SQL Server 2008 高可用性视频(一)--纵览与对比
做数据库的朋友都知道, 其实数据库的工作大致可以分为三类: 数据库设计与开发, 数据库管理, 数据库商业智能. 其中数据库管理的工作大部分是由DBA在做, DBA们除了要保证正常的数据库运行, 还要采取必要措施提升数据库的性能, 比如数据库的性能优化, 以及保证数据库系统的高可用性. 我在前面发了几篇对SQL Server数据库进行调优的文章, 下面会再开一个SQL Server高可用性解决方案的主题.
笔者工作中也有很多场景会用到HA, 但因为没有进行过系统的学习, 所以处理HA问题时总觉得捉襟见肘. 索性, 就下决心把这几种高可用性解决方案都系统地过了一遍. 一下手, 才知道, 除了枯燥的MSDN文档, 完整讲解HA知识点的文档真心不多, 视频更是找不到, 估计很多朋友都跟我有相同的感受. 好吧, 那我就自己学, 自己配, 自己录, 把知识点及配置的过程都以视频形式记录下来, 以后用到的时候好复习, 有机会发到网上, 其他朋友看到后也更容易接受. 需要提一下的是, 这期间, 刚好有个IT学习网站让帮忙做些数据库视频, 所以中间会有一些他们的Logo, 希望大家不要介意.
Logshipping(日志传送)
Data Mirrroring(镜像)
Replication(复制)
Cluster(群集)
下面正式开练, 先贴上第一节:
SQL逻辑查询解析(补充篇)
本文目录
表操作符
JOIN
APPLY
PIVOT
UNPIVOT
OVER子句
集合操作符
在我的上一篇博客“SQL逻辑查询解析”中,我们详细讲述了SQL逻辑查询处理的各个步骤以及SQL语言的一些重要知识。为了SQL逻辑查询处理的完整性,在本篇中,我们会了解到SQL逻辑查询处理的更多内容,以作为对前一篇博客的补充。包括表操作符(JOIN,APPLY,PIVOT和UNPIVOT),OVER子句以及集合操作符(UNION,EXCEPT和INTERSECT)。
表操作符
从SQL SERVER 2008开始,SQL查询中支持四种表操作符:JOIN,APPLY,PIVOT和UNPIVOT。其中,APPLY,PIVOT和UNPIVOT并非ANSI标准操作符,而是T-SQL中特有的扩展。
下面列出了这四个表操作符的使用格式:

(J) <left_table_expression> {CROSS | INNER | OUTER} JOIN <right_table_expression> ON <on_predicate> (A) <left_table_expression> {CROSS | OUTER} APPLY <right_table_expression> (P) <left_table_expression> PIVOT (<aggregate_func(<aggregation_element>)> FOR <spreading_element> IN(<target_col_list>)) AS <result_table_alias> (U) <left_table_expression> UNPIVOT (<target_values_col> FOR <target_names_col> IN(<source_col_list>)) AS <result_table_alias>
JOIN
在前一篇中,我们已经对JOIN进行了比较详细的描述,详情请参阅:SQL逻辑查询解析
简单来说,它包含如下三个子步骤:(1-J1) 笛卡儿积(Cross Join), (1-J2) 应用ON条件, (1-J3) 添加外部数据行。
本篇会对另外三个表操作符进行讲解。
APPLY
按类型不同,APPLY操作符包含如下一个或全部二个步骤:
- A1:对左表的数据行应用右表表达式
- A2:添加外部数据行
APPLY操作符对左表的每一行应用右表表达式,并且,右表表达式可以引用左表的列。对于左表的每一行,右表表达式都会运行一遍,以获得一个与该行相匹配的集合并与之联结,结果加入返回数据集。CROSS APPLY和OUTER APPLY都包含步骤A1,但只有OUTER APPLY才包含步骤A2。对于左表的输入行,如果右表表达式返回空,那么CROSS APPLY不会返回外部行(左表当前行),而OUTER APPLY则会返回它,并且右表表达式的相关列为NULL。
比如,下面的查询为每个customer返回两个order ID最大的order:
SELECT C.customerid, C.city, A.orderid FROM dbo.Customers AS C CROSS APPLY (SELECT TOP (2) O.orderid, O.customerid FROM dbo.Orders AS O WHERE O.customerid = C.customerid ORDER BY orderid DESC) AS A;
查询返回如下数据:

可以看到FISSA并没有出现在结果集中,因为表表达式A对于该数据行返回空集,如果我们希望返回那些没有任何order的customer,则需要使用OUTER APPLY,如下所示:
SELECT C.customerid, C.city, A.orderid FROM dbo.Customers AS C OUTER APPLY (SELECT TOP (2) O.orderid, O.customerid FROM dbo.Orders AS O WHERE O.customerid = C.customerid ORDER BY orderid DESC) AS A;
查询返回如下数据:

