一、pig:
pig提供了一个基于Hadoop的并行地执行数据流处理的引擎。它包含了一种脚本语言,称为Pig Latin。(类似SQL)
二、pig本地安装(仅用于本地小代码测试):
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/pig/pig-0.17.0/
创建Pig安装目录并解压到该目录下:
mkdir /opt/pig_home
tar -zxvf pig-0.17.0.tar.gz -C /opt/pig_home
设置环境变量:
vim /etc/profile
加入
export PIG_HOME=/opt/pig_home/pig-0.17.0
export PATH=$PATH:$PIG_HOME/bin
source /etc/profile
检测是否成功:
pig –x local :即可进入pig交互式界面。
三、Pig Latin语法:
1、数据类型:
基本类型: int 、long、float、double、chararray、bytearray
复杂类型:Map、Tuple、Bag
Tuple:行/记录,有序的字段集合,如('bob',55)为一个包含两个字段的tuple常量。
Bag:表,无序的tuple集合,如{('bob',55),('sally',52),('john',25)}为一个包含三个tuple的bag. [ pig中没有list或者set类型,所以常将一个int字段放入tuple中,再放入bag中,如{(1),(2),(3)} ]
Field:属性/字段,Pig不要求同一个bag里的每个tuple有相同数量或者相同类型的field
pig中有null值概念,其表示该值是未知的,可能是因为确实或者处理数据时发生了错误。
关系(relation)、包(bag)、元组(tuple)、字段(field)、数据(data)的关系
-
- 一个关系(relation)是一个包(bag),更具体地说,是一个外部的包(outer bag)。
- 一个包(bag)是一个元组(tuple)的集合。在pig中表示数据时,用大括号{}括起来的东西表示一个包——无论是在教程中的实例演示,还是在pig交互模式下的输出,都遵循这样的约定,请牢记这一点,因为不理解的话就会对数据结构的掌握产生偏差。
- 一个元组(tuple)是若干字段(field)的一个有序集(ordered set)。在pig中表示数据时,用小括号()括起来的东西表示一个元组。
- 一个字段是一块数据(data)。
2、注释:
单行:--
多行:/* */
3、输入和输出:
加载:load '文件'
using PigStorage(',');
as (exchange:int,symbol:long,date:int,dividends:chararry);
//使用内置函数PigStorage函数,指定分隔符为',';还有一个加载函数是TextLoader。
//采用as指定加载数据的模型。
存储:store 变量 into '输出文件';
输出:dump 变量;//打印 ,只有dump 或者descrip 描述的时候才会执行代码,若之前有group 等等语句,只是把他们加入到逻辑计划中,pig开始执行的是dump 语句,此时逻辑计划被编译成物理计划
查看数据关系:describe 变量;//用于查看变量字段关系。[直接快速将变量schema打印出来,比dump速度快]
4、关系操作:
foreach、Filter、Group、Order、Distinct、Join、Limit
5、foreach:
逐行扫描进行某种处理,接受一组表达式,然后将它们应用到每条记录中。
- 比如:加载完所有记录,只保留user和id两个字段。
A = load 'input' as (user:chararray , id:long , address:chararray, password: long, date: int, name: chararray); B = foreach A generate user,id;
- 可以用*代表全部字段或者..来指定字段区间。
A = load 'input' as (user:chararray , id:long , address:chararray, password: long, date: int, name: chararray); B = foreach A generate ..password; --[产生user , id , address, password字段] C = foreach A generate address..date; --[产生address, password,date字段]
- 两列操作:
A = load 'input' as (a:int , b:int , c:int); B = foreach A generate b - c; C = foreach A generate $1 - $2; -- [B 和C 是一样的,$0表示第一个字段,以此类推]
- foreach 语句中的UDF(自定义函数),如:A = load 'input' as (a,b); B = foreach data generate UPPER(a) as a, b;
- 类型转换:直接在字段前面加(类型),如:time字段原本的类型为chararray, (int)time即可。
- +/-/*//加减乘除都可以用。
- ?:像C++中的一样用。2==2?1:4返回1.
