较不会有失败的问题。在这些简单的model结果上,可以知道到底能够得到什么样的loss,接下来再train一个深的model,

e.g.,
比如上图,5层反而在训练数据上的loss比4层大,这说明是optimization的problem,那optimization做的不好怎么办呢?有更强大的技术在下一次课讲解。
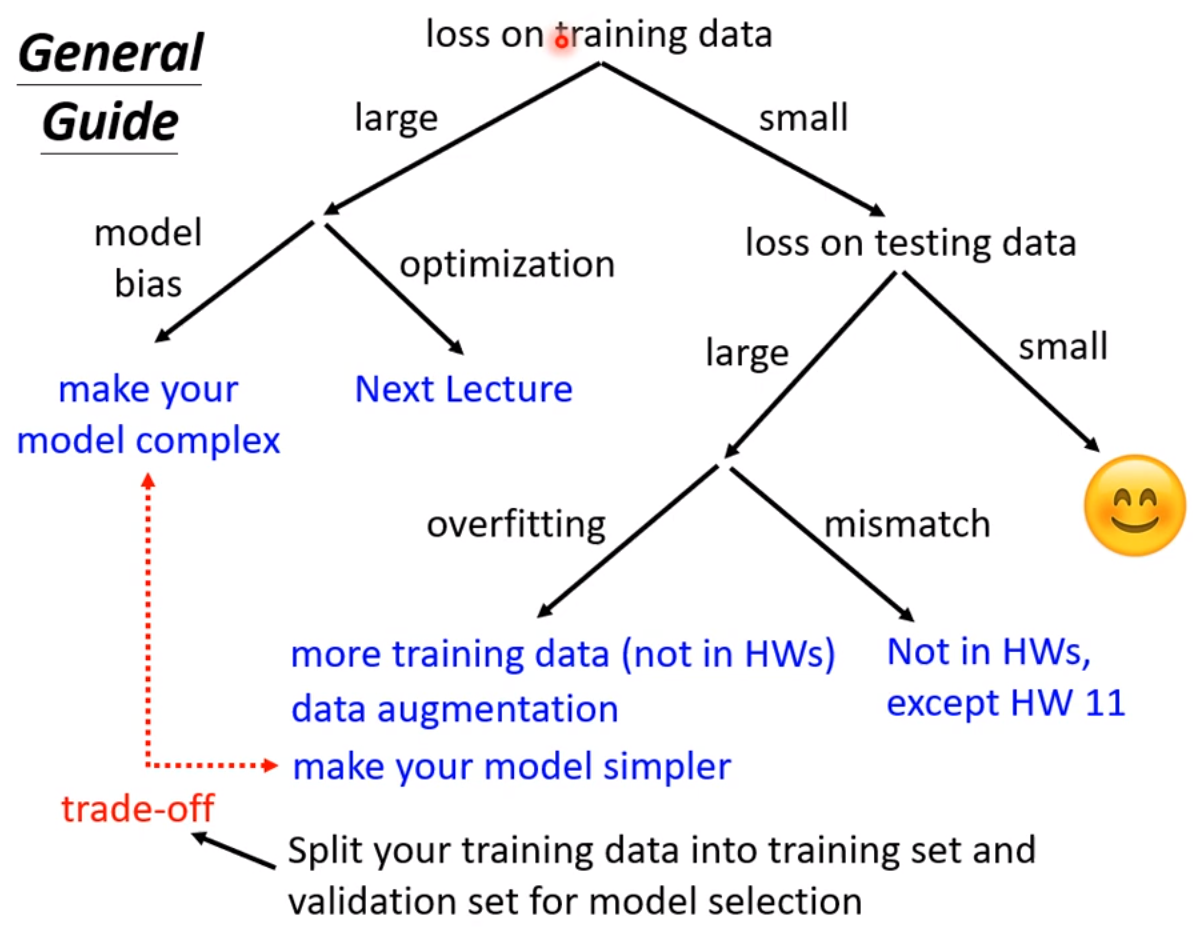
现在先知道如果你的training的loss大,到底是model bias还是optimization问题,前者只需要把model变大,后者则有其他的方法。
假设现在经过一番努力,已经可以把training data的loss变小了,那么看一下在testing data上的loss是否也小,如果小,比strong baseline还小,那就没什么好做的,就结束了;
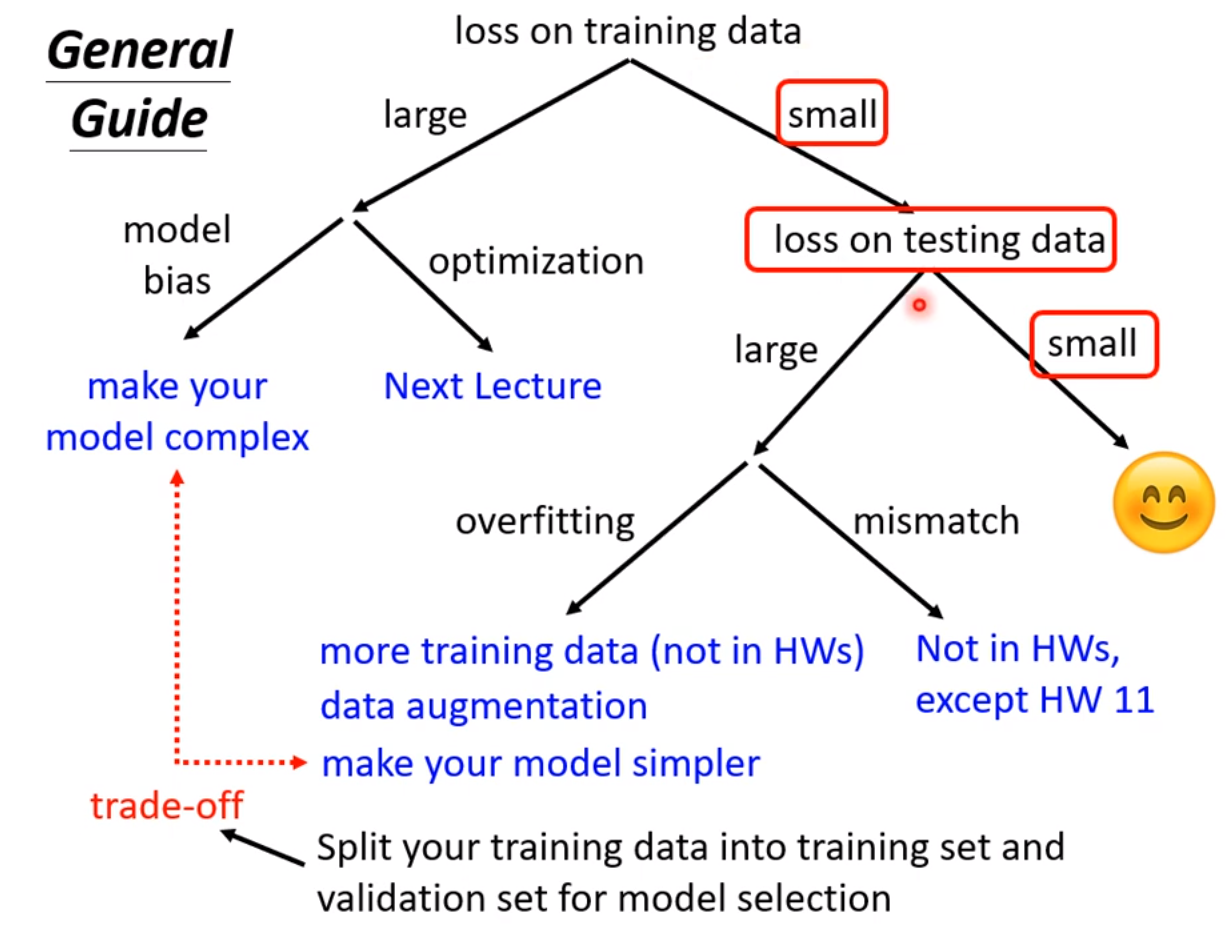
