目录:
四、TensorFlow的编程模型:边、节点、图、设备、变量、变量初始化、内核
五、常用的API:图、操作、张量、变量作用域【variable_scope】、占位符placeholder
一、TensorFlow的系统架构:
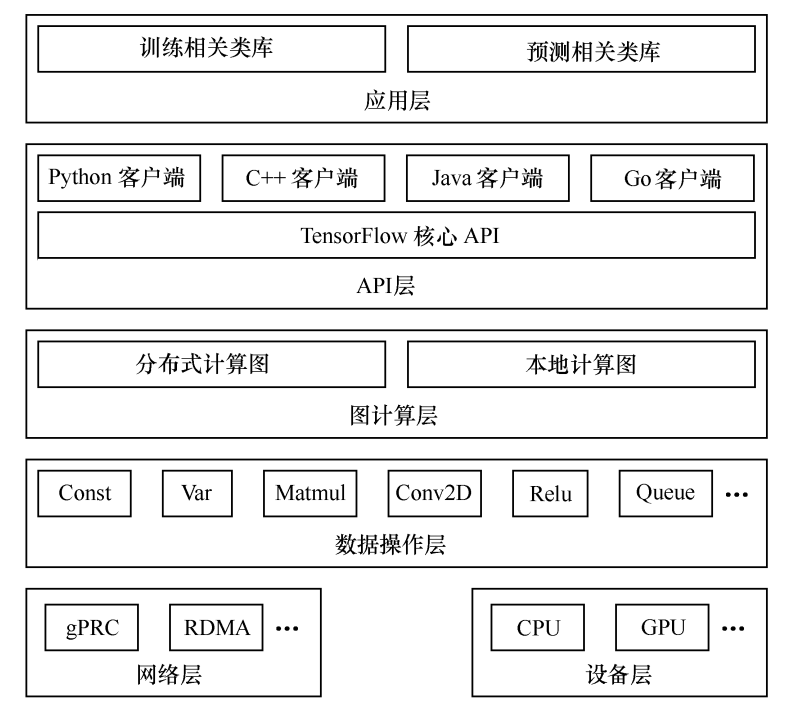
二、设计理念:
(1)将图的定义和运行完全分开。TensorFlow采用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量之间的计算关系,最后需要对数据流图进行编译,但这时的数据流图是一个空壳,里面没有实际数据,只有把需要的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
(2)TensorFlow涉及的运算都放在图中,图的运行只发生在会话(session)中。开启会话后,就可以用数据去填充节点,进行运算。关闭会话后,就不能进行计算了。
三、TensorFlow的运行流程
运行流程主要有2步:构造模型和训练。
构造模型阶段,需构建一个图(Graph)来描述我们的模型。所谓的图,可认为是流程图,即将数据的输入--> 中间处理--> 输出的过程表示出来,如下图:
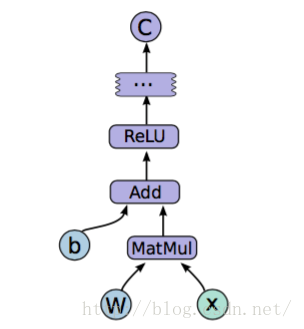
这时候是不会发生实际运算的,在模型构建完毕之后,进入训练步骤。此时才会有实际的数据输入,梯度计算等操作。
构建抽象的模型的几个重要概念:Tensor,Variable,placeholder
训练阶段的重要概念:session
四、编程模型:
(1)边:边有两种连接关系:数据依赖和控制依赖。其中,实现边表示数据依赖,代表数据,即张量。张量具有的一些数据属性:
tf.float32
tf.float64
tf.int64
tf.int32
……
虚线边为依赖控制,可用于控制操作的运行,这类边没有数据流过。但源节点必须在目的节点开始执行前完成执行。常用代码如下:
tf.Graph.control_dependencies(control_inputs)
(2)节点:图中的节点表示一个操作(OP),即数学运算。在建立图的时候确定下来。

(3)图:构建图的第一步是创建各个节点。具体如下:
import tensorflow as tf #创建一个常量运算操作,产生一个1×2矩阵 matrix1 = tf.constant ( [ [ 3., 3. ] ] ) #创建另一个常量运算操作,产生一个2×1矩阵 matrix2 = tf.constant ( [ [2.] , [2. ] ] ) #创建一个矩阵乘法运算,把两个matrix作为输入 #返回值product代表矩阵乘法的结果 product = tf.matmul ( matrix1,matrix2)
为什么要写 tf.Graph().as_default()?
