指针[收藏]
直接引用
char a; a = 10;

一、什么是指针?
1.我们已经知道,"直接引用"是直接通过变量名来读写变量
2.C语言中还有一种"间接引用"的方式(以变量a为例):首先将变量a的地址存放在另一个变量中,比如存放在变量b中,然后通过变量b来间接引用变量a,间接读写变量a的值。这就是"间接引用"。
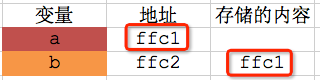
如果程序通过"间接引用"的方式来修改a的值,可以这样做:先根据 变量名b 获取 变量b 的地址ffc2,取出变量b中存储的内容ffc1,也就是变量a的地址,再根据变量a的地址ffc1找到a的存储空间,然后修改里面的数据。
3.总结一句:用来存放变量地址的变量,就称为"指针变量"。在上面的情况下,变量b就是个"指针变量",我们可以说指针变量b指向变量a。
二、指针的定义
一般形式:类名标识符 *指针变量名;
int *p; float *q;
- "*"是一个说明符,用来说明这个变量是个指针变量,是不能省略的,但它不属于变量名的一部分
- 前面的类型标识符表示指针变量所指向的变量的类型,而且只能指向这种类型的变量
三、指针的初始化
1.先定义后初始化

1 // 定义int类型的变量a 2 int a = 10; 3 4 // 定义一个指针变量p 5 int *p; 6 7 // 将变量a的地址赋值给指针变量p,所以指针变量p指向变量a 8 p = &a;
注意第8行,赋值给p的是变量a的地址&a
2.在定义的同时初始化
// 定义int类型的变量a int a = 10; // 定义一个指针变量p // 并将变量a的地址赋值给指针变量p,所以指针变量p指向变量a int *p = &a;
3.初始化的注意
指针变量是用来存放变量地址的,不要给它随意赋值一个常数。下面的写法是错误的
int *p; p = 200; // 这是错误的
四、指针运算符
1.给指针指向的变量赋值
1 char a = 10; 2 printf("修改前,a的值:%d ", a); 3 4 // 指针变量p指向变量a 5 char *p = &a; 6 7 // 通过指针变量p间接修改变量a的值 8 *p = 9; 9 10 printf("修改后,a的值:%d", a);
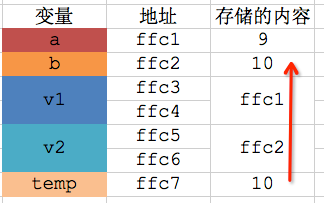
当程序刚执行完第5行代码时,内存中大概的分布情况是这样的
 ,a值是10,p值就是变量a的地址ffc3。
,a值是10,p值就是变量a的地址ffc3。
注意下第5、第8行,都有个"*",它们的含义是不一样的:
(1) 第5行的"*"只是用来说明p是个指针变量
(2) 第8行的"*"是一个指针运算符,这里的*p代表根据p值ffc3这个地址访问对应的存储空间,也就是变量a的存储空间,然后将右边的数值9写入到这个存储空间,相当于 a = 9;,于是内存中就变成这样了

输出结果为: ,可以发现,我们通过变量p间接修改了变量a的值。
,可以发现,我们通过变量p间接修改了变量a的值。
2.取出指针所指向变量的值
指针运算符除了可以赋值之外,还可以用于取值
1 char a = 10; 2 3 char *p; 4 p = &a; 5 6 char value = *p; 7 printf("取出a的值:%d", value);
输出结果: ,第6行中的*p的意思是:根据p值(即变量a的地址)访问对应的存储空间,并取出存储的内容(即取出变量a的值),赋值给value
,第6行中的*p的意思是:根据p值(即变量a的地址)访问对应的存储空间,并取出存储的内容(即取出变量a的值),赋值给value
3.使用注意
在指针变量没有指向确定地址之前,不要对它所指的内容赋值。下面的写法是错误的
int *p; *p = 10; //这是错误的
应该在指针变量指向一个确定的变量后再进行赋值。下面的写法才是正确的
// 定义2个int型变量 int a = 6, b; // 定义一个指向变量b的指针变量p int *p; p = &b; // 将a的值赋值给变量b *p = a;
五、指针的用途举例
1.例子1
前面我们通过指针变量p间接访问了变量a,在有些人看来,觉得指针变量好傻B,直接用变量名a访问变量a不就好了么,干嘛搞这么麻烦。别着急,接下来举个例子,让大家看看指针还能做什么事情。
现在有个要求:写一个函数swap,接收2个整型参数,功能是互换两个实参的值。
1> 如果没学过指针,你可能会这样写
1 void swap(char v1, char v2) { 2 printf("更换前:v1=%d, v2=%d ", v1, v2); 3 4 // 定义一个中间变量 5 char temp; 6 7 // 交换v1和v2的值 8 temp = v1; 9 v1 = v2; 10 v2 = temp; 11 12 printf("更换后:v1=%d, v2=%d ", v1, v2); 13 } 14 15 int main() 16 { 17 char a = 10, b = 9; 18 printf("更换前:a=%d, b=%d ", a, b); 19 20 swap(a, b); 21 22 printf("更换后:a=%d, b=%d", a, b); 23 return 0; 24 }
输出结果: ,虽然v1和v2的值被交换了,但是变量a和b的值根本就没有换过来。因为基本数据类型作为函数实参时,只是纯粹地将值传递给形参,形参的改变并不影响实参。
,虽然v1和v2的值被交换了,但是变量a和b的值根本就没有换过来。因为基本数据类型作为函数实参时,只是纯粹地将值传递给形参,形参的改变并不影响实参。
我们可以简要分析一下这个过程:
* 在第20行中,将变量a、b的值分别传递给了swap函数的两个形参v1、v2
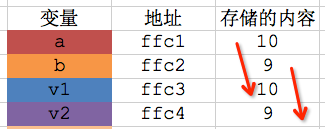
* 在第8行中,将v1的值赋值给了temp

