SQLSERVER2012 列存储索引的简单研究和测试
SQLSERVER2012 列存储索引的简单研究和测试
看这篇文章之前可以先看一下下面这两篇文章:
列存储索引
http://www.cnblogs.com/qanholas/archive/2013/03/08/2949205.html
非聚集索引
http://www.cnblogs.com/lyhabc/p/3196484.html
还有这一篇文章
建立测试环境
先创建一张表

1 USE [pratice] 2 GO 3 IF (OBJECT_ID('TestTable') IS NOT NULL) 4 DROP TABLE [dbo].[TestTable] 5 GO 6 CREATE TABLE TestTable 7 ( 8 id INT , 9 c1 INT 10 ) 11 GO
插入1W条测试数据
1 DECLARE @i INT 2 SET @i=1 3 WHILE @i<10001 4 BEGIN 5 INSERT INTO TestTable (id,c1) 6 SELECT @i,@i 7 SET @i=@i+1 8 END 9 GO
看一下插入的记录是否足够
1 SELECT COUNT(*) FROM TestTable 2 SELECT TOP 10 * from TestTable
在C1列上创建一个列存储索引
1 CREATE NONCLUSTERED columnstore INDEX PK__TestTable__ColumnStore ON TestTable(c1)
执行计划
在上面给出的文章里提到 http://www.cnblogs.com/qanholas/archive/2013/03/08/2949205.html
下面几个SQL语句的执行计划也显示出列存储索引不会seek
(2)列存储索引不支持 SEEK
如果查询应返回行的一小部分,则优化器不大可能选择列存储索引(例如:needle-in-the-haystack 类型查询)。
如果使用表提示 FORCESEEK,则优化器将不考虑列存储索引。
1 SELECT * FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 2 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 3 SELECT c1 FROM TestTable WHERE [C1]=60 --列存储索引扫描 4 SELECT * FROM TestTable WHERE id=60 --全表扫描 5 SELECT c1 FROM TestTable --列存储索引扫描 6 SELECT * FROM TestTable --全表扫描

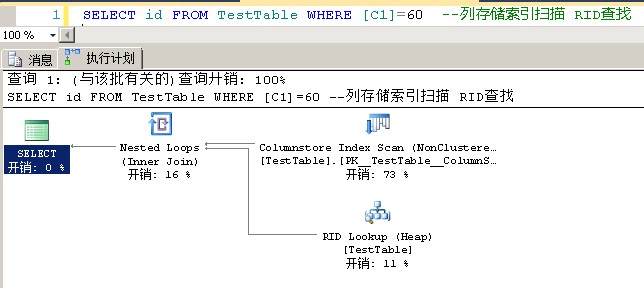
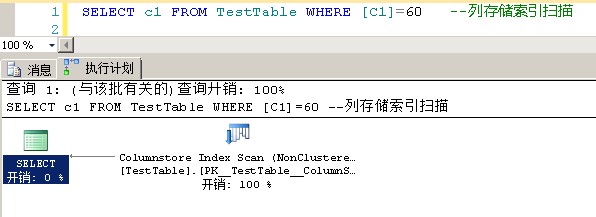



列存储索引的结构
先创建一张表保存DBCC的结果
