hadoop之NameNode,DataNode,Secondary NameNode
一:NameNode
1:主要功能提供名称查询服务,内嵌jetty服务器;NameNode主要保存metadata信息;
2:metadata信息包括:文件的权限,某一上传文件包含哪些Block块,Bolck块有保存在哪些DataNode上面;
3:DataNode在启动时候也会上报block信息(此功能一些作用后面会写到);
4:NameNode的metadata信息在启动后会加载到内存
5:metadata存储到磁盘的文件为镜像形式fsimage,需要注意的是block的位置信息不保存在fsimage,block
在DataNode启动时上报到DataNode加载到内存;
6:metadata中文件块存储记录如下
file.txt = block1:DN1,DN3,DN6 block2:DN2,DN3,DN5 block3:DN1,DN3,DN4
解释:一个文件分成三个块,每个块分配到三个DataNode上面
metadata物理存储

7:NameNode对内容和I/O进行集中式管理,是个单点,发生故障容易集群崩溃,每个NameNode能够带动4000节点
思考问题:百度有两万节点,是怎么处理的呢?
NameNode之间进行通讯,解决两万集群问题。
二:DataNode
1:保存Block块信息;
2:DataNode启动时,DataNode向NameNode报告block信息
3:通过向NameNode发送心跳与其保持与其联系(三秒一次),如果10分钟没有收到心跳,则将其block拷贝到
其他节点。
4:分布式情况下,一台服务器都会运行一个DataNode
5:替换Block操作,如果一个DataName接受了一个Block替换请求,那么这个请求包含了这个Block所在源
NameNode,当前节点向源节点发送拷贝请求,进行拷贝
三:Secondary Namenode
有人翻译为第二NameNode,我认为翻译为辅助NameNode更为合理
1:主要工作保存namenode中对HDFS metadata的信息的备份
2:主要工作帮助NameNode合并edit log,减少NameNode的启动时间
3:Secondary Name合并Nodeedit log过程如图所示
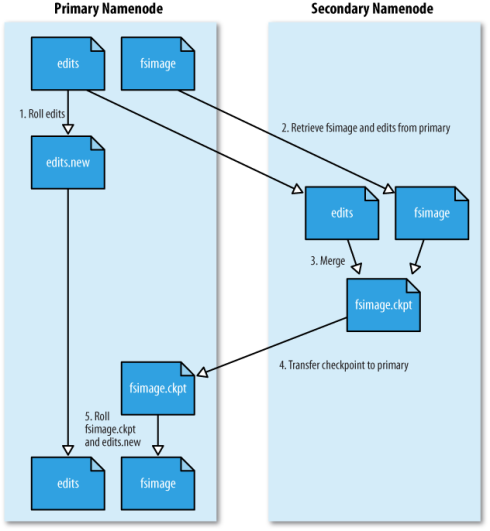
解释:SecondaryNameNode会周期性的将EditLog进行合并,合并原因:
1:editlog到达某一值时对其进行合并;
2:每隔一段时间对其进行合并;
将记录HDFS的editlog与其上一次合并后存在的fsimage进行合并到fsimage.checkpoint,然后清空
editlog,将checkpoint拷贝到NameNode
core-site.xml:这里有2个参数可配置
<property> <name>fs.checkpoint.period</name> <value>3600</value> </property> <property> <name>fs.checkpoint.size</name> <value>67108864</value> </property>
4:secondary NameNode 可以作为NameNode的冷备份:
将本地保存的fsimage(镜像)导入;
修改所有cluster的所有DN的master地址;
修改所有client端NameNode地址;
由于我们的产品经常是由多个部门合作开发的,常常会用到其他部门提供的http数据接口。比如我们可能在一个产品中接入论坛部门的功能、接入SNS部门的功能、或者接入搜索部门的功能等等。这种情况下,我们会频繁请求其他部门的接口。如果通过域名的方式来访问这些接口的话,会因为DNS解析造成一些性能上的浪费。
先来看看DNS解析的流程:

可见,在没有本地缓存的情况下,这个过程是比较繁琐的。由于这些接口都是在公司内部服务器之间调用,我们是可以知道接口对应的IP地址的,因此,完全可以通过指定IP来避免域名解析的过程。实现起来也很简单,只要在/etc/hosts中指定IP即可,比如针对上面这个图片内容,可以这样配置:
1.1.1.1 163.com |
就这样一个小小的改动,就能带来不少改善。
分类: Hadoop