HTTP报文
http报文是在http应用程序之间发送的数据块,这些数据块以一些文本形式的元信息。
请求报文从客户端流入服务器,向服务器请求数据,服务器响应请求,响应报文从服务器流出,回到客户端。
这就构成了一个事务.报文总是向下流动,所有的报文的发送者都在上游,所有的报文接受者都在下游。所以无论是浏览器还是服务器,他们都既可以在上游,也可以在下游。这个是用火狐浏览器得到的一个报文内容
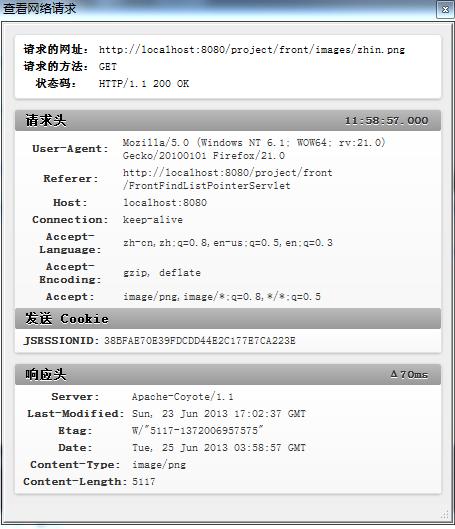
报文由以下的部分组成:
起始行(start line)
首部(header)
主体(body)
接下来详细看看报文的内容。
请求报文格式:
<method> <request-URL> <version>
<headers>
<entity-body>
第一行是报文请求的起始行,它说明了这个报文要做什么。这好像是我们去吃饭,告诉服务员,我们要吃什么。
现在再来看看第一篇中请求报文的例子:
Get /index.html HTTP/1.1
Host: 192.168.170.171
Accept: *
第一行中,第一个词 get 是HTTP中规定的一个请求的方法,它会获取一个文档。下面列出几种http方法:
|
方法 |
描述 |
是否有主体 |
|
get |
获取一份文档 |
否 |
|
head |
只获取文档首部 |
否 |
|
post |
向服务器发送需要处理的页面 |
是 |
|
put |
将请求主体部分储存在服务器上 |
是 |
|
trace |
对报文进行追踪 |
否 |
|
options |
决定可以在服务器上执行哪些方法 |
否 |
|
delete |
从服务器上删除一份文档 |
否 |
在<method>之后, 是请求资源的路径,也就是我们要点的菜了,本行最后是http的一个版本号。
在请求报文的第二行起,是报文的首部,这里放置的都是一些附加信息,就像这里的
Host: 192.168.170.171 说明了服务器的位置。
Accept: * 说明了客户端期待接受的文件类型。这个很重要。比如我想去下载一张图片,结果服务器却给你显示了一张图片,这是客户端不期待得到的结果。所以,这个信息很重要。它让http更准确地工作。这里的文件类型是指一个MIME类型,如:text/html;text/xml等。
请求部分还包括了一些,对我们开发很有帮助的内容。比如:
Client-IP 提供了客户端的IP地址
UA-color 提供了客户端采用的显示色信息(比如一家网站对视网膜屏幕做优化就可以从这里得到信息)
UA-OS 提供了客户端采用的操作系统
在http报文中第三部分并不是都需要的。像表单中要传送的内容都会放在这里被发送到服务器中去。
接下来分析下响应报文,服务员要上菜啦!

这个是响应报文的格式:
<version> <status> <reason-phrase>
<headers>
<entity-body>
其实可以发现 响应报文的格式和请求报文的格式是差不多的。只是起始行有所区别罢了。
起始行中version说明了http 的版本,status,reason-phrase是告诉客户端,对于刚才的请求,发生了什么。他们唯一的不同就是 status是数字,它给机器看,reason-phrase是字母,它是给人看的。通过这些状态码,客户端将反馈给我们,上次的请求是不是成功了。
这里我们可以详细地了解下status 状态码。没有状态码,我就不知道我点的鱼到底怎么样了。下面是状态码的分类
|
1XX |
信息提示 |
|
2XX |
成功 |
|
3XX |
重定向 |
|
4XX |
客户端错误 |
|
5XX |
服务器错误 |
我们最想看得到的状态码就是200了,这意味着我的请求成功。而404是我们最常见的错误,它告诉我们,我们请求的资源找不到了,这一般都是因为代理服务器缓存过期。如果是500的错误,那么我们只能联系网站的管理员解决问题了。

Header部分则告诉客户端,它请求的这个页面一些相关信息。比如这个响应产生的时间,实体部分的长度。实体部分的内容是什么类型的。
这里我们可以看看几个常见的响应首部:
|
首部 |
描述 |
|
server |
服务器所用的版本和名称 |
|
age |
响应持续的时间 |
|
date |
请求的时间 |
|
Last-Modified |
页面上次被修改的时间(和date进行比较,可以确定这是否是最新页面) |
|
Connection:close |
这就是上一篇中讲的通知客户端关闭连接了 |
|
Content-Type:text/html; charset=UTF-8 |
表示这次发送的响应信息的主体MIME格式,和字符编码。(MIME类型,我会在随后的笔记中说明) |
|
Content-Base |
这个是用于解析主体中相对URL的基础URL |
这里只列出了极少数的部分,因为完整的首部资料实在是太庞大了。
主体部分自然就是我们希望获得的html页面了。这也是浏览器最关心的部分,我们由此看到了一个完整的页面。
报文中的内容是可以控制的,我们可以通过控制这些内容,解决类似乱码、缓存等问题。从而提高自己的开发效率。