一、使用Numpy初始化:【直接对Tensor操作】
-
对Sequential模型的参数进行修改:
1 import numpy as np 2 import torch 3 from torch import nn 4 5 # 定义一个 Sequential 模型 6 net1 = nn.Sequential( 7 nn.Linear(30, 40), 8 nn.ReLU(), 9 nn.Linear(40, 50), 10 nn.ReLU(), 11 nn.Linear(50, 10) 12 ) 13 14 # 访问第一层的参数 15 w1 = net1[0].weight 16 b1 = net1[0].bias 17 print(w1) 18 19 #对第一层Linear的参数进行修改: 20 # 定义第一层的参数 Tensor 直接对其进行替换 21 net1[0].weight.data = torch.from_numpy(np.random.uniform(3, 5, size=(40, 30))) 22 print(net1[0].weight)
23
24 #若模型中相同类型的层都需要初始化成相同的方式,一种更高效的方式:使用循环去访问:
25 for layer in net1:
26 if isinstance(layer, nn.Linear): # 判断是否是线性层
27 param_shape = layer.weight.shape
28 layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape))
29 # 定义为均值为 0,方差为 0.5 的正态分布
-
对Module模型 的参数初始化:
对于 Module 的参数初始化,其实也非常简单,如果想对其中的某层进行初始化,可以直接像 Sequential 一样对其 Tensor 进行重新定义,其唯一不同的地方在于,如果要用循环的方式访问,需要介绍两个属性,children 和 modules,下面我们举例来说明:
1、创建Module模型类:


1 class sim_net(nn.Module): 2 def __init__(self): 3 super(sim_net, self).__init__() 4 self.l1 = nn.Sequential( 5 nn.Linear(30, 40), 6 nn.ReLU() 7 ) 8 9 self.l1[0].weight.data = torch.randn(40, 30) # 直接对某一层初始化 10 11 self.l2 = nn.Sequential( 12 nn.Linear(40, 50), 13 nn.ReLU() 14 ) 15 16 self.l3 = nn.Sequential( 17 nn.Linear(50, 10), 18 nn.ReLU() 19 ) 20 21 def forward(self, x): 22 x = self.l1(x) 23 x =self.l2(x) 24 x = self.l3(x) 25 return x
2、创建模型对象:
net2 = sim_net()
3、访问children:
# 访问 children for i in net2.children(): print(i)
#打印的结果:
4、访问modules:
# 访问 modules for i in net2.modules(): print(i) #打印的结果 sim_net( (l1): Sequential( (0): Linear(in_features=30, out_features=40) (1): ReLU() ) (l2): Sequential( (0): Linear(in_features=40, out_features=50) (1): ReLU() ) (l3): Sequential( (0): Linear(in_features=50, out_features=10) (1): ReLU() ) ) Sequential( (0): Linear(in_features=30, out_features=40) (1): ReLU() ) Linear(in_features=30, out_features=40) ReLU() Sequential( (0): Linear(in_features=40, out_features=50) (1): ReLU() ) Linear(in_features=40, out_features=50) ReLU() Sequential( (0): Linear(in_features=50, out_features=10) (1): ReLU() ) Linear(in_features=50, out_features=10) ReLU()
通过上面的例子,可以看到:
children 只会访问到模型定义中的第一层,因为上面的模型中定义了三个 Sequential,所以只会访问到三个 Sequential,而 modules 会访问到最后的结构,比如上面的例子,modules 不仅访问到了 Sequential,也访问到了 Sequential 里面,这就对我们做初始化非常方便。
5、采用循环初始化:
for layer in net2.modules(): if isinstance(layer, nn.Linear): param_shape = layer.weight.shape layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape))
二、torch.nn.init初始化
PyTorch 还提供了初始化的函数帮助我们快速初始化,就是 torch.nn.init,其操作层面仍然在 Tensor 上。先介绍一种初始化方法:
Xavier 初始化方法:
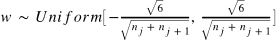
其中 和
表示该层的输入和输出数目。
这种非常流行的初始化方式叫 Xavier,方法来源于 2010 年的一篇论文 Understanding the difficulty of training deep feedforward neural networks,其通过数学的推到,证明了这种初始化方式可以使得每一层的输出方差是尽可能相等的。
torch.nn.init:
from torch.nn import init init.xavier_uniform(net1[0].weight) # 这就是上面我们讲过的 Xavier 初始化方法,PyTorch 直接内置了其实现 #这就直接修改了net1[0].weight的值