* 在第9行中,将v2的值赋值给了v1

* 在第10行中,将temp的值赋值给了v2

就这样,v1和v2的值被交换了,但是a和b的值一直都没有改变
2> 如果学了指针,就应该这样写
1 void swap(char *v1, char *v2) { 2 // 中间变量 3 char temp; 4 5 // 取出v1指向的变量的值 6 temp = *v1; 7 8 // 取出v2指向的变量的值,然后赋值给v1指向的变量 9 *v1 = *v2; 10 11 // 赋值给v2指向的变量 12 *v2 = temp; 13 } 14 15 int main() 16 { 17 char a = 10, b = 9; 18 printf("更换前:a=%d, b=%d ", a, b); 19 20 swap(&a, &b); 21 22 printf("更换后:a=%d, b=%d", a, b); 23 return 0; 24 }
先看看输出结果: ,变量a和b的值终于换过来了。
,变量a和b的值终于换过来了。
解释一下:
(在16位编译器环境下,一个指针变量占用2个字节)
* 先注意第20行,传递是变量的地址。因此swap函数的形参v1指向了变量a,v2指向了变量b

* 第6行代码是取出v1指向的变量的值,也就是变量a的值:10,然后赋值给变量temp
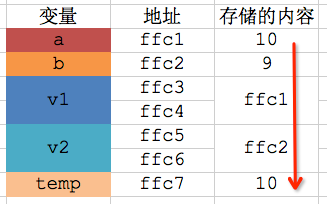
* 第9行代码是取出v2指向的变量(变量b)的值,然后赋值给v1指向的变量(变量a)
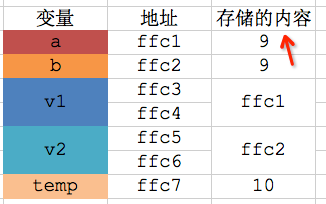
* 第12行代码是将temp变量的值赋值给v2指向的变量(变量b)
相信你已经感受到指针的强大了,如果没有指针,在一个函数的内部根本改变不了外部的实参。
2.例子2
接下来再举一个指针的实用例子。默认情况下,一个函数只能有一个返回值,有了指针,我们可以实现函数有"多返回值"。
现在有个要求:写一个函数sumAndMinus,可以同时计算2个整型的和与差,函数执行完毕后,返回和与差(注意了,这里要返回2个值)
// 计算2个整型的和与差 int sumAndMinus(int v1, int v2, int *minus) { // 计算差,并赋值给指针指向的变量 *minus = v1 - v2; // 计算和,并返回和 return v1 + v2; } int main() { // 定义2个int型变量 int a = 6, b = 2; // 定义2个变量来分别接收和与差 int sum, minus; // 调用函数 sum = sumAndMinus(a, b, &minus); // 打印和 printf("%d+%d=%d ", a, b, sum); // 打印差 printf("%d-%d=%d ", a, b, minus); return 0; }
输出结果: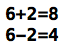 ,和与差都由同一个函数计算并返回出来。和是函数的直接返回值,差是通过函数的第3个指针参数间接返回。
,和与差都由同一个函数计算并返回出来。和是函数的直接返回值,差是通过函数的第3个指针参数间接返回。
因此有了指针,我们可以让函数有"无限个"返回值。
六、关于指针的疑问
刚学完指针,都可能有一大堆的疑惑,这里我列出几个常见的疑惑吧。
1.一个指针变量占用多少个字节的内存空间?占用的空间是否会跟随所指向变量的类型而改变?
在同一种编译器环境下,一个指针变量所占用的内存空间是固定的。比如,在16位编译器环境下,任何一个指针变量都只占用2个字节,并不会随所指向变量的类型而改变。

2.既然每个指针变量所占用的内存空间是一样的,而且存储的都是地址,为何指针变量还要分类型?而且只能指向一种类型的变量?比如指向int类型的指针、指向char类型的指针。
其实,我觉得这个问题跟"数组为什么要分类型"是一样的。
* 看下面的代码,利用指针p读取变量c的值
1 int i = 2; 2 char c = 1; 3 4 // 定义一个指向char类型的指针 5 char *p = &c; 6 7 // 取出 8 printf("%d", *p);
这个输出结果应该难不倒大家: ,是可以成功读取的。
,是可以成功读取的。
* 如果我改一下第5行的代码,用一个本应该指向int类型变量的指针p,指向char类型的变量c
int *p = &c;
我们再来看一下输出: ,c的原值是1,现在取出来却是513,怎么回事呢?这个要根据内存来分析
,c的原值是1,现在取出来却是513,怎么回事呢?这个要根据内存来分析
根据变量的定义顺序,这些变量在内存中大致如下图排布:
其中,指针变量p和int类型变量i各占2个字节,char类型的c占一个字节,p指向c,因此p值就是c的地址

1> 最初的时候,我们用char *p指向变量c。当利用*p来获取变量c的值时,由于指针p知道变量c是char类型的,所以会从ffc3这个地址开始读取1个字节的数据:0000 0001,转为10进制就是1
2> 后来,我们用int *p指向变量c。当利用*p获取变量c的值时,由于指针p认为变量c是int类型的,所以会从ffc3这个地址开始读取2个字节的数据:0000 0010 0000 0001,转为10进制就是513
可见,给指针分类是多么重要的一件事,而且一种指针最好只指向一种类型的变量,那是最安全的。
路漫漫其修远兮,吾将上下而求索。
如果还行,如果您不忙的话, 请看右下角,不管是好是坏,轻松点击下!