 View Code
View Code
我们看一下列存储索引在表中建立了一些什么页面
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,TestTable,-1) ') 3 4 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
先说明一下:DBCC IND的结果
PageType 页面类型:1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID:0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 大于250就是text或image字段
由于表中的页面太多,本来想truncate table并只插入1000行记录到表,让大家看清楚一下表中的页面的,但是遇到下面错误

http://www.cnblogs.com/qanholas/archive/2013/03/08/2949205.html
文章中里提到:
(14).有列存储索引后,表变成只读表,不能进行添加,删除,编辑的操作。 insert into TestTable(c1,c2) select rand(),rand() 错误信息是这样的:由于不能在包含列存储索引的表中更新数据,INSERT 语句失败。
微软提供了三种方式来解决这个问题,这里简单介绍两种: 1) 若要更新具有列存储索引的表,先删除列存储索引,执行任何所需的 INSERT、DELETE、UPDATE 或 MERGE 操作,然后重新生成列存储索引。
2) 对表进行分区并切换分区。对于大容量插入,先将数据插入到一个临时表中,在临时表上生成列存储索引,然后将此临时表切换到空分区。对于其他更新,将主表外的一个分区切换到一个临时表中,禁用或删除临时表上的列存储索引,执行更新操作,在临时表上重新生成或重新创建列存储索引,然后将临时表切换回主表。
只能够先删除列存储索引,再truncate table了
1 DROP INDEX PK__TestTable__ColumnStore ON TestTable
truncate table,再插入1000条记录,重新建立列存储索引,看到DBCC IND的结果如下: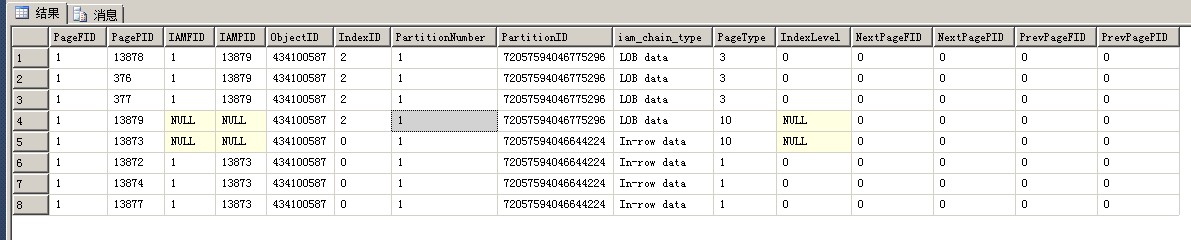
表中有10000条记录的话,表中的页面类型又增加了一种,而且可以看到,列存储索引的表中是没有索引页面的,只有LOB页面
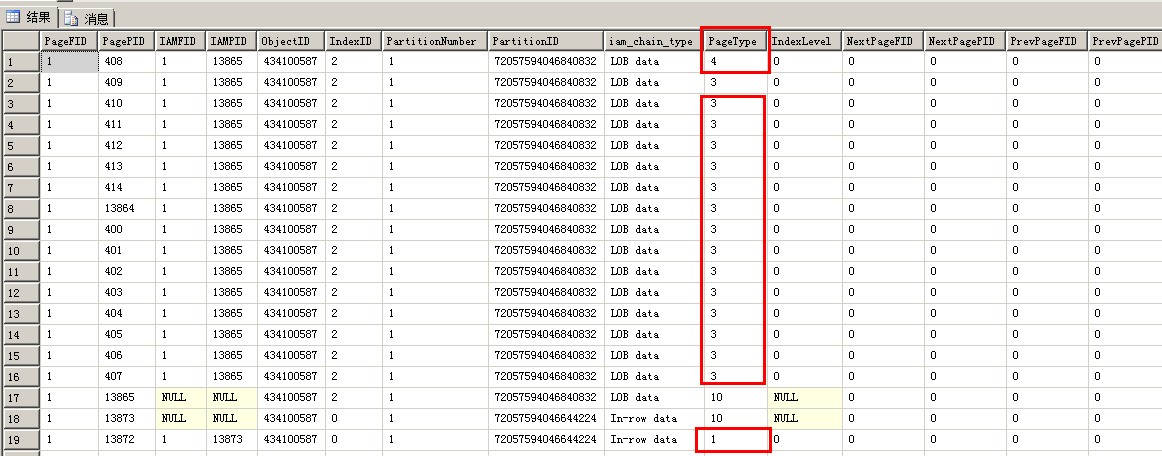
10000条记录的表比1000条记录的表多了一种页面类型:Lob_tree_page
为了避免篇幅过长,有关Lob_tree_page页面的详细内容请看我的另一篇文章
这里为什麽要用LOB页来存放索引数据呢?
本人认为因为要将数据转为二进制并压缩,所以用LOB页来存放索引数据
测试和比较
下面建立一张非聚集索引表
View Code
为什么用非聚集索引表来比较?
