一个关于兑换零钱的豆瓣笔试题
前几天做了个豆瓣笔试题,时间是90分钟,共有6题,要做4道,难度如果没看过类似的着实做起来太慢了。由于豆瓣上面的邮件说不要泄露(还有人会在后期笔试),所以拖到现在才写博客。我先把题目贴出来:将10000块钱兑换成由5000块、2000块、1000块、500块、100块、50块、10块、5块、1块的组成的零钱,问有多少种兑换方式?
这个题,如果朋友们没做过,或许最开始就跟我一样,钱有9种,就做个9重循环,各层累加,当总钱等于10000时就计数器加1,这样是很简单没错,可惜在这数据量的前提下,我用c跑了5、6分钟也没跑出来,于是中止了这种天真的想法。但是还是有必要提下完成这种笨方法时需要用到的基础数据结构,后面我们会对它们进行改进:
一个用于记录各种钱(金额)的数据:y[9];
一个用于统计各种钱(数量)的数组:x[9],初始为0;
一个用于标示各种钱(数量上限)的数组:z[9];
一个用于统计从父循环[i]进入子循环[i+1]时(总金额)的数组:sum[9],i= 0 to 8;这里我需要重点说明,这个数组是必然需要的,一定得保存上层循环进入下层循环时的初始总金额数,否则当下层循环[i+1]执行完毕返回[i]时就无法知道[i]循环内正确的总金额初值了(除非你把[ 0 ~ i-1 ]层的都算一次加起来)。
接下来,我讲下想到的几个优先考虑的改进:
1、最外层循环应该是最大的数,也就是5000块,内层的依次递减。
这种方式可以使步进更大,而且与后面的第3点配合是非常优秀的省时方法,于是令y[] = {5000,2000,1000,500,100,50,10,5,1},z[] = {3,6,11,21,101,201,1001,2001,10001};
2、各层循环应该增加临界条件,当发现总数大于或等于时应该返回上层循环。
如果只是按照z[]中的极限临界条件来做循环,明显会有非常多的无用功,所以应该在各层循环内部,判断总钱数是否已经大于、等于10000,如果大于就break到上层循环,如果等于就先计数器加1,再返回上层循环。
3、最底层循环不执行(1块钱)
前面i = 0 to 7层循环分别把5000、2000、1000、500、100、50、10、5块的都算过了,等到了i=8层,也就是算1块钱的数量时就可以直接跳过了,因为反正会有一个数量能满足累加和正好等于10000,所以前面实际上的x[]、y[]、z[]的大小都只要8就行了。这一点可以把循环次数上限最大的(10000次)的那重循环给省略掉,能大大加快计算时间,这时循环由9重循环减到8重。
经过上面3点改进,心想这下应该快了吧,哪知道也花了两分多钟才出结果,仔细思考,觉得最大的问题还是在第2点,临界条件的判断上,使用2中的方法,会导致各层循环都有判断操作(大于、等于、小于),会影响执行效率,这是需要改善的问题,目前来说,第2点的实现方式有三种:

1 // 方式1 2 ... 3 for (x[4]=0;x[4]<z[4];++x[4]) 4 { 5 sum[4]=sum[3]+x[4]*y[4]; 6 if (sum[4]<10000) ; 7 else if (sum[4]==10000) { ++count; break; } 8 else break; 9 for (x[5]=0;x[5]<z[5];++x[5]) 10 { 11 ... 12 } 13 } 14 ... 15 16 // 方式2 17 ... 18 for (x[4]=0;x[4]<z[4];++x[4]) 19 { 20 sum[4]=sum[3]+x[4]*y[4]; 21 if (sum[4]>10000) break; 22 for (x[5]=0;x[5]<z[5];++x[5]) 23 { 24 ... 25 } 26 } 27 ... 28 29 // 方式3 30 ... 31 for (x[4]=0;x[4]<z[4];++x[4]) 32 { 33 sum[4]=sum[3]+x[4]*y[4]; 34 if (sum[4]==10000) { ++count; break; } 35 else if(sum[6]>10000) break; 36 for (x[5]=0;x[5]<z[5];++x[5]) 37 { 38 ... 39 } 40 } 41 ... 42 43 // i=7层代码 44 ... 45 for (x[7]=0;x[7]<z[7];++x[7]) 46 { 47 sum[7]=sum[6]+x[7]*y[7]; 48 if (sum[7]>10000) break; 49 ++count; 50 } 51 ...
