一、为什么选择序列模型
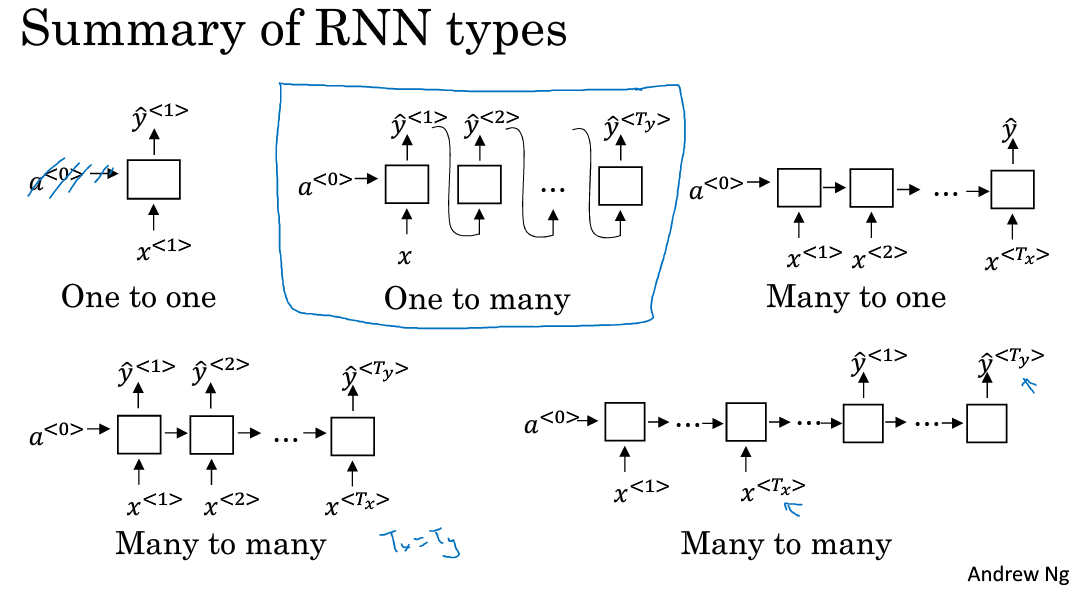
(1)序列模型广泛应用于语音识别【多对多】,音乐生成【一对多】,情感分析【多对一】,DNA序列分析,机器翻译【多对多,个数不同】,视频行为识别,命名实体识别等众多领域。
(2)上面那些问题可以看成使用(x,y)作为训练集的监督学习,但是输入与输出的对应关系有非常多的组合,比如一对一,一对多,多对一,多对多,多对多(个数不同)等情况来针对不同的应用。
二、循环神经网络模型(RNN)
(1)模型结构
第一次输入会通过激活值影响下一个输入的预测,从而影响接下去的所有输入的预测,这就是循环神经网络。

(2)前向传播
- 数学式子如下所示:
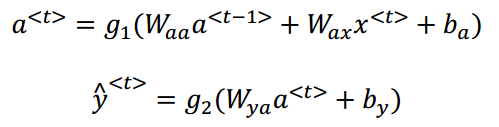
将Waa和Wax合并在一起:
![]()
![]()
- 得到最终形式:
![]()
![]()
(3)时间反向传播【BP through time:RNN的反向传播】
- 一个元素的代价函数(一个0,1二分类问题,注意下面式子中应该是(1-y<t>)):
![]()
- 每一个样本的代价函数:
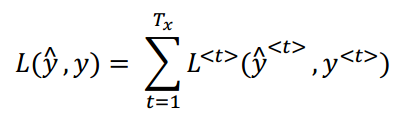
(4)RNN存在的问题:梯度消失和梯度爆炸
梯度爆炸问题易解决:
一个解决方式就是梯度修剪。观察你的梯度向量,一旦发现超过某个阀值,就缩放梯度向量,保证他不会太大。比如通过一些最大值来修剪的方法。
梯度消失的问题:GRU可解决
假设有两个训练样本,句子的长度非常长:
The cat, with already ate…………, was full.
The cats, with already ate…………, where full.
第一个句子的was是依赖于cat, 第二个were是依赖于cats,但是这两个单词被隔得非常远,以至于后者的单词很难依赖于前者得到。
因为,与传统的深层神经网络类似,经过前向传播之后,反向传播中后面的y<t>误差很难通过梯度影响到前面层的计算,因此当RNN在计算后面的单词was还是were的时候,对前面出现过的cat或cats已经忘得差不多了。
也因此,其实每次的输出y<t>只能反向传播影响到前面附近的几层计算,也就是说,在训练时无论y<t>只能反向传播影响到前面附近的几层计算,也就是说,在训练时无论y^{}的预测是正确的还是错误的,或者说损失是大是小,都无法通过反向传播告诉很前面的层,并且对前面的层有效调整权重。
三、语言模型【Language model 】
(1)语言模型:
1、是什么?
