Kafka小记
基础概念
- kafka的数据单元被称为消息,消息可以有一个可选的元数据,也就是键,主要作用是为消息选取分区
- kafka的消息通过主题进行分类,主题可以被分为若干个分区,分区中的消息是有序的(通过offset排列)
- 生产者是产生数据的客户端,消费者是消费数据的客户端,是消费者群组的一部分,群组保证每个分区的数据只能被一个消费者使用
- 一个独立的kafka服务器被称为broker,broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存
Kafka和传统的消息系统不同在于:
- Kafka是一个分布式系统,易于向外扩展。
- 它同时为发布和订阅提供高吞吐量。
- 它支持多订阅者,当失败时能自动平衡消费者。
- 消息的持久化。
参数的选择
分区数量:一般用主题吞吐量除以消费者吞吐量算出分区的个数
数据保留策略:可以让数据保留一段时间,也可以让数据保留一定数量
磁盘吞吐量:生产者客户端的性能直接受到服务端磁盘吞吐量的影响,磁盘写入速度越快,生成消息的延迟就会越低
磁盘容量:决定能保存的消息总量
内存:服务器端的可用内存影响消费者的性能,一般消费者从内存中直接读取消息要比从磁盘上读取要快得多
需要多少个broker:取决于需要多少磁盘空间(保存数据)和数据处理能力(磁盘吞吐量和内存)
生产者
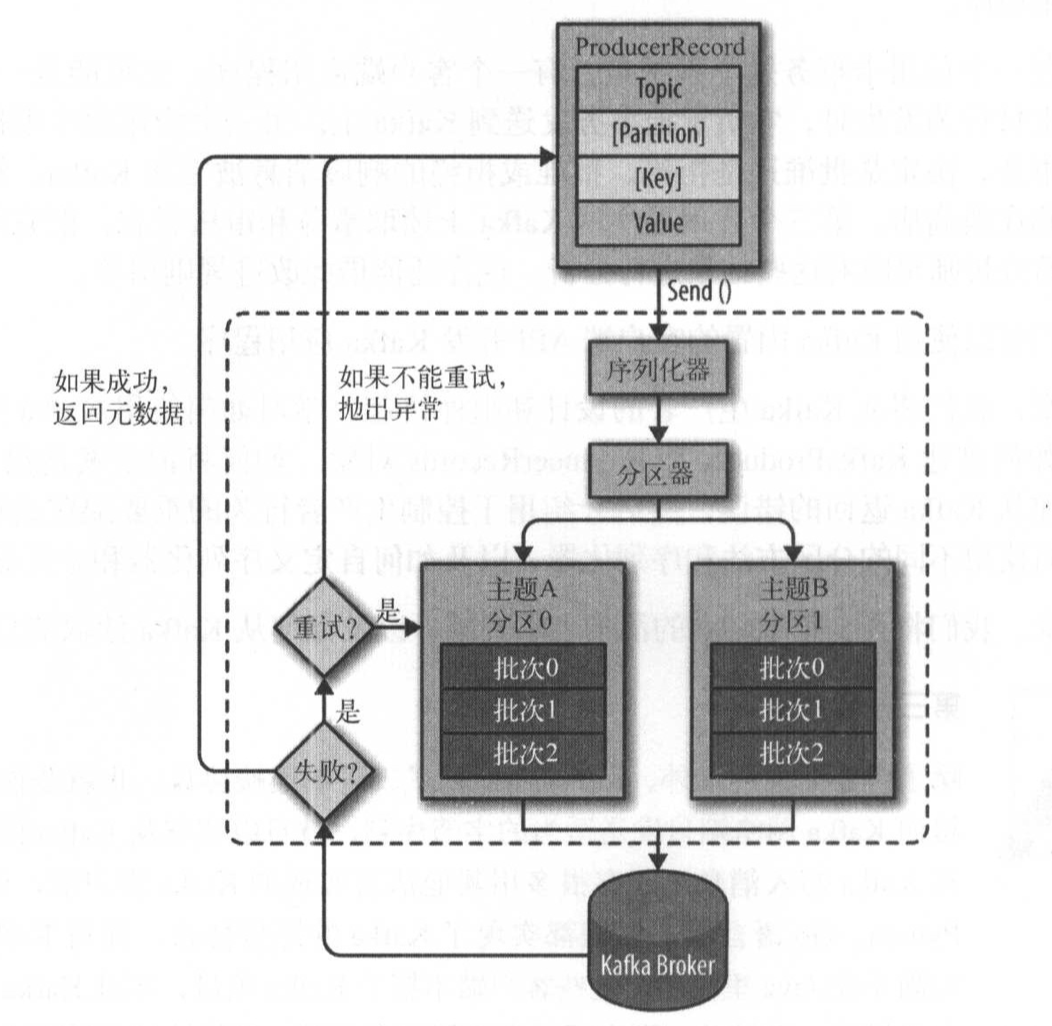
向kafka中发送数据,创建ProducerRecord对象,需要包含目标主题和要发送的内容,还可以指定键或分区,若指定分区,则分区器直接把指定分区返回,若没有指定分区,则分区器根据键来确定分区,接着,记录被添加到一个记录批次里,同一个批次将发送到同一主题的同一分区,若消息成功写入kafka,则返回元数据(包含主题分区信息以及记录的偏移量)
生产者可以选择同步发送或异步发送,异步发送吞吐量高
重要配置:acks,指定了必须要多少分区副本收到消息,生产者才会认为数据写入成功,acks=0表示生产者不需要等待;acks=1表示只要集群的首领节点收到消息则生产者就会收到一个来自服务器的成功响应,若没有收到消息的节点成为新首领,消息还是会丢失;acks=all表示只有当所有参与复制的节点全部收到消息,生产者才会收到来自服务器的成功响应
消费者
一个消费者群组可以有多个消费者,他们订阅同一个主题,一个分区只能被一个消费者消费;
往群组中增加消费者是横向伸缩消费能力的主要方式;
消费者通过轮询的方式向服务器请求数据,一旦消费者订阅了主题,轮询就会处理所有的细节,包括群组协调、分区再均衡、发送心跳和获取数据;
重要配置:
- auto.offset.reset:指定消费者在读取一个没有偏移量的分区或者偏移量无效的情况下,该作何处理,默认是latest,表示从最新的记录开始读,earliest表示从起始位置开始读取
