来自https://blog.csdn.net/sunwukong_hadoop/article/details/80175292
1、Python的继承以及调用父类成员
python子类调用父类成员有2种方法,分别是普通方法和super方法。
假设Base是基类。
class Base(object): def __init__(self): print “Base init”
普通方法:
class Leaf(Base): def __init__(self): Base.__init__(self) print “Leaf init”
super方法:
class Leaf(Base): def __init__(self): super(Leaf, self).__init__() print “Leaf init”
在上面简单的场景下,两个效果是一样的:
>>> leaf = Leaf()
Base init
Leaf init
2、钻石继承遇到的难题
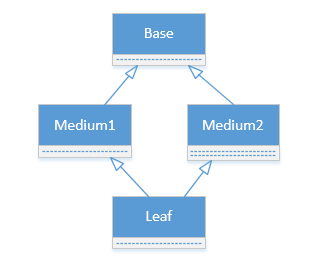
普通方法:
class Base(object): def __init__(self): print “Base init” class Medium1(Base): def __init__(self): Base.__init__(self) print “Medium1 init” class Medium2(Base): def __init__(self): Base.__init__(self) print “Medium2 init” class Leaf(Medium1, Medium2): def __init__(self): Medium1.__init__(self) Medium2.__init__(self) print “Leaf init”
当我们生成Leaf对象时,结果如下:
>>> leaf = Leaf()
Base init
Medium1 init
Base init
Medium2 init
Leaf init
可以看到Base被初始化了两次!这是由于Medium1和Medium2各自调用了Base的初始化函数导致的。


super方法:
class Base(object): def __init__(self): print “Base init” class Medium1(Base): def __init__(self): super(Medium1, self).__init__() print “Medium1 init” class Medium2(Base): def __init__(self): super(Medium2, self).__init__() print “Medium2 init” class Leaf(Medium1, Medium2): def __init__(self): super(Leaf, self).__init__() print “Leaf init”
我们生成Leaf对象:
>>> leaf = Leaf()
Base init
Medium2 init
Medium1 init
Leaf init
可以看到整个初始化过程符合我们的预期,Base只被初始化了1次。而且重要的是,相比原来的普通写法,super方法并没有写额外的代码,也没有引入额外的概念
4. super的内核:mro
要理解super的原理,就要先了解mro。mro是method resolution order的缩写,表示了类继承体系中的成员解析顺序。
在python中,每个类都有一个mro的类方法。我们来看一下钻石继承中,Leaf类的mro是什么样子的:
>>> Leaf.mro()
[<class '__main__.Leaf'>, <class '__main__.Medium1'>, <class '__main__.Medium2'>, <class '__main__.Base'>, <type 'object'>]
可以看到mro方法返回的是一个祖先类的列表。Leaf的每个祖先都在其中出现一次,这也是super在父类中查找成员的顺序。
通过mro,python巧妙地将多继承的图结构,转变为list的顺序结构。super在继承体系中向上的查找过程,变成了在mro中向右的线性查找过程,任何类都只会被处理一次。
通过这个方法,python解决了多继承中的2大难题:
1. 查找顺序问题。从Leaf的mro顺序可以看出,如果Leaf类通过super来访问父类成员,那么Medium1的成员会在Medium2之前被首先访问到。如果Medium1和Medium2都没有找到,最后再到Base中查找。
2. 钻石继承的多次初始化问题。在mro的list中,Base类只出现了一次。事实上任何类都只会在mro list中出现一次。这就确保了super向上调用的过程中,任何祖先类的方法都只会被执行一次。
至于mro的生成算法,可以参考这篇wiki:https://en.wikipedia.org/wiki/C3_linearization
5. super的具体用法
5.1. super(type, obj)
当我们在Leaf的__init__中写这样的super时:
-
class Leaf(Medium1, Medium2):
-
def __init__(self):
-
super(Leaf, self).__init__()
-
print “Leaf init”
super(Leaf, self).__init__()的意思是说:
- 获取self所属类的mro, 也就是[Leaf, Medium1, Medium2, Base]
- 从mro中Leaf右边的一个类开始,依次寻找__init__函数。这里是从Medium1开始寻找
- 一旦找到,就把找到的__init__函数绑定到self对象,并返回
从这个执行流程可以看到,如果我们不想调用Medium1的__init__,而想要调用Medium2的__init__,那么super应该写成:super(Medium1, self)__init__()
5.2. super(type, type2)
当我们在Leaf中写类方法的super时:
class Leaf(Medium1, Medium2): def __new__(cls): obj = super(Leaf, cls).__new__(cls) print “Leaf new” return obj
- 获取cls这个类的mro,这里也是[Leaf, Medium1, Medium2, Base]
- 从mro中Leaf右边的一个类开始,依次寻找__new__函数
- 一旦找到,就返回“非绑定”的__new__函数
由于返回的是非绑定的函数对象,因此调用时不能省略函数的第一个参数。这也是这里调用__new__时,需要传入参数cls的原因
同样的,如果我们想从某个mro的某个位置开始查找,只需要修改super的第一个参数就行