大家可以看一下列存储索引的建立语句
1 CREATE NONCLUSTERED columnstore INDEX PK__TestTable__ColumnStore ON TestTable(c1)
在非聚集索引上加多了一个columnstore关键字
而且列存储索引的表的页面情况跟非聚集索引表的页面情况几乎是一样的
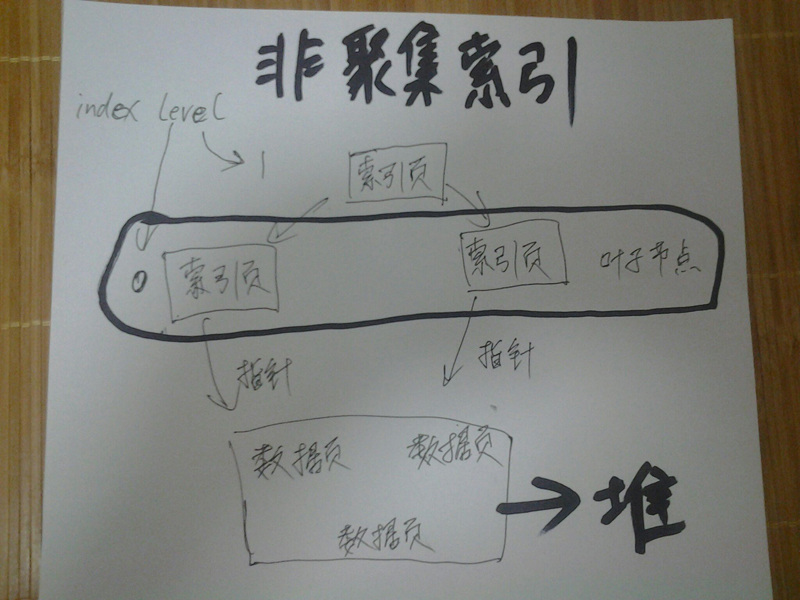
除了LOB页面,数据页面还是在堆里面的

测试结果:
1 SET NOCOUNT ON 2 SET STATISTICS IO ON 3 SET STATISTICS TIME ON 4 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 5 SQL Server 分析和编译时间: 6 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 7 表 'TestTable'。扫描计数 1,逻辑读取 37 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 8 9 SQL Server 执行时间: 10 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 11 ------------------------------------------------------------- 12 SET NOCOUNT ON 13 SET STATISTICS IO ON 14 SET STATISTICS TIME ON 15 SELECT id FROM TestTable2 WHERE [C1]=60 --索引查找 RID查找 16 SQL Server 分析和编译时间: 17 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 18 表 'TestTable2'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 19 20 SQL Server 执行时间: 21 CPU 时间 = 15 毫秒,占用时间 = 17 毫秒。 22 ----------------------------------------------------------------------------------
CPU执行时间非聚集索引要多一些
而逻辑读取非聚集索引表比列存储索引表少了37-3=34次
因为非聚集索引使用的是索引查找,找到索引页就可以了,而列存储索引还要扫描LOB页面
----------------------------------------------------------------------------------
上面是没有清空数据缓存和执行计划缓存的情况下的测试结果
下面是清空了数据缓存和执行计划缓存的情况下的测试结果
1 USE [pratice] 2 GO 3 DBCC DROPCLEANBUFFERS 4 DBCC freeproccache 5 GO 6 SET NOCOUNT ON 7 SET STATISTICS IO ON 8 SET STATISTICS TIME ON 9 SELECT id FROM TestTable2 WHERE [C1]=60 --索引查找 RID查找 10 11 12 SQL Server 分析和编译时间: 13 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 14 15 SQL Server 执行时间: 16 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 17 SQL Server 分析和编译时间: 18 CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。 19 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 20 21 SQL Server 执行时间: 22 CPU 时间 = 0 毫秒,占用时间 = 2 毫秒。 23 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 24 25 SQL Server 执行时间: 26 CPU 时间 = 0 毫秒,占用时间 = 18 毫秒。 27 SQL Server 分析和编译时间: 28 CPU 时间 = 63 毫秒,占用时间 = 95 毫秒。 29 30 SQL Server 执行时间: 31 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 32 33 SQL Server 执行时间: 34 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 35 36 SQL Server 执行时间: 37 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 38 SQL Server 分析和编译时间: 39 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 40 表 'TestTable2'。扫描计数 1,逻辑读取 28 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 41 42 SQL Server 执行时间: 43 CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。 