如果在测试集testing上的loss较大,而在training上的loss小,可能就真的遇到over fitting 了。不要一遇到在testing上的结果不好就说是overfitting,而是训练集loss小,测试机loss大,才是overfintting。
所以一定要先把training data上的loss记下来,并要确定你的optimization没有问题,且你的model够大了,接下来再看看是不是testing的问题。接下来如果是训练集loss小,测试集loss大,才有可能是overfitting。
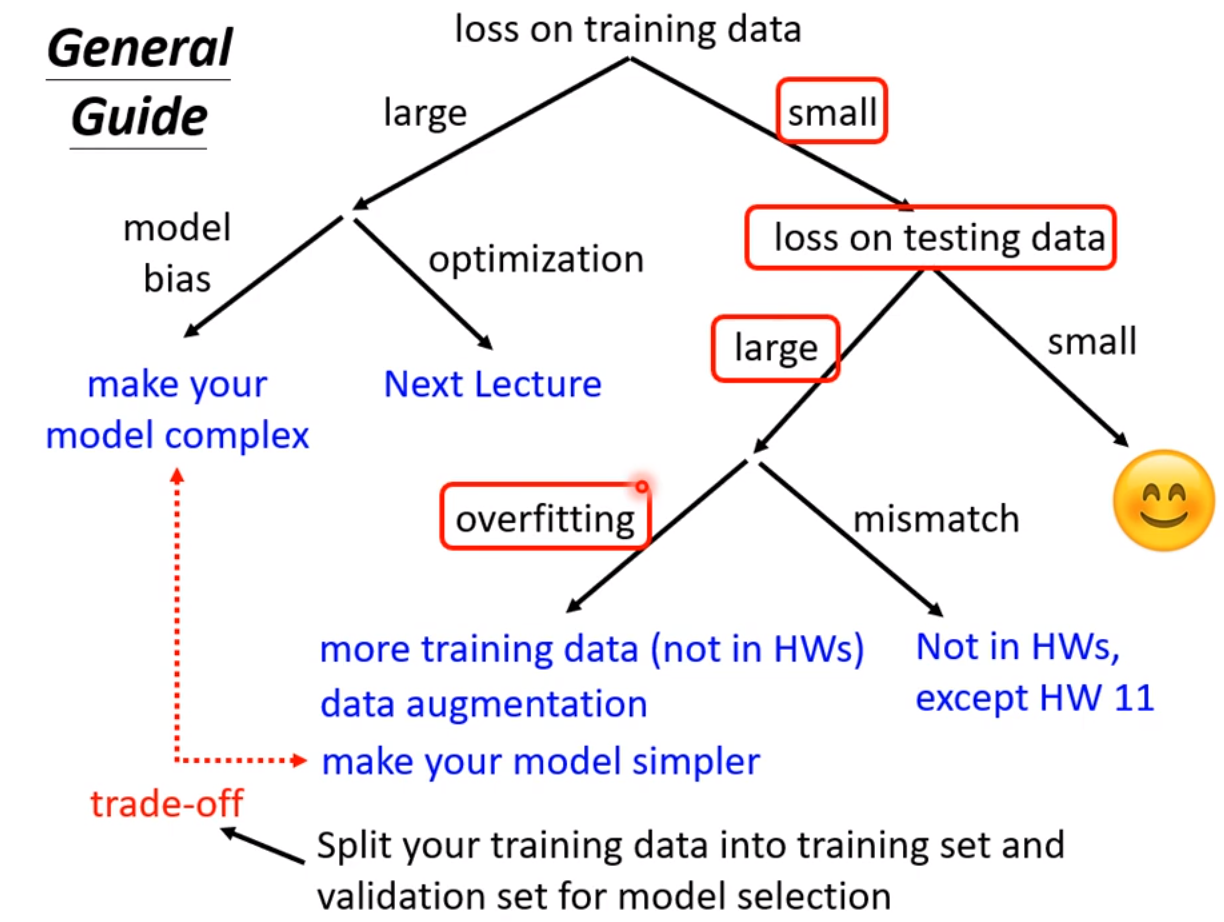
那为何会有overfitting呢?举个极端的例子:
某个很差的机器学习方法,找到了一个一无是处的function,这个方程式,如果某个样本x当作输入时,我们就比对这个x是否出现在训练资料里面,如果有的话,就把他对应的y当作输出;如果没有出现在训练资料里,那么就输出一个随机的数值;