-
多线程:
tf.Graph() 表示实例化了一个类,一个用于 tensorflow 计算和表示用的数据流图,通俗来讲就是:在代码中添加的操作(画中的结点)和数据(画中的线条)都是画在纸上的“画”,而图就是呈现这些画的纸,你可以利用很多线程生成很多张图,但是默认图就只有一张。
tf.Graph().as_default() 表示将这个类实例,也就是新生成的图作为整个 tensorflow 运行环境的默认图,如果只有一个主线程不写也没有关系,tensorflow 里面已经存好了一张默认图,可以使用tf.get_default_graph() 来调用(显示这张默认纸),当你有多个线程就可以创造多个tf.Graph(),就是你可以有一个画图本,有很多张图纸,这时候就会有一个默认图的概念了。
-
上下文管理器
另外一种典型的用法就是要使用到Graph.as_default() 的上下文管理器( context manager),它能够在这个上下文里面覆盖默认的图。
(4)会话:启动图的第一步是创建一个session对象。会话提供在图中执行操作的一些方法,一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。
with tf.Session() as sess: #在调用session对象的run()方法来执行图时,传入一些Tensor,这个过程叫填充(feed),返回的结果类型根据输入的类型而定,这个过程叫取回(fetch)。 result = sess.run ( [product] ) print result
(5)设备(device):一块可以用来运算并且拥有自己的地址空间的硬件,如GPU和CPU。
with tf.Session() as sess: #指定在第二个gpu上运行 with tf.device("/gpu:1"): matrix1 = tf.constant ( [ [3. ,3. ]]) matrix2 = tf.constant ( [ [2. ], [ 2. ]]) product = tf.matmul ( matrix1,matrix2)
(6)变量:比如用来建立激活函数中的W、b等矩阵变量。使用tf.Variable()构造函数。
#创建一个变量,初始化为标量0 state = tf.Variable ( 0 , name="counter" )
#以下两个是等价的,在创建变量时,两者区别不大,get_variable可获取变量
v = tf.get_variable("v" , shape = [1] ,initializer = tf.constant_initializer(1.0))
v = tf.Variable(tf.constant(1.0,shape = [1]) ,name = "v")
tf.get_variable函数和tf.Variable函数最大的区别在于指定变量名称的参数。
tf.Variable的变量名称是一个可选的参数,name = "v“。
tf.get_variable的变量名称是一个必填的参数。tf.get_variable根据这个名称创建或获取这个变量。
(7)内核:能运行在CPU、GPU等设备上的一种对操作的实现。
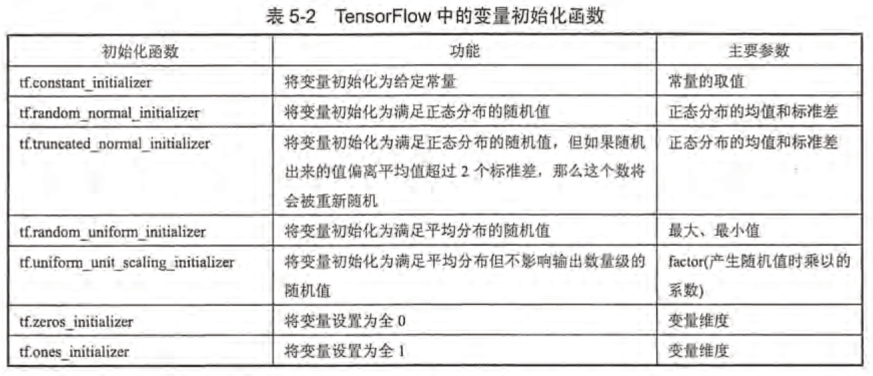
(8)变量初始化:
五、常用的API
(1)图:

(2)操作:


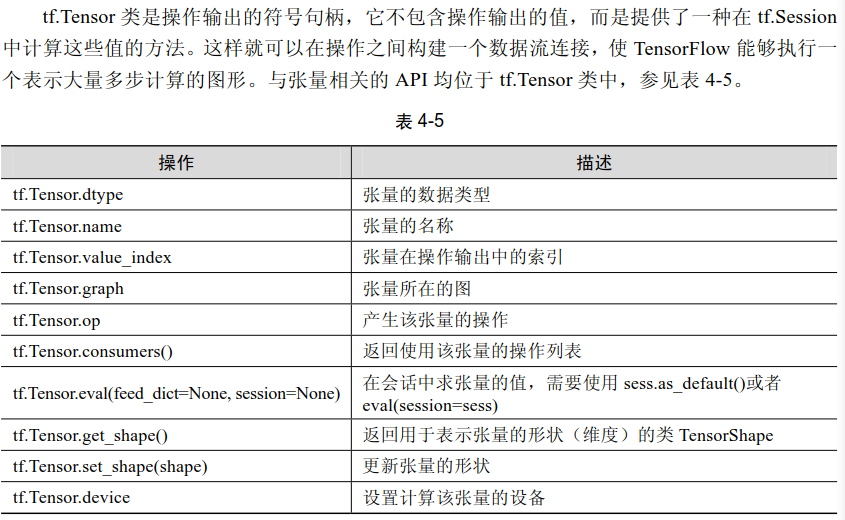
(3)张量:
(4)变量作用域:
TensorFlow有两个作用域:一个是name_scope,另一个是variable_scope。
variable_scope主要是给variable_name加前缀(变量),也可给op_name加前缀(操作),name_scope是给op_name加前缀。
variable_scope有点像将该变量变成全局变量,作用域可以共享变量的意思。
v = tf.variable (name, shape ,dtype , initializer ) #通过所给的名字创建或是返回一个变量 tf.variable_scope(<scope_name>) #为变量指定命名空间

(5)占位符placeholder
tf.placeholder(tf.float32,shape),shape常表示为[None,整数],这里的None表示未知的样本数。