44 --------------------------------------------------------------------- 45 USE [pratice] 46 GO 47 DBCC DROPCLEANBUFFERS 48 DBCC freeproccache 49 GO 50 SET NOCOUNT ON 51 SET STATISTICS IO ON 52 SET STATISTICS TIME ON 53 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 54 55 SQL Server 分析和编译时间: 56 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 57 58 SQL Server 执行时间: 59 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 60 SQL Server 分析和编译时间: 61 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 62 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 63 64 SQL Server 执行时间: 65 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 66 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 67 68 SQL Server 执行时间: 69 CPU 时间 = 0 毫秒,占用时间 = 13 毫秒。 70 SQL Server 分析和编译时间: 71 CPU 时间 = 0 毫秒,占用时间 = 26 毫秒。 72 73 SQL Server 执行时间: 74 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 75 76 SQL Server 执行时间: 77 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 78 79 SQL Server 执行时间: 80 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 81 SQL Server 分析和编译时间: 82 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 83 表 'TestTable'。扫描计数 1,逻辑读取 40 次,物理读取 1 次,预读 68 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 84 85 SQL Server 执行时间: 86 CPU 时间 = 0 毫秒,占用时间 = 41 毫秒。
可以看到列存储索在执行时间上占优势,但是在IO上比非聚集索引差一点点
列存储索引所申请的锁
1 USE [pratice] 2 GO 3 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ 4 GO 5 6 BEGIN TRAN 7 SELECT id FROM TestTable WHERE [C1]=60 --列存储索引扫描 RID查找 8 9 --COMMIT TRAN 10 11 USE [pratice] --要查询申请锁的数据库 12 GO 13 SELECT 14 [request_session_id], 15 c.[program_name], 16 DB_NAME(c.[dbid]) AS dbname, 17 [resource_type], 18 [request_status], 19 [request_mode], 20 [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, 21 p.[index_id] 22 FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p 23 ON a.[resource_associated_entity_id]=p.[hobt_id] 24 LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] 25 WHERE c.[dbid]=DB_ID('pratice') AND a.[request_session_id]=@@SPID ----要查询申请锁的数据库 26 ORDER BY [request_session_id],[resource_type]
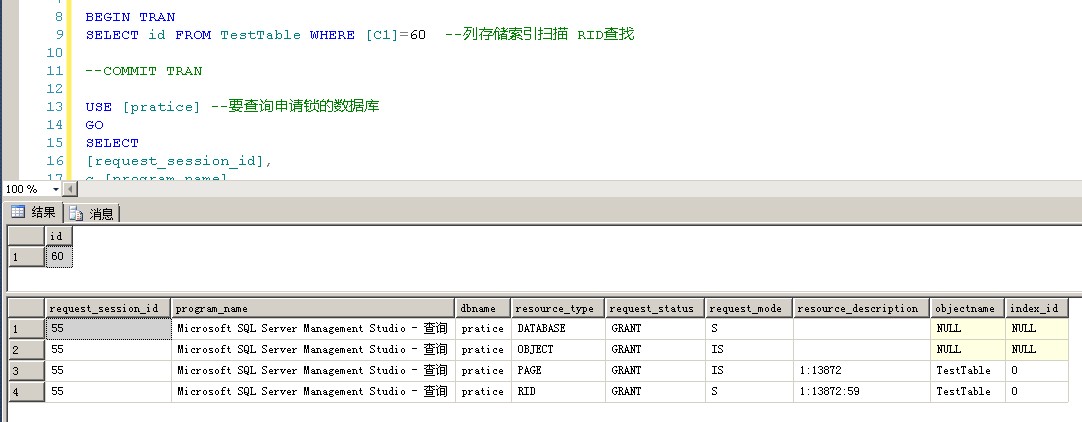

可以看到虽然是列存储索引扫描,但是也没有在LOB页面申请锁,只是在普通数据页面和真正的数据行上申请了锁
使用列存储索引,阻塞的机会也减少了
最后,如有不对的地方,欢迎大家拍砖哦o(∩_∩)o
NHibernate ConfORM Mapping
前言
昨天写了一篇fluent nhibernate通过约定的代码映射方式,NH在3.0版本以后已经集成了conform的代码映射方式,一直没注意也没使用过,今天试试怎么样。
步骤
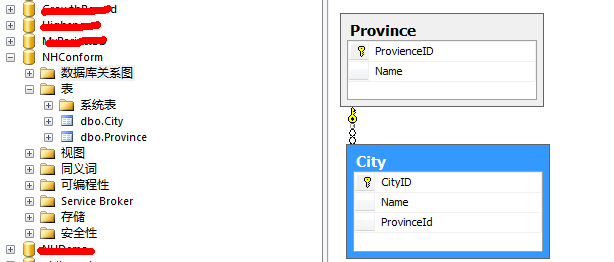
1、通过conform方式生成如下数据库架构

2、添加项目对NH3.3的引用,3.0以后已经集成代码映射的方式在using NHibernate.Mapping.ByCode.Conformist;using NHibernate.Mapping.ByCode;命名空间中。
编写持久化对象:
public class Province { public Province() { Cities = new List<City>(); } virtual public int Name{get;set;} virtual public int ProvienceID{get;set;} virtual public IList<City> Cities { get; set; } } public class City { virtual public int CityID{get;set;} virtual public int Name{get;set;} virtual public Province Province { get; set; } }
