<<.NET B/S 架构实践>> 几种概念区别 - 算法、设计模式、企业应用架构模式、架构模式
算法:相信大家对算法肯定不陌生(但其实绝大多数开发人员对这个非常陌生且抗拒),因为从学校没毕业开始就已经被算法折磨了,哈哈
设计模式:爱学习的开发人员对这个也不会陌生,是些到了一定工作阶段必须学的思想以及解决问题的通用方法
企业应用架构模式:Martin Fowler所著,其实从难度上讲,比不上设计模式,只是内容较多,更加实际且更加符合人类的理解
架构模式:最著名的资料是POSA那几本书,讲的是云里雾里,看这本书时,设计模式那点难度根本就不叫难度,哈哈,看起来极其痛苦,但是又非常快乐(哈哈,这就要看看书的人了)
在这些概念当中,个人认为架构模式以及算法是比较难的,如果只能选择一个,我就选算法为最难,所以携程才招了一帮博士搞算法,因为其他的都能慢慢搞懂,唯独算法是需要真正长久专研下去的,能够达到非常深奥。
题外话:像这些概念其实都80、90年代就已经出现了,可惜,我们却刚开始研究人家的东西,悲哀啊。
很多人认为
- 算法用不到,所以不用学
- 架构模式不就分层嘛,地球人都会
其实不然,memcache是怎么发明的?操作系统的调度算法怎么实现的?为啥这么实现而不是那样实现?有和依据?为什么加了数据库的索引后搜索能飞快?为什么加了这个索引却没有用?为什么大规模文本搜索时要用Lucene来搜索,而不是sql server或者oracle?
这些为什么后面大部分是由算法和架构决定的,绝不是简单的分层架构。
希望广大的开发人员能关注这些,中国的研发需要中国程序员。
心怀远大理想。
为了家庭幸福而努力。
A2D科技,服务社会。
A2D Framework(Alpha)
- 1. Cache System(本地缓存与分布式缓存共存、支持Memcache和Redis、支持贴标签形式(类似Spring 3.x的Cache形式))
- 2. Event System(本地事件与分布式事件分发)
- 3. IoC(自动匹配功能,实例数量限制功能)
- 4. Sql Dispatcher System(支持ADO.NET及EF)
- 5. Session System(分布式Session系统)
- 6. 分布式Command Bus(MSMQ实现,解决4M限制,支持Session的读取)
- 7. 规则引擎
LeetCode:Word Ladder I II
其他LeetCode题目欢迎访问:LeetCode结题报告索引
Given two words (start and end), and a dictionary, find the length of shortest transformation sequence from start to end, such that:
- Only one letter can be changed at a time
- Each intermediate word must exist in the dictionary
For example,
Given:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
As one shortest transformation is "hit" -> "hot" -> "dot" -> "dog" -> "cog",
return its length 5.
Note:
- Return 0 if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
分析:这种题,肯定是每次改变单词的一个字母,然后逐渐搜索,很多人一开始就想到用dfs,其实像这种求最短路径、树最小深度问题bfs最适合,可以参考我的这篇博客bfs(层序遍历)求二叉树的最小深度。本题bfs要注意的问题:
- 和当前单词相邻的单词是:对当前单词改变一个字母且在字典中存在的单词
- 找到一个单词的相邻单词,加入bfs队列后,要从字典中删除,因为不删除的话会造成类似于hog->hot->hog的死循环。而删除对求最短路径没有影响,因为我们第一次找到该单词肯定是最短路径,即使后面其他单词也可能转化得到它,路径肯定不会比当前的路径短(如果要输出所有最短路径,则不能立即从字典中删除,具体见下一题)
- bfs队列中用NULL来标识层与层的间隔,每次碰到层的结尾,遍历深度+1
我们利用和求二叉树最小深度层序遍历的方法来进行bfs,代码如下: 本文地址

1 class Solution { 2 public: 3 int ladderLength(string start, string end, unordered_set<string> &dict) { 4 // IMPORTANT: Please reset any member data you declared, as 5 // the same Solution instance will be reused for each test case. 6 //BFS遍历找到的第一个匹配就是最短转换,空字符串是层与层之间的分隔标志 7 queue<string> Q; 8 Q.push(start); Q.push(""); 9 int res = 1; 10 while(Q.empty() == false) 11 { 12 string str = Q.front(); 13 Q.pop(); 14 if(str != "") 15 { 16 int strLen = str.length(); 17 for(int i = 0; i < strLen; i++) 18 { 19 char tmp = str[i]; 20 for(char c = 'a'; c <= 'z'; c++) 21 { 22 if(c == tmp)continue; 23 str[i] = c; 24 if(str == end)return res+1; 25 if(dict.find(str) != dict.end()) 26 { 27 Q.push(str); 28 dict.erase(str); 29 } 30 } 31 str[i] = tmp; 32 } 33 } 34 else if(Q.empty() == false) 35 {//到达当前层的结尾,并且不是最后一层的结尾 36 res++; 37 Q.push(""); 38 } 39 } 40 return 0; 41 } 42 };
Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) from start to end, such that:
- Only one letter can be changed at a time
- Each intermediate word must exist in the dictionary
For example,
Given:
start = "hit"
end = "cog"
dict = ["hot","dot","dog","lot","log"]
Return
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
Note:
- All words have the same length.
