一、摘要
这篇论文提出一个视频推荐领域的大规模的多目标排序系统,该系统主要面临几个挑战:1)多个竞争关系的目标;2)用户反馈的选择偏见(selective bias)。 本文探究了大量软-参数共享技术,例如MMoE,来有效的优化多目标排序。除此之外,本文还采用wide&deep框架来缓和选择偏见问题。并且在youtube线上环境验证了方案的效果。
二、背景
本文描述了一个用户视频推荐的大规模排序服务。具体场景是:给定一个用户播放的视频,生成下一个他可能会播放和喜欢的视频。 典型的推荐系统包含两个阶段:召回(recall),排序(rank)。本文的重点聚焦在排序阶段:对召回阶段输出的数百个内容,应用复杂的模型进行排序,选出其中最有可能被用户喜欢的。
设计和部署一个大型的视频推荐系统充满了许多挑战,比如以下几条:
❶ 视频推荐中的多任务目标。比如不仅需要预测用户是否会观看外,还希望去预测用户对于视频的评分,是否会关注该视频的上传者,否会分享到社交平台等。
❷ 偏置信息。比如用户是否会点击和观看某个视频,并不一定是因为他喜欢,可能仅仅是因为它排在推荐页的最前面,这会导致训练数据产生位置偏置的问题。
所以本文的贡献:
- 提出一个基于deep&wide框架的多任务学习框架
- deep部分是一个MMoE多任务学习框架
- wide部分引入一个浅层网络,来降低selection bias(这篇论文用的是position bias)
目标分为两类:
- 参与性 点击、播放等隐式行为
- 满足性 点赞、打分等显示行为
这些目标可能正相关,也可能负相关,正好适合应用MMoE框架来解决。为了对selection bias进行建模,引入了一个浅层的模型。该模型输入是一个能刻画selection bias的因子,例如排序的位置,输出一个标量作为主模型输出的偏移量。
简而言之,该模型把用户对视频的喜好拆分成两部分:无偏效用(MMoE学习),bias(浅层网络学习)
三、相关工作
推荐问题可以理解为:给定一个查询、上下文、候选集,返回一个高可用性的小列表。在这一节,我们会分三部分来讨论:1)工业推荐系统的样例分析;2)多目标排序系统;3)理解训练数据的偏倚问题。
1、工业级推荐系统
想要设计、开发一个强大机器学习模型加持的成功的排序系统,我们需要大量的训练数据,在大多数现有的推荐系统中,训练数据都依赖用户的行为日志。
推荐系统想获得用户的显式反馈,例如电影评分等,但是由于用户成本很高,所以显示反馈往往很稀疏。因此,目前推荐系统的训练大多数依赖用户的隐式反馈,例如点击、播放等等。
推荐系统一般分为两个阶段:
- 召回
从海量视频中筛选出部分用户感兴趣的视频,为了提高多样性召回一般使用多路。通常包括:利用共现关系(关联规则),协同过滤,随机游走,基于内容,混合方法。
- 排序
一般采用LearningToRank方法,包括point-wise, pair-wise, list-wise。线上排序服务重点需要考虑效率问题,所以本文选用基于深度神经网络的point-wise方法,因为可扩展性强。
这些推荐系统面临的主要挑战之一就是可扩展性。所以,通常需要从机器学习模型效率和推荐系统架构两个方面着手。为了在模型的效率和效果中取得一个平衡,现在比较通行的做法是使用基于深度学习的pointwise排序模型。
本文首先提出了推荐系统的的问题:用户隐式反馈和真实需求之间的鸿沟;然后,提出一个基于深度学习的多任务学习模型,分别多两种类型用户反馈进行建模。
2、推荐系统中的多目标学习
在推荐系统中,用户的行为多种多样,例如:点击、点赞、下单等。 单个用户行为并不能准确反映用户对Item的好恶,例如一个用户播放某个视频,但是最后给了一个低分。并且这些行为之间不是相互独立的,可能会结合在一起决定用户对视频的偏好。所以,我们要结合这些行为分数在一起来评价用户的对某个视频的偏好。
目前不少推荐系统都有考虑到多目标。例如大多数推荐系统在召回阶段都会考虑到多目标,因此应用多种算法来做召回。 还有一些针对特定特征做了多目标排序,例如针对文本特征做了排序,针对图像特征做了一个排序。这些往系统的可扩展性比较差,一来没有利用不同特征之间的关系,二来一旦特征空间比较复杂,整个排序的参数规模会很大。
3、位置偏置
user logs:作为训练数据,用来捕获用户行为并推荐。
用户隐式反馈受位置偏倚影响很大,这个在搜索和推荐领域早就有人证明了这点。因此,也有了一些工作希望移除位置偏倚的影响。
比较常用的做法是把位置作为一个参数带入模型训练和预测过程。
