一、归纳偏置
1、概念
inductive bias是关于目标函数的必要假设。
在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置(Inductive Bias)。
归纳(Induction)是自然科学中常用的两大方法之一(归纳与演绎, induction and deduction),指的是从一些例子中寻找共性、泛化,形成一个比较通用的规则的过程;
偏置(Bias)是指我们对模型的偏好。
通俗理解:
归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,类似贝叶斯学习中的“先验”。
2、例子
- 老生常谈的“奥卡姆剃刀”原理,即希望学习到的模型复杂度更低,就是一种归纳偏置。
- 一些更强的假设:KNN中假设特征空间中相邻的样本倾向于属于同一类;
- SVM中假设好的分类器应该最大化类别边界距离;
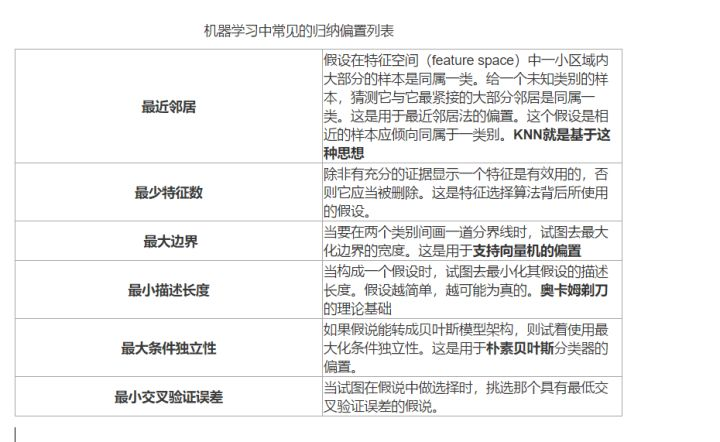
- CNN的inductive bias应该是locality和spatial invariance,即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)
- RNN的inductive bias是sequentiality和time invariance,即序列顺序上的timesteps有联系,和时间变换的不变性(rnn权重共享)
- 注意力机制,也是基于从人的直觉、生活经验归纳得到的规则。
3、作用
归纳偏置的作用是使得学习器具有了泛化的功能。
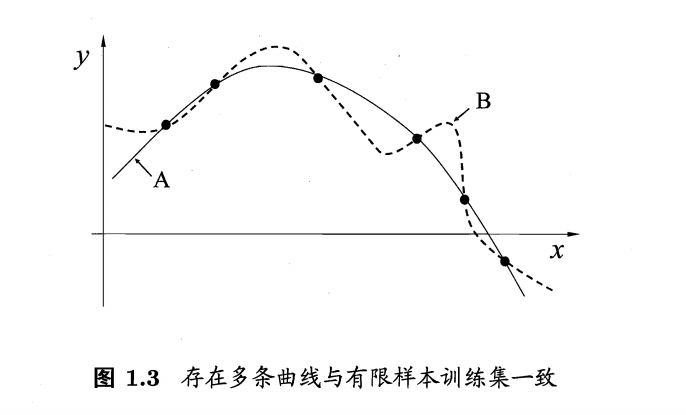
对于图中的6个离散的点可以找到很多条不同的曲线去拟合它们,但是我们自己训练的模型必然存在一定的“偏好”才能学习出模型自己认为正确的拟合规则。
哪条是较为准确地拟合出通用规则的曲线?明显地,实线是加了一定正则的偏置才能使得曲线更为简单,更为通用。
二、选择性偏差
选择性偏差:在研究过程中因样本选择的非随机性而导致得到的结论存在偏差,不能代表整体,包括自选择偏差(self-selection bias)和样本选择偏差(sample-selection bias)。
例子:
- 例如调用全国大学生学习情况,如果样本空间只是清华、北大,那么肯定会对总体的调查结果产生很大的差别,这就是我们常说的选择性误差
-
找50个身体很好,但是抽烟的人。再找50个身体很差,但是不抽烟的人。对比两组人,得出结论:吸烟有益健康。样本存在选择性偏差。
参考文献: