一、VGGNet:5段卷积【每段有2~3个卷积层+最大池化层】【每段过滤器个数:64-128-256-512-512】
每段的2~3个卷积层串联在一起的作用:
2个3×3的卷积层串联的效果相当于一个5×5的卷积层,即一个像素会跟周围5×5的像素产生关联。【28*28的输入经过一次5*5得到24*24,s=1,p=0,(28-5)/1 + 1 = 24。而28*28经过2个3*3也可以得到24*24.】
3个3×3的卷积层串联的效果相当于一个7×7的卷积层,
- 好处一:3个3×3的卷积层串联拥有的餐数量比1个7×7的参数量少。只是后者的:(3×3×3)/ (7 × 7) = 55 %。
- 好处二:3个3×3的卷积层拥有比1个7×7的卷积层更多的线性变换(如,前者可以使用三次Relu函数,后者只有一次),使得CNN对特征的学习能力更强。
VGG探索了卷积神经网络的深度与其性能之间的关系,反复堆叠3×3的小型卷积核和2×2的最大池化层,构筑了16~19层深度的卷积神经网络。
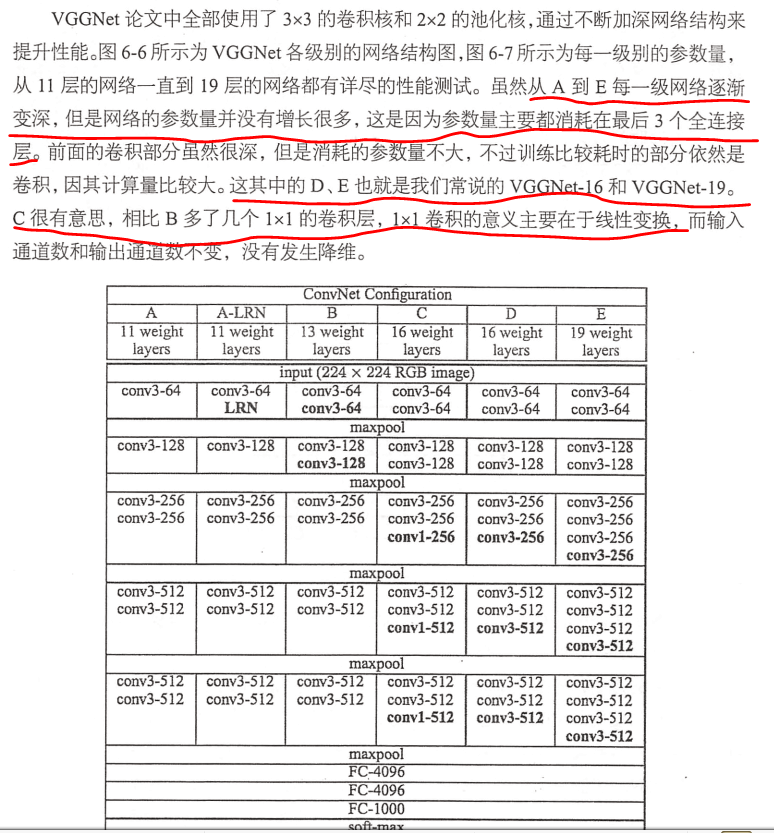

二、VGG训练的技巧:
- 先训练级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样训练收敛的速度更快。
- 在预测时,VGG采用Multi-Scale的方法,将图像scale到一个尺寸Q,并将图片输入卷积网络计算。然后在最后一个卷积层使用滑窗的方式进行分类预测,将不同窗口的分类结果平均,再将不同尺寸Q的结果平均得到最后结果。提高数据利用率和预测准确率
- 采用了Multi-scale做数据增强,防止过拟合
三、代码:
#加载模块 from datetime import datetime import math import time import tensorflow as tf #定义函数:卷积层、池化层、全连接层 #conv_op用来创建卷积层 def conv_op(input_op , name ,kh , kw , n_out, dh ,dw , p): n_in = input_op.get_shape()[-1].value with tf.name_scope(name) as scope: w = tf.get_variable(scope+'w',shape = [kh,kw,n_in,n_out], dtype = tf.float32 , initializer=tf.contrib.layers.xavier_initializer_conv2d()) conv = tf.nn.conv2d(input_op,w,strides = [1,dh,dw,1],padding = 'SAME') b = tf.Variable(tf.constant(0.0,shape = [n_out] , dtype = tf.float32),trainable = True , name = 'b') z = tf.nn.bias_add(conv,b) activation = tf.nn.relu(z,name = scope) p+=[w,b] return activation #用来创建全连接层 def fc_op(input_op,name,n_out,p): n_in = input_op.get_shape()[-1].value with tf.name_scope(name) as scope: w = tf.get_variable(scope+'w',shape = [n_in,n_out],dtype = tf.float32, initializer= tf.contrib.layers.xavier_initializer()) b = tf.Variable(tf.constant(0.1,shape = [n_out],dtype = tf.float32),name = 'b') activation = tf.nn.relu_layer(input_op,w,b,name = scope) p += [w,b] return activation #用来创建池化层 def mpool_op(input_op,name,kh,kw,dh,dw): return tf.nn.max_pool(input_op,ksize = [1,kh,kw,1],strides = [1,dh,dw,1],padding = 'SAME',name = name) #建立VGG模型 def inference_op(input_op,keep_prob): p=[] conv1_1=conv_op(input_op,name="conv1_1",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p) conv1_2=conv_op(conv1_1,name="conv1_2",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p) pool1=mpool_op(conv1_2,name="pool1",kh=2,kw=2,dw=2,dh=2) conv2_1=conv_op(pool1,name="conv2_1",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p) conv2_2=conv_op(conv2_1,name="conv2_2",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p) pool2=mpool_op(conv2_2,name="pool2",kh=2,kw=2,dw=2,dh=2) conv3_1=conv_op(pool2,name="conv3_1",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p) conv3_2=conv_op(conv3_