集成using NHibernate.Mapping.ByCode.Impl.CustomizersImpl;命名空间下的ClassMapping<T>来实现代码配置持久化对象映射
Provience映射代码:
public class ProvinceMap : ClassMapping<Province> { public ProvinceMap() { Id(p => p.ProvienceID, map => map.Generator(Generators.Assigned)); Property(p => p.Name); Bag(p => p.Cities, map => map.Key(k => k.Column("ProvinceId")), ce => ce.OneToMany()); } }
CIty类映射代码:
public class CityMap : ClassMapping<City> { public CityMap() { Id(p => p.CityID, map => map.Generator(Generators.Assigned)); Property(p => p.Name); ManyToOne(p => p.Province, map => map.Column("ProvinceId")); } }
3、NH配置
首先我们添加一个数据库连接的配置文件:
<?xml version="1.0" encoding="utf-8" ?> <configuration> <connectionStrings> <add name="NHConform" connectionString="Data Source=(local);initial catalog=NHConform;Integrated Security=SSPI"/> </connectionStrings> </configuration>
编写一个配置NH的类:
public static class NHContext { public static Configuration NHConfiguration { get; set; } public static ISessionFactory SessionFactory { get; set; } public static void AppConfigure() { #region NHibernate配置 NHConfiguration = ConfigureNHibernate(); SessionFactory = NHConfiguration.BuildSessionFactory(); #endregion } private static Configuration ConfigureNHibernate() { var configure = new Configuration(); configure.SessionFactoryName("BuildIt"); configure.DataBaseIntegration(db => { //配置数据库连接 db.Dialect<MsSql2008Dialect>(); db.Driver<SqlClientDriver>(); db.KeywordsAutoImport = Hbm2DDLKeyWords.AutoQuote; db.IsolationLevel = IsolationLevel.ReadCommitted; db.ConnectionStringName = "NHConform"; db.Timeout = 10; db.LogFormattedSql = true; db.LogSqlInConsole = true; db.AutoCommentSql = true; }); var mapping = GetMappings(); //在Configuration中添加HbmMapping configure.AddDeserializedMapping(mapping, "NHConfORM"); //配置元数据 SchemaMetadataUpdater.QuoteTableAndColumns(configure); return configure; } public static HbmMapping GetMappings() { var mapper = new ModelMapper(); mapper.AddMappings(Assembly.GetAssembly(typeof(ProvinceMap)).GetExportedTypes()); var mapping = mapper.CompileMappingForAllExplicitlyAddedEntities(); return mapping; } }
4、测试映射配置生成数据库架构,建了一个控制台程序没有写单元测试,生成数据库架构的代码
public static void Create() { NHContext.AppConfigure(); new SchemaExport(NHContext.NHConfiguration).Create(false, true); }
在控制台主程序中执行Create()方法,生成数据库并生成如上图的数据库关系图。
测试删除数据库:
public static void Drop() { NHContext.AppConfigure(); new SchemaExport(NHContext.NHConfiguration).Drop(false, true); }
执行Drop()方法以后数据库结构就被删除了,此处就不截图了。
结语
NH自带的代码映射方式同样支持编写规则映射,这样在项目中会节约很多的时间,相比直接感觉还是用这个比较直接了,毕竟不需要引入第三方类库。
此映射方式初次使用,若有不合理的地方,欢迎批评指正。