这三种都是属于换汤不换药的,它们在最后一层循环执行的代码是一模一样的,在i=0 to 6层执行的判断稍微有点区别,可以从下图看出执行的效率区别:
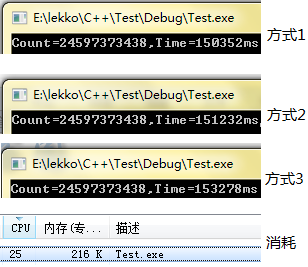
它们的结果是一致的,但是虽然方式1代码量最多,但是速度却还是快些的(毕竟sum<10000的可能性最大了),不过在这么大的基数前面,这也是浮云了,都在2分半钟的时候才计算完。为了更好的优化第2点,提出下面的第4点改进:
4、改变循环临界条件,通过当前循环来计算下层循环的结束值
前面由于是用z[]来保存各层循环的执行上限,然后再在循环内判断总值是否超过,影响了执行效率,所以考虑:在[i]层循环时,根据当前累积初值sum[i]和下层循环的零钱面值y[i+1]来计算下层循环[i+1]的结束条件z[i+1],这样就不需要在循环内部不停地进行判断了,改进方式为:
1 // 方式4 2 ... 3 for (x[4]=0;x[4]<z[4];++x[4]) 4 { 5 sum[4]=sum[3]+x[4]*y[4]; 6 z[5] = (10000-sum[4])/y[5]+1; 7 for (x[5]=0;x[5]<z[5];++x[5]) 8 { 9 ... 10 } 11 } 12 ...
一执行,恩,果断快了不少,只花了一分钟多一点便得到了结果:
至此,我能想到的改进就没有了,因为没看过类似的题,花了不少时间,如果有朋友有更好的方法,欢迎指教讨论(ps:豆瓣招的Python程序员,后来试用Python解这个题目的效率真心比c慢十几倍,反正大概十分钟过去了还没算完,我就手动关了,有耐心的朋友可以去试试,告诉我到底要多久)。最后附上源代码:
 大数分解
大数分解1 #include <stdio.h> 2 #include <time.h> 3 4 int main() 5 { 6 clock_t start,end; 7 unsigned long long count = 0; 8 int x[8],sum[8],z[8]; 9 int y[8]={5000,2000,1000,500,100,50,10,5}; 10 start = clock(); 11 for (x[0]=0,z[0]=3;x[0]<z[0];++x[0]) 12 { 13 sum[0]=x[0]*y[0]; 14 z[1] = (10000-sum[0])/y[1]+1; 15 for (x[1]=0;x[1]<z[1];++x[1]) 16 { 17 sum[1]=sum[0]+x[1]*y[1]; 18 z[2] = (10000-sum[1])/y[2]+1; 19 for (x[2]=0;x[2]<z[2];++x[2]) 20 { 21 sum[2]=sum[1]+x[2]*y[2]; 22 z[3] = (10000-sum[2])/y[3]+1; 23 for (x[3]=0;x[3]<z[3];++x[3]) 24 { 25 sum[3]=sum[2]+x[3]*y[3]; 26 z[4] = (10000-sum[3])/y[4]+1; 27 for (x[4]=0;x[4]<z[4];++x[4]) 28 { 29 sum[4]=sum[3]+x[4]*y[4]; 30 z[5] = (10000-sum[4])/y[5]+1; 31 for (x[5]=0;x[5]<z[5];++x[5]) 32 { 33 sum[5]=sum[4]+x[5]*y[5]; 34 z[6] = (10000-sum[5])/y[6]+1; 35 for (x[6]=0;x[6]<z[6];++x[6]) 36 { 37 sum[6]=sum[5]+x[6]*y[6]; 38 z[7] = (10000-sum[6])/y[7]+1; 39 for (x[7]=0;x[7]<z[7];++x[7]) 40 { 41 ++count; 42 } 43 } 44 } 45 } 46 } 47 } 48 } 49 } 50 end = clock(); 51 printf("Count=%lld,Time=%ldms",count,end-start); 52 getchar(); 53 }
转载请注明原址:http://www.cnblogs.com/lekko/archive/2013/04/05/3000403.html