- tuple的映射是用.(点),如
A = load 'input' as (t:tuple(x:int,y:int)); B = foreach A generate b - c;
- bag不能直接映射tuple,可映射tuple内的字段,生成新的bag。
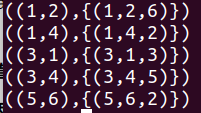
如 A 为{group:int,data:{(a:int,b:int,c:int)}},--数据为 ![]()
B = foreach A generate data.a; --B:{{(a:int)}} 数据为 ({(1),(1)}) ({(3),(3)}) ({(5)}) C = foreach A generate data.(a,b); --C:{{(a:int,b:int)}}, 数据为 ({(1,4),(1,2)}) ({(3,1),(3,4)}) ({(5,6)})
以下是错误的:
data = load 'input.txt' as (a:int, b: int, c: int); --data: {a:int,b:int,c:int} ,数据为 (1,2,6) (3,4,5) (5,6,2) (1,4,2) (3,1,3) group_data = group data by a; -- 产生包含对于a给定的值对应的所有记录的bag ,{group:int,data:{(a:int,b:int,c:int)}},数据为 (1,{(1,4,2),(1,2,6)}) (3,{(3,1,3),(3,4,5)}) (5,{(5,6,2)})
D = foreach group_data generate SUM(data.b+ data.c);
应该修改成:
data = load 'input.txt' as (a:int, b: int, c: int); A1 = foreach data generate a, b + c as bc; -- A1:{a:int,bc:int},数据为 (1,8) (3,9) (5,8) (1,6) (3,4) B1 = group A1 by a; --B1:{group:int,A1:{(a:int,bc:int)}} ,数据为 (1,{(1,6),(1,8)}) (3,{(3,4),(3,9)}) (5,{(5,8)}) C = foreach B1 generate SUM(A1.bc); -- C:{long},数据为 (14) (13) (8)
Order by:
Distinct:
Join:
Limit:
6、filter:
不可以在generate中使用。
- 过滤出字段name为非空值的行。如:divs = filter data by name is not null;
- 匹配正则的行,获取字段name中不是BOB.*这种形式的。如:divs = filter data by not name matches 'BOB.*'; [ and / or / not布尔操作符 , and若执行第一个逻辑为false,后面就不执行了 ]
7、Group by :
可以将具有相同键值的数据聚合在一起。https://www.cnblogs.com/lishouguang/p/4559593.html
group by语句的输出结果包含两个字段,一个是键,另一个是包含了聚集的记录的bag。存放键的字段别名为group。而bag的别名和被分组的那条语句的别名。
注意:这里group的key字段类型不能是bag。
- 如:将两个key组合group。
data = load 'input.txt' as (a:int, b: int, c: int); -- data:{a:int, b:int, c:int} ,数据为 (1,2,6) (3,4,5) (5,6,2) (1,4,2) (3,1,3) two_key_group = group data by (a,b);
若要获取group.a和group.b可以通过flatten(group)来得到,即
flatten_data = FOREACH two_key_group generate flatten(group), data.a,data.b;

- 如:group all, 对用户的数据流中所有字段进行分组,原本bag数据值没变化,只是顺序打乱了。
all_group = group data all;
- 如:log = FOREACH (GROUP log ALL) GENERATE FLATTEN(log); [在将order_log存入文件之前执行这句话的作用是希望将order_log只存到一个文件中,而不是多个文件中,因为pig存文件时会将一个变量拆分成多个文件来存]
8、order by:
默认升序,降序采用desc。
-- data: (1,2,6) (3,4,5) (5,6,2) (1,4,2) (3,1,3) order_data = order data by a desc, b; (5,6,2) (3,1,3) (3,4,5) (1,2,6) (1,4,2)
9、distinct, 去重。
data = load 'input' uniq = distinct data;
10、join
将两个表连接起来,其中采用::来获取某个表的某个字段,如表A的a字段和表B的a字段分别为,A::a和B::a。
https://www.cnblogs.com/lishouguang/p/4559602.html
jnd = join a by f1, b by f2;
a = load 'input1'; b = load 'input2'; jnd = join a by $0, b by $1;
多字段连接:
a = load 'input1' as (username, age, city); b = load 'input2' as (orderid, user, city); jnd = join a by (username, city), b by (user, city);
:: join后的字段引用
a = load 'input1' as (username, age, address); b = load 'input2' as (orderid, user, money; jnd = join a by username, b by user; result = foreach jnd generate a::username, a::age, address, b::orderid;
多数据集连接
a = load 'input1' as (username, age); b = load 'input2' as (orderid, user); c = load 'input3' as (user, acount); jnd = join a by username, b by user, c by user;
外连接 仅限两个数据集
a = load 'input1' as (username, age); b = load 'input2' as (orderid, user); jnd = join a by username left outer, b by user; jnd = join a by username right, b by user; jnd = join a by username full, b by user;
自连接 需要加载自身数据集两次,使用不同的别名
a = load 'data' as (node, parentid, name); b = load 'data' as (node, parentid, name); jnd = join a by node, b by parentid;
https://www.aboutyun.com/thread-14881-1-1.html