- enable.auto.commit:指定消费者是否自动提交偏移量,默认是true
若提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于这两个偏移量之间的消息就会被重复处理;若提交的偏移量大于客户端处理的最后一个偏移量,则处于这两个偏移量之间的消息就会丢失,而且即使是消费者自动提交,在两次提交间隔期间发生了再均衡,也无法避免消息重复处理,因此开发者也可以自己提交当前偏移量
开发者可以选择同步提交或者异步提交,也可以提交特定偏移量,在后续处理的时候也可以从特定偏移量开始处理
集群成员关系
- 控制器就是一个broker,除了一般broker的功能之外,还负责分区首领的选举;broker大部分工作就是处理客户端、分区副本和控制器发送给分区首领的请求
- 每个分区都有一个首领副本,所有生产者和消费者的请求都会经过这个副本,而跟随者副本不需要处理来自客户端的请求,只需要向首领发送获取数据的请求,与首领保持一致
- 如果一个副本无法与首领保持一致,在首领失效时,它就不能称为新首领,即只有同步的副本可以被选为新首领
元数据请求:每个broker上都缓存着元数据信息,包含主题所包含的分区、每个分区有哪些副本、以及哪个副本是首领,客户端可以给任意一个broker发送元数据请求,然后缓存这些信息,并直接向目标broker发送生产请求和获取请求,同时它们也需要通过发送元数据请求刷新这些信息
生产请求:客户端向服务器写入消息,可以通过acks的设定决定服务器如何响应
获取请求:客户端向服务器读取消息,必须在消息写入所有同步副本以后才能发送给消费者
可靠的数据传递
kafka的可靠性保证:
- kafka可以保证分区消息的顺序
- 只有当消息被写入分区的所有同步副本时,才能被消费者读取
- 只要还有一个副本活跃,已经提交的消息就不会丢失
- 副本的复制会带来更高的可用性,同时也会需要更高的存储
- 生产者利用恰当的acks值来保证可靠性,消费者通过用恰当的方式提交偏移量来保证可靠性
复制需要权衡可用性和高存储、不完全的首领选举(分区首领崩溃,集群中只剩下不同步的副本)需要权衡可用性和数据一致性
多集群架构
-
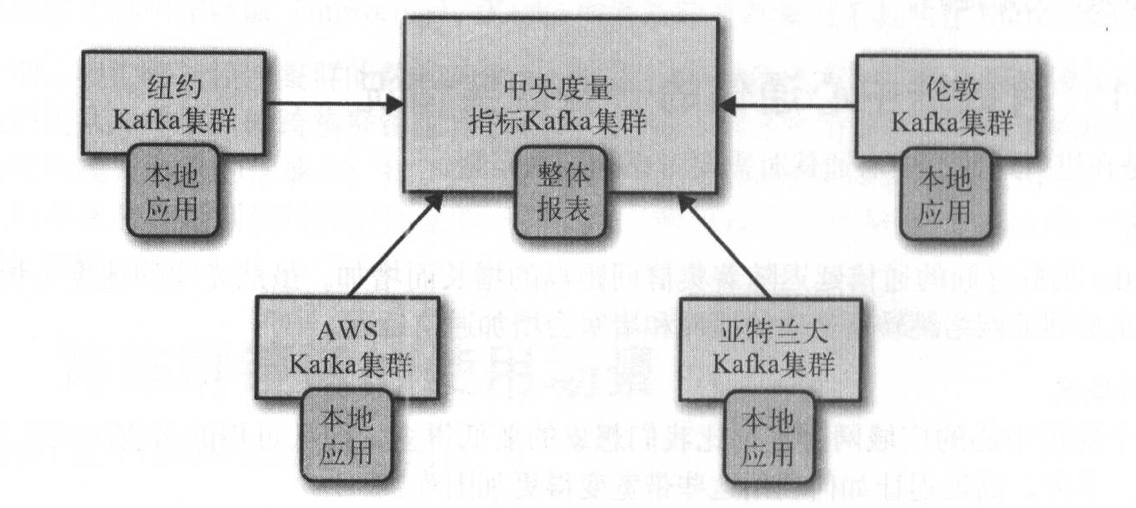
Hub和Spoke架构
这种架构的好处在于,数据只会在本地集群生成,然后镜像到中心集群一次,只处理单个集群的应用程序部署在本地集群,需要处理多个数据中心数据的应用程序部署在中央集群,这种架构易部署、配置和监控,但是本地的应用程序不可以访问其他本地集群的数据
-
双活架构
这种架构的好处在于每个数据中心都有完备的功能,一旦一个数据中心发生失效,就可以把用户重定向到另一个数据中心,问题在于如何在进行多个位置的数据异步读取和异步更新时避免冲突

-
主备架构
这种架构的好处在于易于实现,而且可以用于任何一种场景