比如语音识别成文字中的两句话【读音一样】,选择正确的句子需用到语言模型:
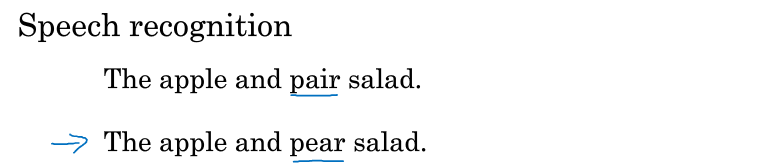
采用语言模型识别两句话的概率,根据最大概率来选择正确的句子。
(2)怎么用RNN建立语言模型?
- 利用语料库做训练集,然后对语料库进行标记化,【如每个句子结尾做结尾标记,没出现在预料库中的单词做未知标记,标点符号需不需要】,然后进行one-hot处理每个词。
- 建立RNN
- 语言模型如下图所示,首先第一个输出是在无任何提示下输出各个词的概率,第二个输出是在给定第一个输出标签时各个词(10002个词)输出的概率,以此类推,每一个输出都是在给定条件下一个输出各个单词的概率。

- 训练网络时,上图中序号8和9分别代表了一个元素和一个样本的代价函数,代价函数使用的是交叉熵。
-
在使用网络时,现在有一个包含三个词(y<1>,y<2>,y<3>)的句子,这时网络没有任何信息的条件下求是y<1>的概率,然后计算在给定y<1>条件下y<2>的概率,最后在给定y<1>,y<2>条件下y<3>的概率。最后可以确定,输出是这个句子的概率如下图所示,回到最初的两个句子,可以分别求两个句子的概率,取概率最大的句子即可:
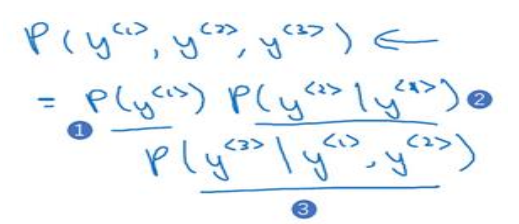
四、对新序列采样
基于词汇进行采样:
在训练完一个模型之后你想要知道模型学到了什么,一种非正式的方法就是进行一次新序列采样:一个序列模型模拟了任意特定单词序列的概率,对新序列采样即是对概率分布进行采样来生成一个新的单词序列。具体方法如下:
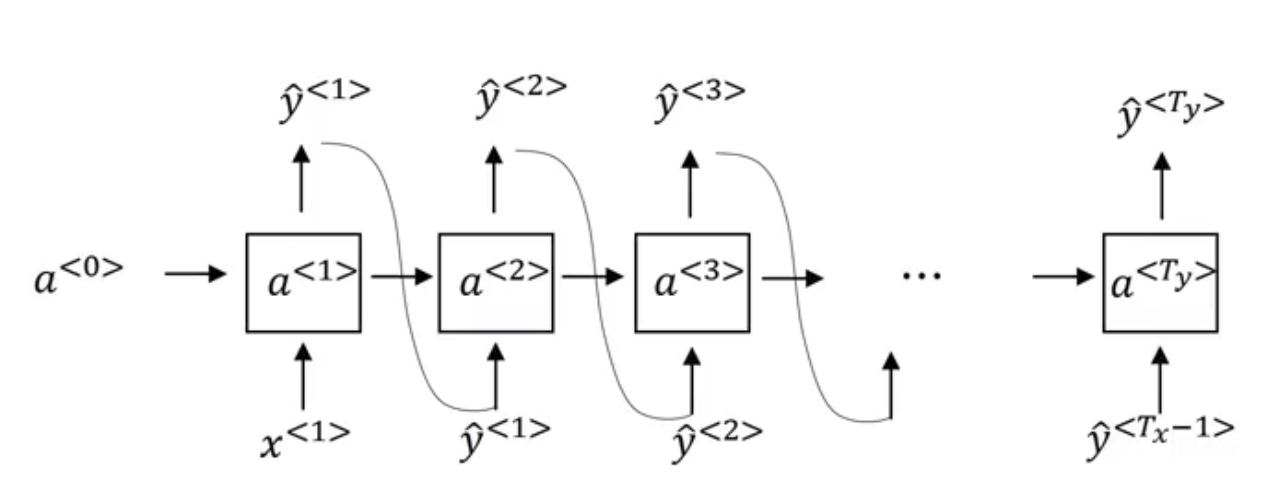
- 一、时刻t=1,输入初始化的x<1>=0,a<0>=0。
- 二、在每一步输出y^时,通过softmax 输出的一个词典大小的概率分布分布,对这个向量进行采样,随机采出一个词作为输出(非取最大概率),也就是对应的一个字或者英文单词。
- 三、将这个值作为下一个单元的x输入进去(即x<t>=y^<t−1>, 直到我们输出了终结符,或者输出长度超过了提前的预设值n才停止采样。.
(可能会采样出标识的字符,若是不想它出现,继续重新采样另一个词。)
上述步骤如下:
下图给出了采样之后得到的效果:
左边是对训练得到新闻信息模型进行采样得到的内容;
右边是莎士比亚模型采样得到的内容。