1) Replicated Join
当进行Join的一个表比较大,而其他的表都很小(能够放入内存)时,Replicated Join会非常高效。
Replicated Join会把所有的小表放置在内存当中,然后在Map中读取大表中的数据记录,和内存中存储的小表的数据进行Join,得到Join结果,无需Reduce。
可以在Join时使用 Using 'replicated'语句来触发Replicated Join,大表放置在最左端,其余小表(可以有多个)放置在右端。
2) Skewed Join
当进行Join的两个表中,一个表数据记录针对key的分布极其不均衡的时候,简单的使用Hash来分配Reduce端的key时,可能导致某些Reducer上的数据量特别大,降低整个集群的性能。
Skewed Join可以首先对左边的表的key统计其分布,然后决定Reduce端的key的分布,尽量使得Reduce端的数据分布比较均衡
可以在Join时使用Using 'skewed'语句来触发Skewed Join,需要进行统计的表(亦即key可能分布不均衡的表)放置在左端。
3) Merge Join
当进行Join的两个表都已经是有序的时,可以使用Merge Join。
Join时,首先对右端的表进行一次采样,对采样的数据创建索引,记录(key, 文件名, 偏移[offset])。然后进行map,读取Join左边的表,对于每一条数据记录,根据前一步计算好的索引来查找数据,进行Join。
可以在Join时使用Using 'merge'语句来触发Merge Join,需要创建索引的表放置在右端。
另外,在进行Join之前,首先过滤掉key为Null的数据记录可以减少Join的数据量。
11、Limit:
只取几条数据查看
data = load 'inut'; first10 = limit data 10;
12、Sample:
用于抽样样本数据,会读取所有的数据然后返回一定百分比的行数的数据。
data = load 'inut'; sample_data = sample data 0.1;
13、Parallel:
附加到任一个关系操作符后面,控制reduce 阶段的并行。
data = load 'inut' as (a,b,c); bya =group data by a parallel 10; -- 触发Mapreduce任务具有10个reducer。
14、flatten:
降低bag或tuple嵌套级别。
15、自定义函数UDF:
注册非pig内置的UDF:REGISTER '…….jar‘;
define命令和UDF:define命令可用于为用户的Java UDF定义一个别名,这样用户就不需要写那么冗长的包名全路径了,它也可以为用户的UDF的构造函数提供参数。
set:在pig脚本前面加上set ***; 这个命令可在Pig脚本的开头来设置job的参数;
三、例子:
1、group使用
data.txt文件内容:
1,2,6
3,4,5
5,6,2
1,4,2
3,1,3
>> data = load 'data.txt' using PigStorage(',') as (a:int,b:int,c:int);
>> describe data; [describe速度快,不需要去执行代码]
data: {a: int,b: int,c: int}
1、使用三目运算符来替换空值
B = FOREACH A GENERATE ((col1 is null) ? -1 :col1)
-- 替换bag空值, 其中col1为bag,类型为{(int),(int)}
C = FOREACH A GENERATE ((col1 is null or IsEmpty(col1)) ? {(0)} :col1;
2、外连接JOIN:
LEFT:左边的数据全量显示
A = LOAD '1.txt' USING PigStorage(' ') AS (col1:int , col2:chararray); B = LOAD '2.txt' USING PigStorage(' ') AS ( col1:int , col2:chararray); C = JOIN A BY col1 LEFT , B BY col1; DESCRIBE C; DUMP C;
3、合并文件A和B的数据:
A = LOAD 'A.txt'; B = LOAD 'B.txt'; C = UNION A,B; DUMP C;
4、表示文件的第一个字段(第一列):$0;
5、pig统计文件的词频:TOKENIZE
-- 统计数据的行数 cd hdfs:/// A = LOAD '/logdata/2012*/*/nohup_*' AS (name:chararray) ; B = GROUP A BY name; C = FOREACH B GENERATE group, COUNT(A); D = ORDER C BY ($1); E = FILTER D BY $1 > 200; dump E; -- 统计单词的个数 A = LOAD'/logdata/20130131/*/*' AS (line: chararray) ; B = foreach A generate flatten(TOKENIZE((chararray)$0)) as word; C = group B by word; D = foreach C generate COUNT(B), group; E = ORDER D BY ($0); F = FILTER E BY $0> 200; DUMP F;
TOKENIZE函数:https://www.w3cschool.cn/apache_pig/apache_pig_tokenize.html
flatten函数:https://blog.csdn.net/iteye_20817/java/article/details/82545911
flatten在英文的意思弄平整的意思,这个操作符在不同的场景有不同的功能。
1. flatten tuple
flatten会把tuple内容打开,下面举例:
-- A结构:(a, (b, c))
B = foreach A GENERATE $0, flatten($1)
B返回结果(a,b,c)
2. flatten bag
flatten会把bag内容打开,每个tuple是一行,即列转换为行
-- A结构:({(b,c),(d,e)})
B = foreach A generate flatten($0)
B返回结果
(b,c)
(d,e)
举例子:
1.txt;
i am hadoop
i am hadoop
i am lucene
i am hbase
i am hive
i am hive sql
i am pig
pig代码:
--load文本的txt数据,并把每行作为一个文本 a = load '1.txt' as (f1:chararray); --将每行数据,按指定的分隔符(这里使用的是空格)进行分割,并转为扁平结构 b = foreach a generate flatten(TOKENIZE(f1, ' ')); --对单词分组 c = group b by $0; --统计每个单词出现的次数 d = foreach c generate group ,COUNT($1); --存储结果数据 stroe d into '$out'
##注意,COUNT函数一定要大写,不然会报错: ERROR org.apache.pig.PigServer- exception during parsing:Error during parsing. Could not resolve count using imports:[, java.lang., org.apache.pig.builtin., org.apache.pig.impl.builtin.]