PIVOT
PIVOT操作符允许我们对行和列中的数据进行旋转和透视,并执行聚合计算。
示例数据
请使用如下Script创建示例数据:
CREATE TABLE dbo.OrderValues ( orderid INT NOT NULL PRIMARY KEY, customerid INT NOT NULL, empid VARCHAR(20) NOT NULL, orderdate DATETIME NOT NULL, val NUMERIC(12,2) ); INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1000, 100, 'John', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1001, 100, 'Dick', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1002, 100, 'James', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1003, 100, 'John', '2006/02/12', 200) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1004, 200, 'John', '2007/03/12', 300) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1005, 200, 'John', '2008/04/12', 400) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1006, 200, 'Dick', '2006/02/12', 500) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1007, 200, 'Dick', '2007/01/12', 600) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1008, 200, 'Dick', '2008/01/12', 700) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1009, 200, 'Dick', '2008/01/12', 800) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1010, 200, 'James', '2006/01/12', 900) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1011, 200, 'James', '2007/01/12', 1000)
选择该表的所有数据,如下所示:
SELECT * FROM dbo.OrderValues
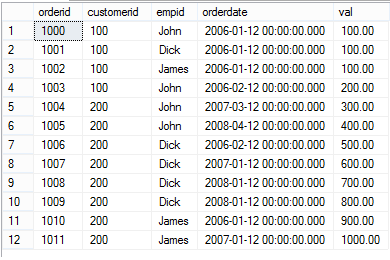
现在加入我们想知道每个employee在每一年完成的订单总价。下面的PIVOT查询能够让我们获得如下的结果:每一行对应一个employee,每一列对应一个年份,并且计算出相应的订单总价。
SELECT * FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV PIVOT(SUM(val) FOR orderyear IN([2006],[2007],[2008])) AS P;
这个查询产生的结果如下所示:

不要被子查询产生的派生表OV迷惑了,我们关心的是,PIVOT操作符获得了一个表表达式OV作为它的左输入,该表的每一行代表了一个order,包含empid, orderyear和val(订单价格)。
PIVOT逻辑处理步骤解析
PIVOT操作符包含如下三个逻辑步骤:
- P1:分组
- P2: 扩展
- P3: 聚合
第一个步骤其实是一个隐藏的分组操作,它基于所有未出现在PIVOT子句中的列进行分组。上例中,在输入表OV中有三个列empid, orderyear, val,其中只有empid没有出现在PIVOT子句中,因此这里会按empid进行分组。
PIVOT的第二个步骤会对扩展列的值进行扩展,使其属于相应的目标列。逻辑上,它使用如下的CASE表达式为IN子句中指定的每个目标列进行扩展:
CASE WHEN <spreading_col> = <target_col_element> THEN <expression> END
在我们的示例中,会应用下面三个表达式:
CASE WHEN orderyear = 2006 THEN val END, CASE WHEN orderyear = 2007 THEN val END, CASE WHEN orderyear = 2008 THEN val END
这样,对于每个目标列,只有在数据行的orderyear与之相等时,才返回相应的值val,否则返回NULL,从而实现了数据值到相应目标列的分配和扩展。
PIVOT的第三步会使用指定的聚合函数对每一个CASE表达式进行聚合计算,生成结果列。在我们的示例中,表达式相当于:
SUM(CASE WHEN orderyear = 2006 THEN val END) AS [2006], SUM(CASE WHEN orderyear = 2007 THEN val END) AS [2007], SUM(CASE WHEN orderyear = 2008 THEN val END) AS [2008]
综合上述三个步骤,我们的示例PIVOT查询在逻辑上与下面的SQL查询相同:
SELECT empid, SUM(CASE WHEN orderyear = 2006 THEN val END) AS [2006], SUM(CASE WHEN orderyear = 2007 THEN val END) AS [2007], SUM(CASE WHEN orderyear = 2008 THEN val END) AS [2008] FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV GROUP BY empid
UNPIVOT
UNPIVOT是PIVOT的反操作,它把数据从列旋转到行。
示例数据
在讲述UNPIVOT的逻辑处理步骤之前,让我们先运行下面的Script来创建示例数据表dbo.EmpYearValues,结果如下:
SELECT * INTO dbo.EmpYearValues FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV PIVOT(SUM(val) FOR orderyear IN([2006],[2007],[2008])) AS P; SELECT * FROM dbo.EmpYearValues
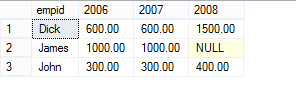
我将会使用下面的示例查询来描述UNPIVOT操作符的逻辑处理步骤:
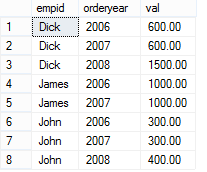
SELECT empid, orderyear, val FROM dbo.EmpYearValues UNPIVOT(val FOR orderyear IN([2006],[2007],[2008])) AS U;
这个查询会对employee每一年(表中IN子句中的每一列)的值分割到单独的数据行,生成如下结果:
UNPIVOT逻辑处理步骤解析
UNPIVOT操作符包含如下三个逻辑处理步骤:
- U1: 生成数据副本
- U2: 抽取数据
- U3: 删除带NULL值的行
第一步会生成UNPIVOT输入表的数据行的副本(在我们的示例中为dbo.EmpYearValues)。它会为UNPIVOT中IN子句定义的每一列生成一个数据行。因为我们在IN子句中有三列,所以会为每一行生成三个副本。新生成的虚表会包含一个新数据列,该列的列名为IN子句前面指定的名字,列值为IN子句中指定的列表的名字。对于我们的示例,该虚表如下所示:

第二步会为UNPIVOT的当前行从原始数据列中(列名与当前orderyear的值关联)抽取数据,用于存放抽取数据的列名是在FOR子句之前定义的(我们的示例中为val)。这一步返回的虚表如下:

第三步会消除结果列(val)中值为NULL的数据行,结果如下:
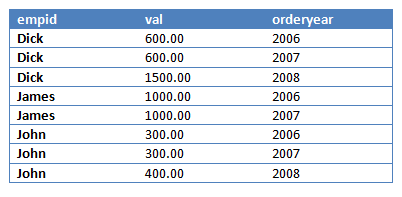
OVER子句
OVER子句用于支持基于窗口(window-based)的计算。我们可以随聚合函数一起使用OVER子句,它同时也是四个分析排名函数(ROW_NUMBER、RANK、DENSE_RANK和NTILE)的必要元素。OVER子句定义了数据行的一个窗口,而我们可以在这个窗口上执行聚合或排名函数的计算。
在我们的SQL查询中,OVER子句可以用于两个逻辑阶段:SELECT阶段和ORDER BY阶段。这个子句可以访问为相应逻辑阶段提供的输入虚表。
在下面的示例中,我们在SELECT子句中使用了带COUNT聚合函数的OVER子句:
SELECT orderid, customerid, COUNT(*) OVER(PARTITION BY customerid) AS numorders FROM dbo.Orders
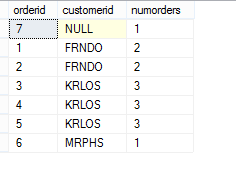
PARTITION BY子句定义了执行聚合计算的窗口,COUNT(*)汇总了SELECT输入虚表中customerid的值等于当前customerid的行数。
我们还可以在ORDER BY子句中使用OVER子句,如下:
SELECT orderid, customerid, COUNT(*) OVER(PARTITION BY customerid) AS numorders FROM dbo.Orders ORDER BY COUNT(*) OVER(PARTITION BY customerid) DESC
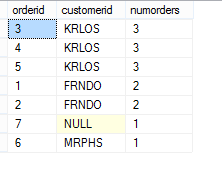
关于OVER子句,篇幅所限,我在这里不准备详细的讨论它的工作方式,只是简单的介绍了它的使用方式。如有机会,我会在后续博客中对它进行详细的解析。
集合运算符
SQL Server 2008支持四种集合运算符:UNION ALL,UNION,EXCEPT和INTERSECT。这些SQL运算符对应了数学领域中相应的集合概念。
通常,一个包含集合运算符的查询结构如下所示,每一行前面的数字是指该元素运行的逻辑顺序:
(1) query1 (2) <set_operator> (1) query2 (3) [ORDER BY <order_by_list>]
集合运算符会比较两个输入表中的所有行。UNION ALL返回的结果集包含了所有两个输入表中的行。UNION返回的结果集中包含了两个输入表中的不同的数据行(没有重复行)。EXCEPT返回在第一个输入中出现,但没有在第二个输入中出现的数据行。INTERSECT返回在两个输入中都出现过的数据行。
在涉及集合运算的单个查询中不允许使用ORDER BY 子句,因为查询期望返回的是(无序的)集合。但我们可以在查询的最后指定ORDER BY子句,对集合运算的结果进行排序。
从逻辑处理角度来看,每个输入查询都会根据自己的相应阶段进行处理,然后处理集合运算符。如果指定了ORDER BY子句,它作用于集合运算符产生的结果集。
比如,下面的查询:
SELECT region, city FROM Sales.Customers WHERE country = N'USA' INTERSECT SELECT region, city FROM HR.Employees WHERE country = N'USA' ORDER BY region, city;
首先,每个输入查询都会单独处理。第一个查询返回来自USA的客户位置,第二个查询返回来自USA的员工位置。INTERSECT返回同时出现在两个输入查询中的记录,即同时属于客户和员工的位置。最后,按照位置信息进行排序。
理解逻辑查询处理的各个阶段和SQL的一些特性,对于理解SQL编程的特殊性和树立正确的思维方式是非常重要的。我们的目的是真正的掌握这些必要的基础知识,这样我们就可以写出优雅的查询,制定出高效的解决方案,并且了解其中的原理。