例如把位置作为条件概率的前键值,对p(click∣position,item)建模,在预测阶段,计算p(click∣position=1,item)来移除位置的影响。
也有一些工作,学习一个全局的bias因子来对结果进行正规化,缺点是这个bias做不到个性化。
而且,在真实的推荐系统中,用户的兴趣偏好和视频的流行度每天都在变化,因此利用全局的bias很难取得好效果。
四、问题描述
构建一个视频推荐框架,除在上一节中介绍的一些挑战外,还有其他一些因素需要考虑:
1)Multimodal feature space:视频推荐模型需要考虑特征众多,比如视频本身内容、预览图、声音、标题和文字描述、上下文特征等等。
与其他机器学习应用相比,从多模态特征空间学习表示进行推荐具有独特的挑战性。它跨越了两个难题:在内容过滤中缩小与底层内容特征之间的语义鸿沟; 从稀疏的项目分布中学习协作过滤。
2)Scalability:可扩展性。因为在为数十亿用户和视频构建一个推荐系统,这种模式必须是有效的服务,并且高效。模型的线上性能需要得到保证。通常通过两阶段(召回和精排两阶段)来保证性能问题。
接下来介绍一下召回和精排两阶段的内容。在召回阶段,使用多路召回的方式生成一个小规模的候选集。比如,通过主题匹配度的召回、根据与当前观看视频同时观看的频率进行召回、基于模型的召回方式等等。而在精排阶段,则采用深度神经网络来对召回阶段得到的小规模候选集进行排序。
综上所述,推荐领域的排序面临以下几个问题:
- 隐式反馈不能代表用户真实兴趣
- 需要考虑多目标
- 特征很复杂,覆盖很多垂直领域的特征
- 位置偏倚
- 大规模应用场景要求模型算法的可扩展性
五、模型介绍
在这一节,本文将会会详细描述提出的排序系统的细节。首先,我们会提供问题的总览,包括:形式化、目标、特征。
然后,我们讨论如何设置多目标,以及如何引入经典的多目标排序模型:MMoE来学习多个排序目标。
最后,我们会陈述如何结合MMoE和浅层网络来学习和降低selective bias,尤其是位置偏倚。
1 整体框架
精排系统从两种类型的用户反馈中学习:(1)参与行为,如点击和观看(2)满意度行为,如喜欢和拒绝
问题:
给定用户的query, 上下文,候选集,排序系统会预测以上这两类行为。(出于对线上部署便利性和效率的考虑,本文选用pointwise类方法。)
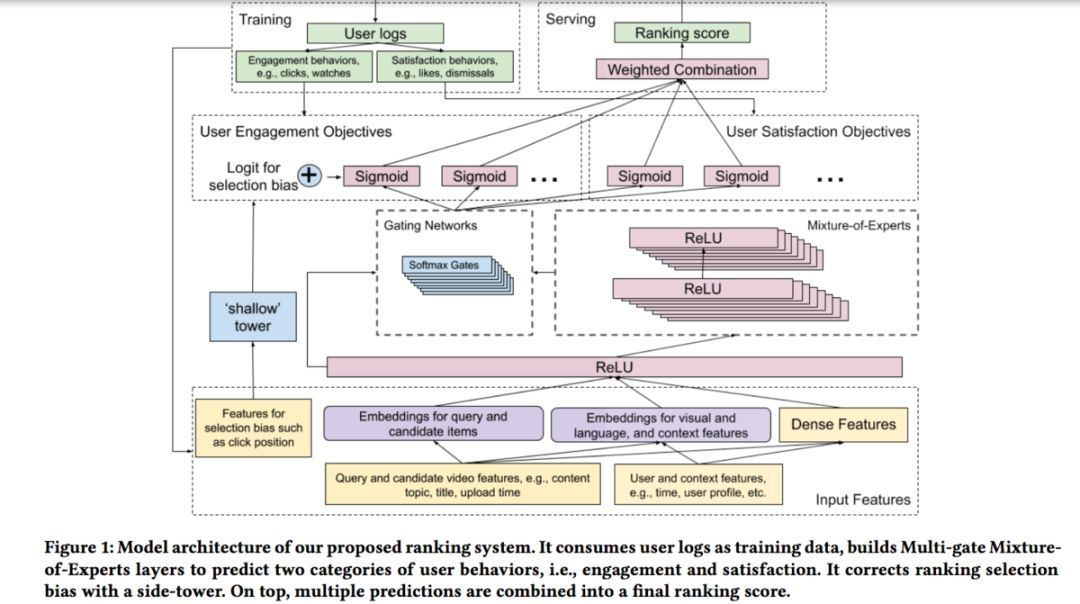
模型中有两个比较重要的结构:基于Wide&Deep的架构(加入消除位置偏置的 shallow tower)和 Multi-gate Mixture-of-Experts ( MMoE ) 。
为了减少selection bias(比如position bias),用图1左边的浅层塔,接收selection bias作为输入,比如排序位置,输出标量作为主模型最终预测的偏差项。
模型将目标分解为两部分,一个是无偏的用户偏好,另一个是倾向分。模型结构可以看做是Wide&Deep的扩展,浅层塔代替Wide部分。因为直接学习shallow tower,所以不用随机实验区获得倾向分。
2.3 排序目标
将精排问题建模为分类问题和多目标回归问题的组合。给定一个查询、候选对象和上下文,精排模型预测用户执行如点击、观看、喜欢和取消等操作的概率。
这里使用用户行为来作为训练的Label。用户可能会有不同方面的行为,每种不同的行为都可以视为一个排序目标。这些排序目标主要分为两大类:
- engagement objectives:这类目标主要考虑用户点击和观看行为。其中参与性拆分为两个目标:通过二分类模型来预测用户的点击行为,而通过回归模型来预测用户观看视频的时长。
- satisfaction objectives:这类目标主要考虑用户在观看视频之后对于视频的反馈。满足性也可拆分为两个目标:使用二分类模型来预测用户是否会点击喜欢该视频,而通过回归模型来预测用户对于视频的评分。相应的损失函数分别为:交叉熵损失和平方损失。
针对上述不同的目标,使用一个多任务学习模型来进行训练。
而在应用阶段,把每一个候选视频输入到多任务学习模型中,来得到各个子任务的输出结果,通过加权的方式来输出一个综合的推荐评分,从而进行排序。
而不同网络结果的权重,通过人工调节来实现。
2.4 多任务模型
多目标排序模型通常的结构都是底层共享一个shared-bottom结构。然而,如果这些底层共享比较硬,对于相互关系不密切,甚至矛盾的多目标建模,最终的效果会收到损害。因此,youtube在2018年提出了MMoE结构,bottom层为多个expert模块组合而成,每个任务的组合系统不同,因此参数共享比较soft。