有placeholder后面就有一个feed_dict绑定,
import tensorflow as tf #placeholder在开始时相当于先为变量占位,在后面在用不同的变量来换掉它 #设置两个占位 input1 = tf.placeholder(tf.float32) #若需要规定2行2列这种结构可在后面添加成 tf.placeholder(tf.float32 ,[2,2] ) input2 = tf.placeholder(tf.float32) output = tf.mul ( input1,input2) #只要有placeholder后面就有一个feed_dict绑定,在sess.run那用它来赋值 with tf.Session() as sess: print( sess.run (output, feed_dict= { input1:[7.] , input2:[2.] })
(6)用GPU进行TensorFlow计算加速
GPU只在部分数据类型上支持tf.Variable操作。如果在TensorFlow代码库中搜索调用这段代码的宏TF_CALL_GPU_NUMBER_TYPES,可以发现在GPU上,tf.Variable操作只支持实数型(float16、float32和double)的参数。而在报错的样例代码中给定的参数是整数型的,所以不支持在GPU上运行。为避免这个问题,TensorFlow在生成会话时可以指定allow_soft_placement参数。当allow_soft_placement参数设置为True时,如果运算无法由GPU执行,那么TensorFlow会自动将它放到CPU上执行。以下代码给出了一个使用allow_soft_placement参数的样例。
故tf.device("/gpu:1")有时会报错。
os.environ["CUDA_VISIBLE_DEVICES"] = "1" config = tf.ConfigProto() # config.gpu_options.per_process_gpu_memory_fraction = 0.5 config.gpu_options.allow_growth=True # allocate when needed sess = tf.Session(config = config)
(7)embedding_lookup
https://www.cnblogs.com/gaofighting/p/9625868.html
https://blog.csdn.net/laolu1573/article/details/77170407

import tensorflow as tf p=tf.Variable(tf.random_normal([10,1]))#生成10*1的张量 b = tf.nn.embedding_lookup(p, [1, 3])#查找张量中的序号为1和3的 c = tf.nn.embedding_lookup(p, [[1,2, 3],[2,4,5]])#查找batch_size = 2,ndim = 3的张量中的序号 d = tf.expand_dims(c, -1) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print("b:",b) print(sess.run(b)) print("c:",c) print(sess.run(c)) print("d:",d) print(sess.run(d)) print("p:",p) print(sess.run(p)) print(type(p))
结果