1,name="conv3_2",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p) conv3_3=conv_op(conv3_2,name="conv3_3",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p) pool3=mpool_op(conv3_3,name="pool3",kh=2,kw=2,dw=2,dh=2) conv4_1=conv_op(pool3,name="conv4_1",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) conv4_2=conv_op(conv4_1,name="conv4_2",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) conv4_3=conv_op(conv4_2,name="conv4_3",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) pool4=mpool_op(conv4_3,name="pool4",kh=2,kw=2,dw=2,dh=2) conv5_1=conv_op(pool4,name="conv5_1",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) conv5_2=conv_op(conv5_1,name="conv5_2",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) conv5_3=conv_op(conv5_2,name="conv5_3",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p) pool5=mpool_op(conv5_3,name="pool5",kh=2,kw=2,dw=2,dh=2) shp=pool5.get_shape() flattened_shape=shp[1].value*shp[2].value*shp[3].value resh1=tf.reshape(pool5,[-1,flattened_shape],name="resh1") fc6=fc_op(resh1,name="fc6",n_out=4096,p=p) fc6_drop=tf.nn.dropout(fc6,keep_prob,name="fc6_drop") fc7=fc_op(fc6_drop,name="fc7",n_out=4096,p=p) fc7_drop=tf.nn.dropout(fc7,keep_prob,name="fc7_drop") fc8=fc_op(fc7_drop,name="fc8",n_out=1000,p=p) softmax=tf.nn.softmax(fc8) predictions=tf.argmax(softmax,1) return predictions,softmax,fc8,p #时间差 def time_tensorflow_run(session,target,feed,info_string): num_steps_burn_in=10 total_duration=0.0 total_duration_squared=0.0 for i in range(num_batches+num_steps_burn_in): start_time=time.time() _=session.run(target,feed_dict=feed) duration=time.time()-start_time if i>=num_steps_burn_in: if not i%10: print('%s:step %d,duration=%.3f' % (datetime.now(),i-num_steps_burn_in,duration)) total_duration+=duration total_duration_squared+=duration*duration mn=total_duration/num_batches vr=total_duration_squared/num_batches-mn*mn sd=math.sqrt(vr) print('%s:%s across %d steps,%.3f +/- %.3f sec / batch' % (datetime.now(),info_string,num_batches,mn,sd)) #预测 def run_benchmark(): with tf.Graph().as_default(): image_size=224 images=tf.Variable(tf.random_normal([batch_size,image_size,image_size,3],dtype=tf.float32,stddev=1e-1)) keep_prob=tf.placeholder(tf.float32) predictions,softmax,fc8,p=inference_op(images,keep_prob) init=tf.global_variables_initializer() sess=tf.Session() sess.run(init) time_tensorflow_run(sess,predictions,{keep_prob:1.0},"Forward") objective=tf.nn.l2_loss(fc8) grad=tf.gradients(objective,p) time_tensorflow_run(sess,grad,{keep_prob:0.5},"Forward-backward") #训练 batch_size=32 num_batches=100 run_benchmark()