可以看到,这个方程任何事情都没做,但是他在training上的loss确是0;因为你把training的data输入这个方程里面,他的输出和你训练资料的label是一模一样的,所以在training data 上面,这个很差的function的loss是0;只是在testing data上他的loss会变得很大,因为他上面都没有学;

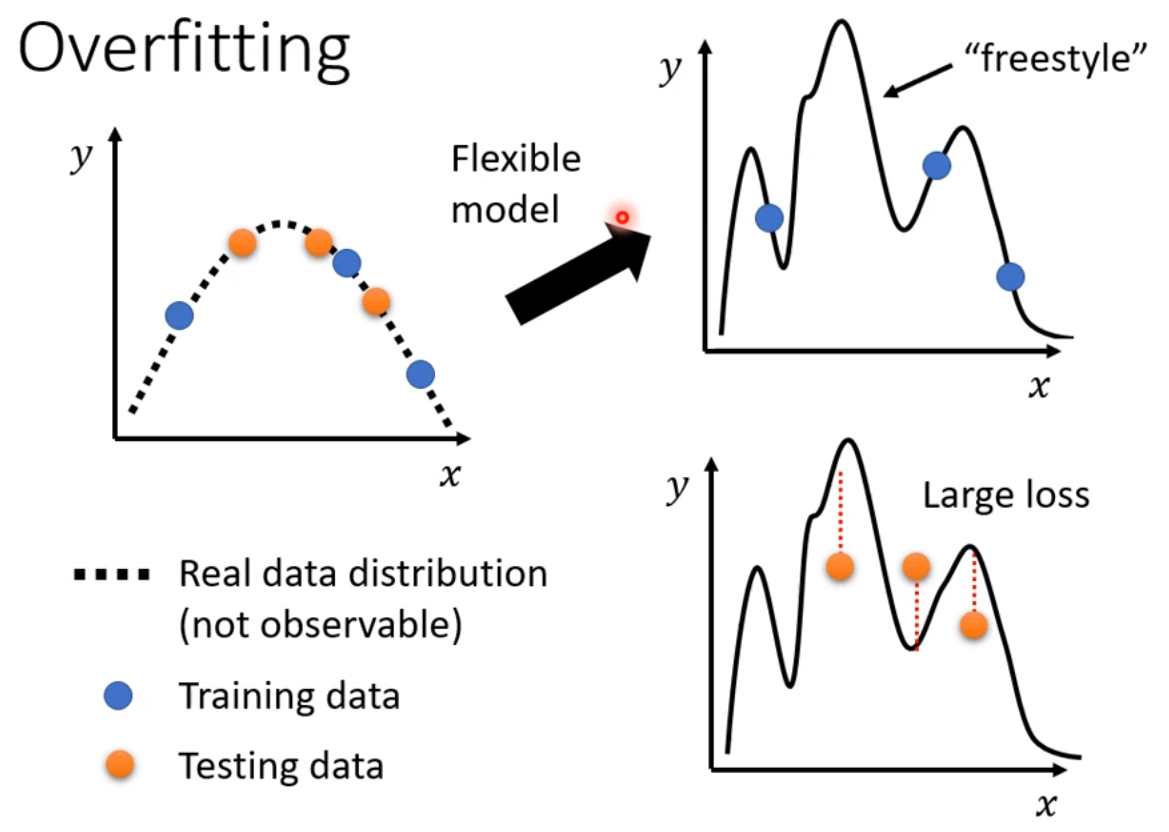
上述为比较极端的例子,但是在一般状况下,也有可能发生类似的事情,e.g.:输入的feature叫做x,输出的label叫做y,x,y都是一维的,关系为下图示的二次曲线:之所以用虚线表示这条虚线,是因为通常没法直接观察到这条曲线,
真正观察到的是训练资料,训练资料可以想象成是从这条曲线上随机sample的几个(若干个)点;假设现在模型的能力很强,flexibility很大,弹性很大,通过给他的几个点,它可以生成若干条通过所给点的不同曲线,但是没给点的地方就会有freestyle,也即模型自己发挥了(因为其弹性很大,flexibility很大),以致生成不同样式的许多条曲线,此时你把testing data用来测试(testing data此处用橙色点表示,testing data可能和training data当然不会一模一样,他们可能从同一个分布中采样出来的,也可能不是),因为上述生成的function模型曲线是用蓝色的testing data找出的,且有freestyle部分,所以这些曲线在橙色的点进行测试时,结果不一定会好。如果蓝色点生成的model自由度很大的话,它可以产生任意次数弯弯曲曲的曲线,以至训练集上拟合的很好,loss很小,但测试集上则不好,loss很大。
那怎么解决over fitting的问题呢?由两种途径:
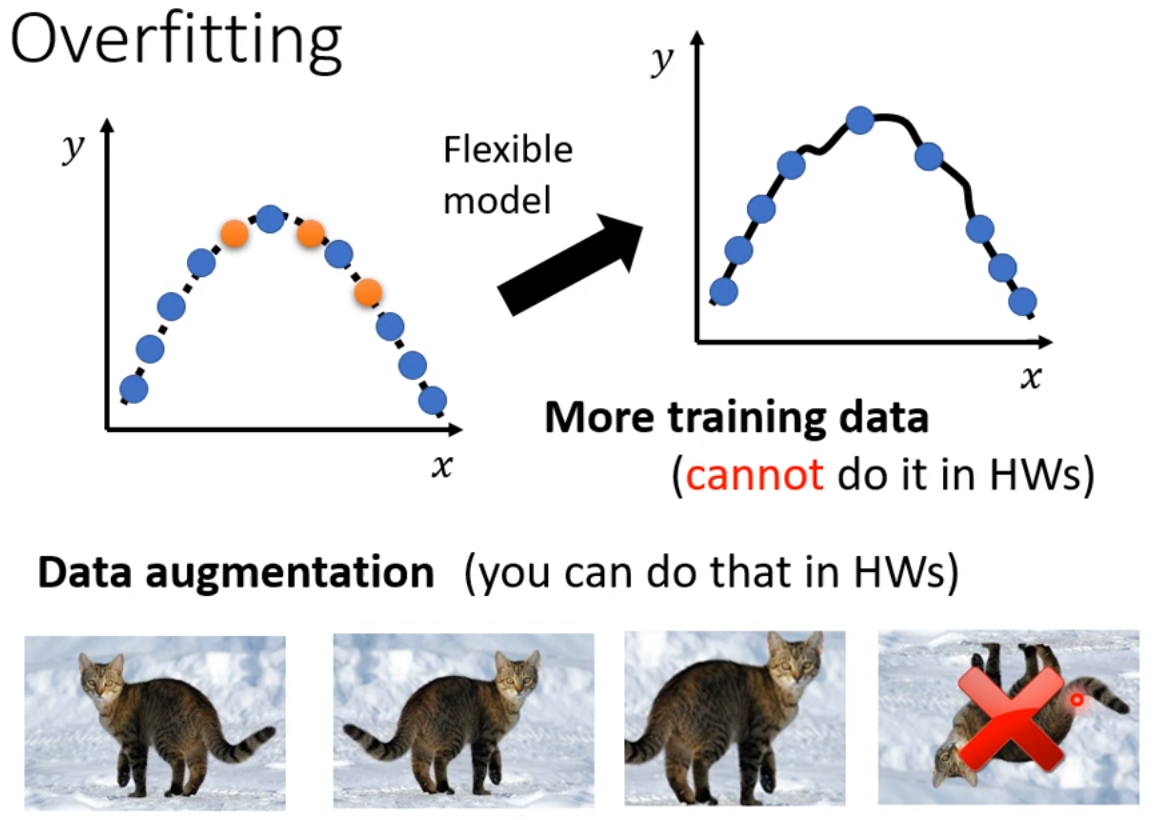
1.增加训练资料,训练集;对然你的model 弹性很大,但是如下图右上角图示,因为点非常之多,所以就在一定程度上限制住了他的灵活性,其就比较接近产生这些训练集背后的曲线,当然形状是也比较接近。但在作业中不要浪费时间来收集资料,而应该更聚焦在
机器学习最核心的能力上,作业中为了让训练资料相对来说较多,可以通过做下图下面所示的做data augmentation,这一招并不算是使用了额外的资料,data augmentation就是基于你对所解决问题的理解,自己创建出一些新的资料;e.g.:图像识别中对某一张图片左右反转、放大图中的某一部分再进行裁剪,这样你的资料数目就变成2倍或更多了;但是注意不要随便乱作,要augment的有道理,比如图像识别中你不能上下反转,因为左右反转并不会影响你的图像识别,但是上下反转可能不是真是世界中常出现的;如果你给机器看这些的话,它可能会学到一些奇怪的东西。所以要根据资料的特性、你对所处理问题的理解来选择合适的data augmentation的方式。
第二种解决over fitting的方式是:不要让你的模型有太大的弹性,要给他一些限制;