b: Tensor("embedding_lookup_17:0", shape=(2, 1), dtype=float32) [[ 1.3196588] [-0.8500369]] c: Tensor("embedding_lookup_18:0", shape=(2, 3, 1), dtype=float32) [[[ 1.3196588 ] [-0.48340532] [-0.8500369 ]] [[-0.48340532] [-0.74867696] [ 2.043409 ]]] d: Tensor("ExpandDims_4:0", shape=(2, 3, 1, 1), dtype=float32) [[[[ 1.3196588 ]] [[-0.48340532]] [[-0.8500369 ]]] [[[-0.48340532]] [[-0.74867696]] [[ 2.043409 ]]]] p: <tf.Variable 'Variable_9:0' shape=(10, 1) dtype=float32_ref> [[-0.07763693] [ 1.3196588 ] [-0.48340532] [-0.8500369 ] [-0.74867696] [ 2.043409 ] [ 1.0277175 ] [ 0.8650728 ] [-1.1537417 ] [ 0.4588327 ]] <class 'tensorflow.python.ops.variables.Variable'>
(8)tf.split
import tensorflow as tf p=tf.Variable(tf.random_normal([10,1]))#生成10*1的张量 c = tf.nn.embedding_lookup(p, [[1,2, 3],[2,4,5]])#查找batch_size = 2,ndim = 3的张量中的序号 input_att = tf.split(c, 3, axis=1) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print("c:",c) print(sess.run(c)) print(sess.run(input_att))
结果
c: Tensor("embedding_lookup_24:0", shape=(2, 3, 1), dtype=float32) [[[-0.02312754] [ 1.137335 ] [ 0.28091738]] [[ 1.137335 ] [-0.39026853] [ 0.16639084]]] [array([[[-0.02312754]], [[ 1.137335 ]]], dtype=float32), array([[[ 1.137335 ]], [[-0.39026853]]], dtype=float32), array([[[0.28091738]], [[0.16639084]]], dtype=float32)]
(9) tf.linspace
tensorflow在设计时,尽量模仿numpy,因此很多函数都很类似。不过有一些操作tf中还是无法支持的,比如map:
import tensorflow as tf import numpy as np """ 0.0 3.3333333333333335 6.666666666666667 10.0 """ for a in np.linspace(0., 10., 4): print(a) """ TypeError: Tensor objects are not iterable when eager execution is not enabled. To iterate over this tensor use tf.map_fn. """ for a in tf.linspace(0., 10., 4): print(a)
六、模块
https://blog.csdn.net/u014365862/article/details/77833481
tf.nn,tf.layers, tf.contrib模块有很多功能是重复的,尤其是卷积操作,在使用的时候,我们可以根据需要现在不同的模块。但有些时候可以一起混用。
下面是对三个模块的简述:
(1)tf.nn :提供神经网络相关操作的支持,包括卷积操作(conv)、池化操作(pooling)、归一化、loss、分类操作、embedding、RNN、Evaluation。
(2)tf.layers:主要提供的高层的神经网络,主要和卷积相关的,个人感觉是对tf.nn的进一步封装,tf.nn会更底层一些。
(3)tf.contrib:tf.contrib.layers提供够将计算图中的 网络层、正则化、摘要操作、是构建计算图的高级操作,但是tf.contrib包含不稳定和实验代码,有可能以后API会改变。
以上三个模块的封装程度是逐个递进的。