MMOE模型:
该模型结构并不完全等同于MMoE,因为在推荐领域特征规模很大,为了降低复杂度,在MoE层和输入之间插入一个shared bottom层来对特征进行降维。这种方法其实很常见,例如可以对底层的embedding matrix进行卷积操作,降低矩阵的大小。
shared bottom层上面,就是MoE层,以及边缘的gate。每个MoE层只是一层MLP+ReLU。
给定输入x, MoE层的输出为f(x)i,i∈[1,n]。每个任务k的tower的输入为MoE的混合(Mixture), ![]() 。
。
其中k与任务相关,每个任务有一个独立的g(x).![]()
Expert的数量可以很多,但是每个task最终采纳的可能只有权重最大的topK个。
随后每个任务对应的共享层输出,经过多层全连接神经网络得到每个任务的输出:

shallow tower:
隐式反馈的位置偏倚,以及其他类型的选择性偏倚在推荐和广告系统中广泛存在,因为隐式反馈受是来自于本系统的上一次推荐,这就是feedback loop。
例如在推荐系统中,我们想基于用户目前正在观看的视频,预测他下一个观看的视频,用户往往倾向于点击观看列表最上面的视频,这和他的兴趣偏好之类因素无关。我们的目标就是在排序模型中移除这种位置偏倚,来提高模型的质量,中断feedback loop。
最终的模型结构大概如下图所示:
两个部分:一个是main tower 来训练用户效用的模型,另一个是shallow tower来训练位置偏差。

2.5 建模和消除位置偏置
CTR预估问题往往存在位置偏置信息,在Youtube中,不同位置的点击率差别很大:

不同位置的点击率差异主要来自于推荐结果相关性以及位置偏置。
消除推荐系统中的位置偏置,一种常见的做法是在训练阶段将位置作为一个特征加入到模型中,而在预测阶段置为0或者一个统一的常数,如下图所示:

还有一种做法是在训练阶段将点击率拆解为两个部分,即用户看到物品的概率 * 用户看到物品后点击的概率,而在测试阶段只预估用户看到物品后点击的概率,示意图如下:

而本文的做法与上面两种方式都不相同,示意图如下:
通过一个shallow tower(可理解为比较轻量的模型)来预测位置偏置信息,输入的特征主要是一些和位置偏置相关的特征。在多任务模型的子任务最后的sigmoid前,将shallow tower的输出结果加入进去。而在预测阶段,则不考虑shallow tower的结果。
值得注意的是,位置偏置信息主要体现在CTR预估中,而用户观看视频是否会点击喜欢或者用户对视频的评分,这些是不需要加入位置偏置信息的。
六、实验及结果
这里主要对比了两个模型,一个是一般的MTL结构,一个是MMoE结构。对于评价指标,线下采用AUC,线上采用A/B test的方式,来观测实验组和对照组的停留时间、好评率等等指标,实验结果如下:

实验表明:
- 某些expert的作用比其他expert大;
- 一些task分配给Expert的权重较为均匀,另一些则更极端一些。极端情况的出现会导致gating网络不稳定,一般引入dropout来降低影响;
七、 讨论
一些在其他领域取得不错效果的模型,如CNN, multi-head attention在CTR预估领域并不能取得很好的效果。原因可能是包括:
1.1 特征多模态,推荐用到的特征模态比较复杂
1.2 扩展性和多目标冲突
1.3 噪音和数据稀疏性
出于效率考虑,网络结构不易太复杂太深。
训练数据还存在其他bias
复杂模型线下,和线上效果评估可能差别较大;
未来方向:
5.1 开发新模型,提高扩展性、表达能力
5.2 对未知bias建模
5.3 模型压缩,降低latency