- All words contain only lowercase alphabetic characters.
分析:本题主要的框架和上一题是一样,但是还要解决两个额外的问题:一、 怎样保证求得所有的最短路径;二、 怎样构造这些路径
第一问题:
- 不能像上一题第二点注意那样,找到一个单词相邻的单词后就立马把它从字典里删除,因为当前层还有其他单词可能和该单词是相邻的,这也是一条最短路径,比如hot->hog->dog->dig和hot->dot->dog->dig,找到hog的相邻dog后不能立马删除,因为和hog同一层的单词dot的相邻也是dog,两者均是一条最短路径。但是为了避免进入死循环,再hog、dot这一层的单词便利完成后dog还是得从字典中删除。即等到当前层所有单词遍历完后,和他们相邻且在字典中的单词要从字典中删除。
- 如果像上面那样没有立马删除相邻单词,就有可能把同一个单词加入bfs队列中,这样就会有很多的重复计算(比如上面例子提到的dog就会被2次加入队列)。因此我们用一个哈希表来保证加入队列中的单词不会重复,哈希表在每一层遍历完清空(代码中hashtable)。
- 当某一层的某个单词转换可以得到end单词时,表示已经找到一条最短路径,那么该单词的其他转换就可以跳过。并且遍历完这一层以后就可以跳出循环,因为再往下遍历,肯定会超过最短路径长度
第二个问题:
- 为了输出最短路径,我们就要在比bfs的过程中保存好前驱节点,比如单词hog通过一次变换可以得到hot,那么hot的前驱节点就包含hog,每个单词的前驱节点有可能不止一个,那么每个单词就需要一个数组来保存前驱节点。为了快速查找因此我们使用哈希表来保存所有单词的前驱路径,哈希表的key是单词,value是单词数组。(代码中的unordered_map<string,vector<string> >prePath)
- 有了上面的前驱路径,可以从目标单词开始递归的构造所有最短路径(代码中的函数 ConstructResult)
1 class Solution { 2 public: 3 typedef unordered_set<string>::iterator HashIter; 4 vector<vector<string>> findLadders(string start, string end, unordered_set<string> &dict) { 5 // Note: The Solution object is instantiated only once and is reused by each test case. 6 queue<string> Q; 7 Q.push(start); Q.push(""); 8 bool hasFound = false; 9 unordered_map<string,vector<string> >prePath;//前驱路径 10 unordered_set<string> hashtable;//保证bfs时插入队列的元素不存在重复 11 while(Q.empty() == false) 12 { 13 string str = Q.front(), strCopy = str; 14 Q.pop(); 15 if(str != "") 16 { 17 int strLen = str.length(); 18 for(int i = 0; i < strLen; i++) 19 { 20 char tmp = str[i]; 21 for(char c = 'a'; c <= 'z'; c++) 22 { 23 if(c == tmp)continue; 24 str[i] = c; 25 if(str == end) 26 { 27 hasFound = true; 28 prePath[end].push_back(strCopy); 29 //找到了一条最短路径,当前单词的其它转换就没必要 30 goto END; 31 } 32 if(dict.find(str) != dict.end()) 33 { 34 prePath[str].push_back(strCopy); 35 //保证bfs时插入队列的元素不存在重复 36 if(hashtable.find(str) == hashtable.end()) 37 {Q.push(str); hashtable.insert(str);} 38 } 39 } 40 str[i] = tmp; 41 } 42 } 43 else if(Q.empty() == false)//到当前层的结尾,且不是最后一层的结尾 44 { 45 if(hasFound)break; 46 //避免进入死循环,把bfs上一层插入队列的元素从字典中删除 47 for(HashIter ite = hashtable.begin(); ite != hashtable.end(); ite++) 48 