处理的结果:
(i,7) (am,7) (pig,1) (sql,1) (hive,2) (hbase,1) (hadoop,2) (lucene,1)
取topN功能:
-- 按统计次数降序 e = order d by $1 desc; --取top2 f = limit e 2; --存储结果数据 stroe f into '$out'
6、pig嵌套循环
https://blog.csdn.net/jameshadoop/article/details/24838915
7、pig传参
A = LOAD '$INPUT_DIR' AS (t0:long, msisdn:chararray, t2:chararray, t3:chararray, t4:chararray,t5:chararray, t6:long, t7:long, t8:long, t9:long, t10:chararray);
B = FOREACH A GENERATE msisdn, t6, t7, t8, t9;
C = GROUP B BY msisdn;
D = FOREACH C GENERATE group, SUM(B.t6), SUM(B.t7), SUM(B.t8), SUM(B.t9);
STORE D INTO '$OUTPUT_DIR';
pig -p INPUT_DIR=hdfs://mycluster/pig/in -p OUTPUT_DIR=hdfs://mycluster/pig/out ./schedule.pig
---------------------
原文:https://blog.csdn.net/aaronhadoop/article/details/44310633
PIG 命令行传多个参数
PIG 命令行执行脚本,多个参数传递问题终于解决了,实例如下:
pig -p startdate=2011-03-21 -p enddate=2011-03-28 script.pig
这样就可以实现多个参数传递的例子,但其中,如果参数值中存在空格,则会报错,
原文:https://blog.csdn.net/iteye_19679/article/details/82580903
8、两列相除:
# 两个整数相除,如何得到一个float A = LOAD '16.txt' AS (col1:int, col2:int); B = FOREACH A GENERATE (float)col1/col2; DUMP B; # 注意先转型在计算,而不是(float)(col1/col2);
9、filter正则匹配:
https://www.cnblogs.com/lishouguang/p/4559300.html
1)等值比较 filter data by $0 == 1 filter data by $0 != 1 2)字符串 正则匹配 JAVA的正则表达式 字符串以CM开头 filter data by $0 matches 'CM.*'; 字符串包含CM filter data by $0 matches '.*CM.*'; 3)not filter data by not $0==1; filter data by not $0 matches '.*CM.*'; 4)NULL处理 filter data by $0 is not null; 5)UDF filter data by isValidate($0); 6)and or filter data by $0!=1 and $1>10
10、修改Pig作业执行的queue
作业提交到的队列:mapreduce.job.queuename
作业优先级:mapreduce.job.priority,优先级默认有5个:LOW VERY_LOW NORMAL(默认) HIGH VERY_HIGH
1、静态设置
1.1 Pig版本
SET mapreduce.job.queuename root.etl.distcp;
SET mapreduce.job.priority HIGH;
---------------------
作者:wisgood 来源:CSDN
原文:https://blog.csdn.net/wisgood/article/details/39075883
https://my.oschina.net/crxy/blog/420227?p=1
|
1
2
3
|
a = load 'input1';b = load 'input2';jnd = join a by $0, b by $1; |
|
1
2
3
|
a = load 'input1' as (username, age, city);b = load 'input2' as (orderid, user, city);jnd = join a by (username, city), b by (user, city); |
|
1
2
3
4
|
a = load 'input1' as (username, age, address);b = load 'input2' as (orderid, user, money;jnd = join a by username, b by user;result = foreach jnd generate a::username, a::age, address, b::orderid; |
|
1
2
3
4
|
a = load 'input1' as (username, age);b = load 'input2' as (orderid, user);c = load 'input3' as (user, acount);jnd = join a by username, b by user, c by user; |
|
1
2
3
4
5
|
a = load 'input1' as (username, age);b = load 'input2' as (orderid, user);jnd = join a by username left outer, b by user;jnd = join a by username right, b by user;jnd = join a by username full, b by user; |
|
1
2
3
|
a = load 'data' as (node, parentid, name);b = load 'data' as (node, parentid, name);jnd = join a by node, b by parentid; |