dict.erase(*ite); 49 hashtable.clear(); 50 Q.push(""); 51 } 52 END: ; 53 } 54 vector<vector<string> > res; 55 if(prePath.find(end) == prePath.end())return res; 56 vector<string> tmpres; 57 tmpres.push_back(end); 58 ConstructResult(prePath, res, tmpres, start, end); 59 return res; 60 } 61 62 private: 63 //从前驱路径中回溯构造path 64 void ConstructResult(unordered_map<string,vector<string> > &prePath, 65 vector<vector<string> > &res, vector<string> &tmpres, 66 string &start, string &end) 67 { 68 if(start == end) 69 { 70 reverse(tmpres.begin(), tmpres.end()); 71 res.push_back(tmpres); 72 reverse(tmpres.begin(), tmpres.end()); 73 return; 74 } 75 vector<string> &pre = prePath[end]; 76 for(int i = 0; i < pre.size(); i++) 77 { 78 tmpres.push_back(pre[i]); 79 ConstructResult(prePath, res, tmpres, start, pre[i]); 80 tmpres.pop_back(); 81 } 82 83 } 84 };
另外这一题如果不用队列来进行bfs,可能会更加方便,使用两个哈希表来模拟队列,这样还可以避免前面提到的同一个元素加入队列多次的问题,具体可以参考这篇博客
【版权声明】转载请注明出处:http://www.cnblogs.com/TenosDoIt/p/3443512.html
前言:
先说说大伙关心的工作上的事,在上家公司任了一个多月的技术经理后,和公司中止了合作关系。
主要原因在于一开始的待遇没谈的太清楚:
1:没有合同,没有公积金,连社保也没交。
2:工资的30%变成了绩效(对我还实行特例,按季度或按项目发,而且绩效只有按期完成(发)与没完成(不发))
3:税后的问题,要自己去弄发票来填。
只能说缘来的太快,份走的也太快。
对于工作上的事,一个多月的时间,从需求文档到概要文档到详细文档,到产品原型到系统架构,基本上已经走完了。
项目成员也招聘完成,开发的按我的计划稳定的进行着,所有的技术难点,我都提前解决了。
虽然人走,但后续剩下点的任务也安排好了,剩下的开发有种没了我依然一切如旧的悲凉感觉。
交待完前事,下面进入技术正题。
1:ASP.NET的模板引擎(也称视图引擎):ASPX和Razor 简单介绍
如图有两种视图引擎:
微软视图引擎的基本原理:
加载模板(aspx、cshtml)-》调用引擎解析成(语法树)-》生成CS代码-》动态编绎-》返回最终模板。
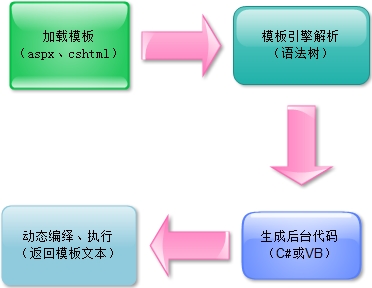
相对来说,这种模板引擎,性能相对来说会下降一些,但是搭载VS IED的智能提示,和大伙多年的开发习惯,已经占据了主流。
对于Razor有兴趣研究的,想深入的可以下载源码去慢慢慢慢研究,Razor 的源码(取自mvc5源码的razor项目):点击下载
这里也有篇Razor的原理基础文章,可供参考: http://www.cnblogs.com/JamesLi2015/p/3213642.html源码目录截图:

2:CYQ.Data 模板引擎:XHtmlAction:
XHtmlAction模板引擎的基本原理:
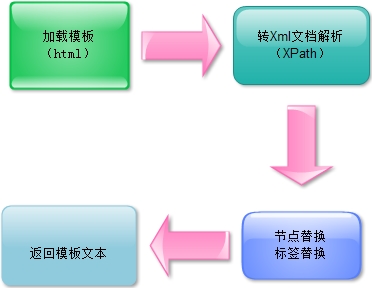
和ASP.NET自带的模板引擎比较,这里没有语法树、生成代码和动态编绎过程,因此可以得到高性能的体验。
另外相对来说,对Xml及XPath语法的操作进行了封装,简化了很多后台开发代码。当然相对缺点就是不能在模板里混合写后台代码了,换个说法是没有强大的IDE智能提示(若换个角度看,也成优点,模板和后台代码真正分离了)。
XHtmlAction实现也相当的轻量级,一共就6个文件,老少皆宜,有兴趣研究的可以看 CYQ.Data V4.55的源码:

曾经也写过两篇相关的文章:
1:多语言的(MutilLanguage),可以让你很轻松的编写多语言网站:实战篇-简单多语言的实现
2:XHmlAction的使用(以前类名叫XmlHelper,用法是一样的):CYQ.Data.Xml XmlHelper 助你更方便快捷的操作Xml/Html
除了介绍的(XmlHelper)用法,最近V5版本增加了“CMS标签替换”功能,下面介绍。
3:XHtmlAction CMS标签替换功能介绍:
3.1 这里用CYQ.Data的文本数据库来演示:
先写个函数,创建文本数据库和添加数据:
void TxtDBCreate()
{
MDataTable.CreateSchema("demo.txt", false, new string[] { "Name", "CreateTime" }, new SqlDbType[] { SqlDbType.NVarChar, SqlDbType.DateTime });
using (MAction action = new MAction("demo"))
{
for (int i = 0; i < 50; i++)
{
action.Set("Name", "Name_" + i.ToString());
action.Set("CreateTime", DateTime.Now.AddSeconds(i));
action.Insert();
}
}
}
该代码执行后,生成两个文件:demo.ts(表结构)demo.txt(json格式的表数据)

文本里的Json数据:

文本数据库相当于创建好了,配置里添加一行数据库链接请求:
<add name="Conn" connectionString="txt path={0}"/>
</connectionStrings>
3.2 项目示例代码:
弄好数据库,可以写代码了,单条数据的标签替换:
{
using (XHtmlAction xml = new XHtmlAction(true))
{
xml.Load(Server.MapPath("demo.html"));//加载html模板。
using (MAction action = new MAction("demo")) //数据库操作,操作demo表。
{
if (action.Fill(1))//查询id=1的数据
{
xml.LoadData(action.Data, "txt");//将查询的数据行赋给XHtmlAction,并指定CMS前缀
}
//xml.LoadData(action.Select());
//xml.SetForeach("divFor", SetType.InnerXml);
}
Response.Write(xml.OutXml);//输出模板
}
}
代码解答:
只要把数据行赋给模板,加一个任意前缀,之后就可以在html中任意使用:{$txt#Name} 或{$txt-CreateTime}或{$txt#ID}来代表数据的值。
'#','-'是默认的前缀分隔符号,任意使用其一都可。
{$字段名} 这个是因为大多数的模板引擎都采用这种,故采用这种通用方式。
上面的代码中,有两行是注释的,是多行数据的(表循环),方法是:LoadData(MDataTable);
如果把上面的代码注释放开,Html如下:
<html xmlns="http://www.w3.org/1999/xhtml" >
<head>
<title>{$txt#Name}</title>
</head>
<body>
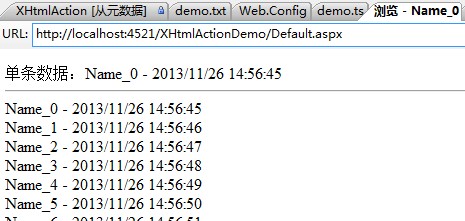
<div title="单条数据" >
单条数据:{$txt#Name} - {$txt-CreateTime}
</div>
<hr />
<div id="divFor" title="多条数据" >
{$Name} - {$CreateTime}<br />
</div>
</body></html>
最终效果输出如下图:
本Demo源码下载: 点击下载
4:XHtmlAction 关键点
1:字段前缀:
对于一个html,可能涉及到相同的字段名(同表的不同行数据,不同表的数据)需要标签替换,因此LoadData(数据行,前缀)方法需要前缀来区分。
同时前缀也可以传空"",不使用前缀(但要注释避免和其它的冲突)。
对于行的数据,是在获取xml.OutXml属性的时候才处理,因为对于标签,可以存在任意地方,因此不能以节点来处理,只能在最终输的时候,拿到html,再用正则替换。
2:表格输出:
对于表格的输出,需要获取某个节点,以对节点下的内容,进行克隆复制循环输出,由于已经存在节点,所以在xml.SetForeach的时候就处理了。
如果涉及到字段格式化,仍按SetForeach的事件处理即可。
3:示例说明:
本文及示例介绍的是标签替换的功能,节点替换的操作方式,仍和以前的操作方式一致。
总结:
对于Web开发框架,主打关键就三块:URL重写(路由)、模板引擎(视图引擎)、数据层框架(ORM)。
如果你能掌控或自由实现这三模块,你的开发方式选择就自由化很多,如果不能,你只能局域于微软给你的WebForm和MVC。
对于框架,有时候研究的再深,也不如自己写一个浅的。